Apache Hudi is a data lake framework that allows you to insert, update, and delete data. Typically, this framework is used to build cost-effective data lakehouses based on Object Storage Service (OSS). Apache Hudi supports multiple versions of file management protocols and provides capabilities for data ingestion and analysis, such as real-time incremental data writing, transaction atomicity, consistency, isolation, and durability (ACID), and automatic merging and optimization of small files. In addition, Apache Hudi can implement metadata verification and schema evolution, support high-efficiency column analysis formats and index optimization, and store super-large partitioned tables.
The AnalyticDB for MySQL team builds a cost-effective data lakehouse solution that is fully compatible with the open source Hudi ecosystem based on Apache Hudi. After you create an AnalyticDB for MySQL cluster, you can configure simple settings to build data lakehouses based on OSS and Hudi. For example, you can use AnalyticDB Pipeline Service (APS) to ingest log data from Kafka or Log Service to data lakehouses in near real time, or use the AnalyticDB for MySQL Serverless Spark engine to ingest data from ApsaraDB RDS or Parquet to data lakehouses in batches. The following figure shows the architecture of the data lakehouse solution that is provided by AnalyticDB for MySQL.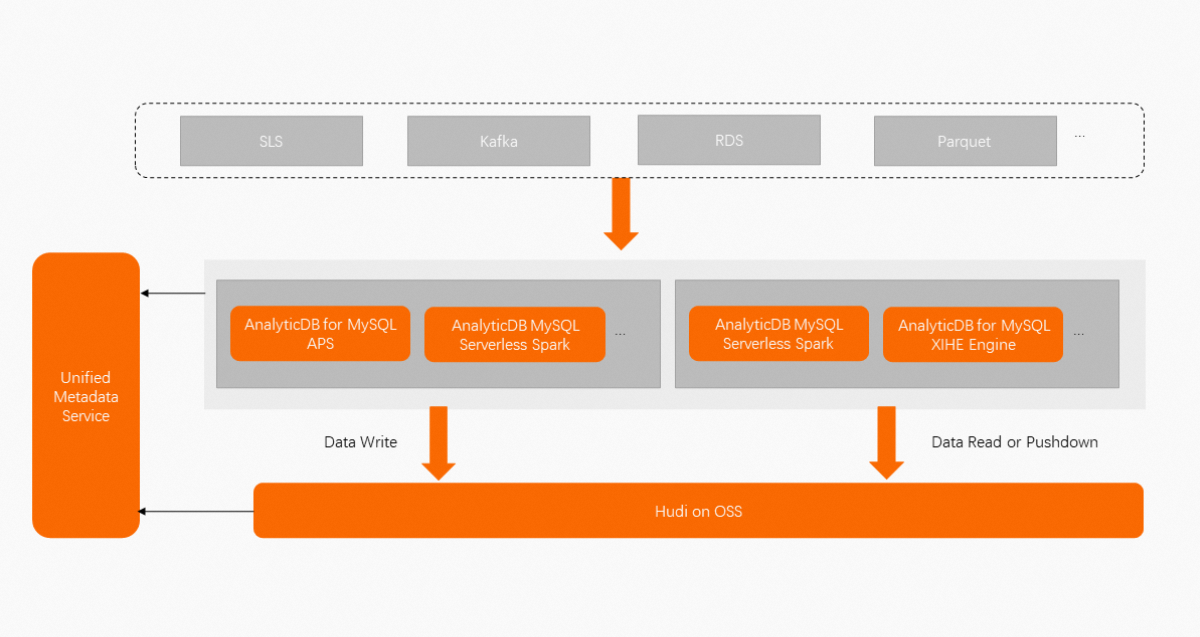
AnalyticDB for MySQL is deeply integrated with Apache Hudi and makes in-depth improvements to the Hudi kernel. Compared with the open source Hudi solution, the data lakehouse solution that is provided by AnalyticDB for MySQL has the following advantages:
Ease of use
You can easily write data to Hudi after you perform APS configurations on a GUI. AnalyticDB for MySQL provides this solution out of the box by working with Hudi to get rid of complex Spark configurations.
High-performance writing
This solution makes in-depth improvements to OSS-based writing. In most logging scenarios, this solution provides more than twice the OSS write performance compared with the open source Hudi solution. Hot data can be automatically distributed in an even manner to resolve data skew issues and significantly improve write stability.
Partitioned lifecycle management
You can manage the lifecycle of partition data based on multiple dimensions such as the number of partitions, data volume, and expiration time. You can concurrently configure multiple lifecycle management policies to further reduce storage costs.
Support for table services
This solution supports asynchronous table services that are completely isolated from the write link. Asynchronous table services such as clustering can improve query performance by up to more than 40% in most scenarios.
Automatic metadata synchronization
AnalyticDB for MySQL provides centralized metadata management. After data is written to Hudi, you can access the data by using AnalyticDB for MySQL Serverless Spark and XIHE engines without the need to manually synchronize the table metadata. You can access one copy of ingested data by using multiple compute engines.