You can use the Gateway with Inference Extension component to replace or upgrade foundation models or perform phased updates for multiple LoRA models in your generative AI inference service. This approach minimizes service interruptions. This topic describes how to use the Gateway with Inference Extension component to implement progressive phased releases for generative AI inference services.
Before you begin, make sure you understand the concepts of InferencePool and InferenceModel.
Prerequisites
-
You have an ACK managed cluster with a GPU node pool. You can also install the ACK Virtual Node component in the ACK managed cluster to use ACS GPU computing power.
-
You have installed the Gateway with Inference Extension component and selected the Enable Gateway API Inference Extension option. For instructions, see Install components.
Preparations
Before you demonstrate the progressive phased release of the inference service, deploy and validate the sample inference service.
-
You can deploy a sample inference service based on the Qwen-2.5-7B-Instruct foundation model.
-
You can deploy the InferencePool and InferenceModel resources.
kubectl apply -f- <<EOF apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferencePool metadata: name: mymodel-pool-v1 namespace: default spec: extensionRef: group: "" kind: Service name: mymodel-v1-ext-proc selector: app: custom-serving release: qwen targetPortNumber: 8000 --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceModel metadata: name: mymodel-v1 spec: criticality: Critical modelName: mymodel poolRef: group: inference.networking.x-k8s.io kind: InferencePool name: mymodel-pool-v1 targetModels: - name: mymodel weight: 100 EOF -
You can deploy the gateway and gateway routing rules.
-
You can obtain the gateway IP address.
export GATEWAY_IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') -
You can validate the inference service.
curl -X POST ${GATEWAY_IP}:8080/v1/chat/completions -H 'Content-Type: application/json' -d '{ "model": "mymodel", "temperature": 0, "messages": [ { "role": "user", "content": "Who are you?" } ] }'Expected output:
{"id":"chatcmpl-6bd37f84-55e0-4278-8f16-7b7bf04c6513","object":"chat.completion","created":1744364930,"model":"mymodel","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"I am Qwen, a large language model created by Alibaba Cloud. I am designed to assist with a wide range of tasks, from answering questions and providing information to helping with creative projects and more. How can I assist you today?","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":32,"total_tokens":74,"completion_tokens":42,"prompt_tokens_details":null},"prompt_logprobs":null}The expected output indicates that the inference service is functioning as expected through Gateway with Inference Extension.
Scenario 1: Use InferencePool updates for phased releases of infrastructure and foundation models
In a real-world scenario, you can update an InferencePool to implement a phased release for a model service. For example, you can configure two InferencePools based on the same InferenceModel definition and model name, but run them on different computing configurations, GPU card types, or foundation models. This method applies to the following scenarios.
-
Phased infrastructure updates: Create a new InferencePool that uses a new GPU card type or a new model configuration. Gradually migrate the workload in phases. This lets you upgrade node hardware, update drivers, or resolve security issues without interrupting inference request traffic.
-
Phased foundation model updates: Create a new InferencePool to load a new model architecture or fine-tuned model weights. Gradually release the new inference model in phases to improve inference service performance or resolve issues related to the foundation model.
The following describes the main flow of a grayscale update.

You can create a new InferencePool for the new foundation model and configure an HTTPRoute to allocate traffic between different InferencePools. This lets you gradually shift traffic to the new foundation model's inference service, represented by the new InferencePool, to achieve a zero-interruption update. The following example demonstrates how to perform a phased update from the deployed Qwen-2.5-7B-Instruct foundation model service to the DeepSeek-R1-Distill-Qwen-7B service. You can update the traffic ratio in the HTTPRoute to achieve a complete switch of the foundation model.
-
You can deploy the inference service based on the DeepSeek-R1-Distill-Qwen-7B foundation model.
-
You can configure the InferencePool and InferenceModel for the new inference service. The InferencePool
mymodel-pool-v2uses a new label to select the inference service based on the DeepSeek-R1-Distill-Qwen-7B foundation model. It also declares an InferenceModel with the same model name:mymodel.kubectl apply -f- <<EOF apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferencePool metadata: name: mymodel-pool-v2 namespace: default spec: extensionRef: group: "" kind: Service name: mymodel-v2-ext-proc selector: app: custom-serving release: deepseek-r1 targetPortNumber: 8000 --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceModel metadata: name: mymodel-v2 spec: criticality: Critical modelName: mymodel poolRef: group: inference.networking.x-k8s.io kind: InferencePool name: mymodel-pool-v2 targetModels: - name: mymodel weight: 100 EOF -
You can configure the traffic splitting policy.
You can configure the HTTPRoute to split traffic between the existing InferencePool (
mymodel-pool-v1) and the new InferencePool (mymodel-pool-v2). The `weight` field inbackendRefscontrols the percentage of traffic allocated to each InferencePool. For example, this sets the model traffic weight to 9:1. This forwards 10% of the traffic to the DeepSeek-R1-Distill-Qwen-7B foundation service, which corresponds tomymodel-pool-v2.kubectl apply -f- <<EOF apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: inference-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway sectionName: llm-gw rules: - backendRefs: - group: inference.networking.x-k8s.io kind: InferencePool name: mymodel-pool-v1 port: 8000 weight: 90 - group: inference.networking.x-k8s.io kind: InferencePool name: mymodel-pool-v2 weight: 10 matches: - path: type: PathPrefix value: / EOF -
You can validate the phased release of the foundation model.
You can repeatedly run the following command and check the model output to validate the phased release of the foundation model:
curl -X POST ${GATEWAY_IP}:8080/v1/chat/completions -H 'Content-Type: application/json' -d '{ "model": "mymodel", "temperature": 0, "messages": [ { "role": "user", "content": "Who are you?" } ] }'Expected output for most requests:
{"id":"chatcmpl-6e361a5e-b0cb-4b57-8994-a293c5a9a6ad","object":"chat.completion","created":1744601277,"model":"mymodel","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"I am Qwen, a large language model created by Alibaba Cloud. I am designed to assist with a wide range of tasks, from answering questions and providing information to helping with creative projects and more. How can I assist you today?","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":32,"total_tokens":74,"completion_tokens":42,"prompt_tokens_details":null},"prompt_logprobs":null}Expected output for about 10% of requests:
{"id":"chatcmpl-9e3cda6e-b284-43a9-9625-2e8fcd1fe0c7","object":"chat.completion","created":1744601333,"model":"mymodel","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"Hello! I am DeepSeek-R1, an intelligent assistant developed by DeepSeek, a company based in China. If you have any questions, I will do my best to assist you.\n</think>\n\nHello! I am DeepSeek-R1, an intelligent assistant developed by DeepSeek, a company based in China. If you have any questions, I will do my best to assist you.","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":8,"total_tokens":81,"completion_tokens":73,"prompt_tokens_details":null},"prompt_logprobs":null}Most inference requests are still served by the legacy Qwen-2.5-7B-Instruct foundation model, while a small portion are served by the new DeepSeek-R1-Distill-Qwen-7B foundation model.
Scenario 2: Use InferenceModel configurations for phased releases of LoRA models
In a Multi-LoRA scenario, you can use Gateway with Inference Extension to deploy multiple versions of a LoRA model on the same foundation Large Language Model (LLM). You can flexibly allocate traffic for phased testing to validate the effects of each version on performance optimization, bug fixes, or feature iterations.
This example uses two LoRA versions fine-tuned from Qwen-2.5-7B-Instruct to describe how to implement a phased release for LoRA models using an InferenceModel.
Before you implement the phased release for the LoRA models, ensure that the new model version is successfully deployed to the inference service instance. The foundation service in this example has already mounted two LoRA models:travel-helper-v1andtravel-helper-v2.
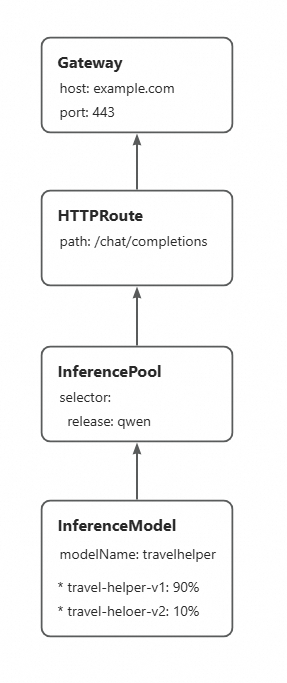
By updating the traffic ratio between different LoRA models in the InferenceModel, you can gradually increase the traffic weight of the new LoRA model version. This allows for a progressive update to the new LoRA model without interrupting traffic.
-
You can deploy an InferenceModel configuration to define multiple versions of the LoRA model and specify the traffic ratio between them. After the configuration is complete, when a request is made to the `travelhelper` model, traffic is split between the backend LoRA model versions. For example, the ratio is set to 9:1. This means 90% of the traffic is sent to the
travel-helper-v1model, and 10% is sent to thetravel-helper-v2model.kubectl apply -f- <<EOF apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceModel metadata: name: loramodel spec: criticality: Critical modelName: travelhelper poolRef: group: inference.networking.x-k8s.io kind: InferencePool name: mymodel-pool-v1 targetModels: - name: travel-helper-v1 weight: 90 - name: travel-helper-v2 weight: 10 EOF -
You can validate the phased release.
You can repeatedly run the following command and check the model output to validate the phased release of the LoRA model:
curl -X POST ${GATEWAY_IP}:8080/v1/chat/completions -H 'Content-Type: application/json' -d '{ "model": "travelhelper", "temperature": 0, "messages": [ { "role": "user", "content": "I just arrived in Beijing. Can you recommend a tourist spot?" } ] }'Expected output for most requests:
{"id":"chatcmpl-2343f2ec-b03f-4882-a601-aca9e88d45ef","object":"chat.completion","created":1744602234,"model":"travel-helper-v1","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"Beijing is a city rich in history and culture, with many attractions worth visiting. Here are some recommended attractions:\n\n1. The Forbidden City: This is the largest ancient imperial palace in China and one of the largest ancient timber-frame architectural complexes in the world. You can learn about ancient Chinese imperial life and history here.\n\n2. The Great Wall: The section of the Great Wall near Beijing is among the most famous. You can admire magnificent mountain scenery and the grandeur of the Great Wall here.\n\n3. Tian'anmen Square: This is the largest city square in the world. You can see the Tian'anmen Rostrum and the Monument to the People's Heroes here.\n\n4. The Summer Palace: This is the largest royal garden in China. You can enjoy beautiful lakes and mountain views, along with exquisite architecture and sculptures.\n\n5. Beijing Zoo: If you love animals, this zoo houses many species, including giant pandas and golden snub-nosed monkeys.\n\n6. 798 Art Zone: This is an artistic district filled with galleries, art studios, and cafés, where you can view diverse artworks.\n\n7. 751 D-Park: This is a creative park integrating art, culture, and technology, where you can experience various exhibitions and events.\n\nHere are the Beijing attractions I recommend for you. I hope you enjoy them.","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":38,"total_tokens":288,"completion_tokens":250,"prompt_tokens_details":null},"prompt_logprobs":null}Expected output for about 10% of requests:
{"id":"chatcmpl-c6df57e9-ff95-41d6-8b35-19978f40525f","object":"chat.completion","created":1744602223,"model":"travel-helper-v2","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"Beijing is a city rich in history and culture, with many attractions worth visiting.\n\nHere are some recommended attractions:\n\n1. The Forbidden City: This is China's largest ancient palace complex and one of the best-preserved ancient imperial palaces in the world. You can learn about ancient Chinese court life and history here.\n\n2. The Great Wall: The sections of the Great Wall in Beijing are among the most famous in the world. You can enjoy the magnificent mountain scenery and the grandeur of the Great Wall here.\n\n3. Tiananmen Square: This is the largest city square in the world. You can see the solemn Monument to the People's Heroes and the Tiananmen Gate Tower here.\n\n4. The Summer Palace: This is China's largest imperial garden. You can admire the exquisite garden architecture and beautiful lake views here.\n\n5. Beijing Zoo: If you like animals, this is a great choice. You can see a wide variety of animals, including giant pandas.\n\n6. 798 Art Zone: This is a place full of artistic atmosphere. You can see various art exhibitions and creative markets here.\n\nI hope these suggestions are helpful!","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":38,"total_tokens":244,"completion_tokens":206,"prompt_tokens_details":null},"prompt_logprobs":null}Most inference requests are served by the
travel-helper-v1LoRA model, while a small portion are served by thetravel-helper-v2LoRA model.