Standard Kubernetes load balancing distributes LLM inference requests by simple round-robin or random selection, ignoring GPU cache state and queue depth. This causes uneven KV cache utilization across replicas, increasing redundant computation and response latency. Gateway with Inference Extension solves this by routing each request to the most suitable replica based on real-time inference server metrics.
This topic shows how to deploy Gateway with Inference Extension on an ACK managed cluster, configure inference-aware routing with InferencePool and InferenceModel, and verify the improvement using load testing and Grafana dashboards.
How it works

The gateway exposes two ports with different routing behaviors:
-
Port 8080 — Standard HTTPRoute. Requests go directly to the backend vLLM Service using standard load balancing.
-
Port 8081 — Inference-aware HTTPRoute. Requests pass through the inference service extension (LLM Route), which selects the best replica based on request queue length and GPU cache utilization before forwarding to the backend.
The InferencePool declares which pods form the inference backend. The InferenceModel maps an incoming model name to a routing policy within that pool. When a request arrives on port 8081, the extension reads live metrics from each pod and picks the replica with the most capacity to serve that request efficiently.
Key concepts
| Resource | Description |
|---|---|
| InferencePool | A Kubernetes CRD that groups a set of LLM inference pods into a single addressable backend. Replaces a plain Service as the backendRef in an HTTPRoute. |
| InferenceModel | A Kubernetes CRD that maps an incoming model name to a traffic distribution policy within an InferencePool. |
| Gateway with Inference Extension | An ACK component that embeds an endpoint picker (EPP) into the Envoy Gateway data plane. The EPP collects per-pod vLLM metrics and applies inference-aware load balancing. |
| KV cache | Per-request key-value state that vLLM stores in GPU memory to avoid recomputing historical context. Routing requests with the same prefix to the same pod maximizes KV cache reuse and reduces latency. |
Prerequisites
Before you begin, ensure that you have:
-
An ACK managed cluster with a GPU node pool
-
(Optional) The ACK Virtual Node component installed to use ACS GPU computing power in ACK Pro clusters
Step 1: Deploy the sample inference service
-
Create a file named
vllm-service.yamlwith the following content. View the YAMLFor the GPU card, use A10 cards for ACK clusters and GN8IS (8th-gen GPU B) cards for Alibaba Cloud Container Compute Service (ACS) GPU computing power. The LLM image is large — transfer it to Container Registry in advance and pull it over the internal network. Public network pull speed depends on the cluster EIP bandwidth and may be slow.
-
Deploy the inference service.
kubectl apply -f vllm-service.yaml
Step 2: Install the Gateway with Inference Extension component
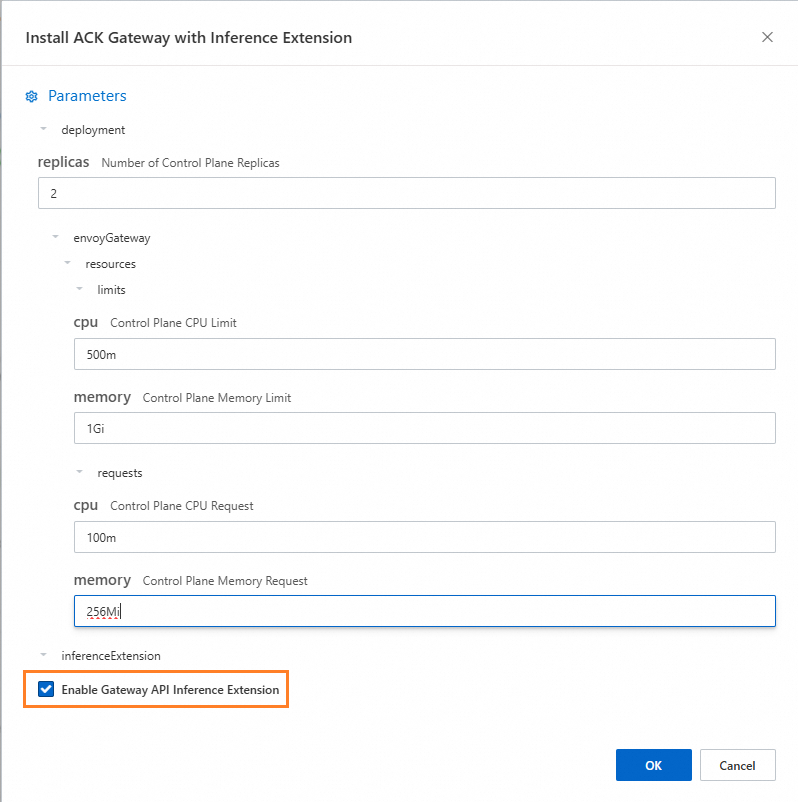
Install the ACK Gateway with Inference Extension component and select Enable Gateway API Inference Extension.
Step 3: Deploy inference routing
This step creates the InferencePool and InferenceModel resources that define the inference backend and its routing policy.
-
Create a file named
inference-pool.yaml.apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferencePool metadata: name: vllm-qwen-pool spec: targetPortNumber: 8000 selector: app: qwen extensionRef: name: inference-gateway-ext-proc --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceModel metadata: name: inferencemodel-qwen spec: modelName: /model/qwen criticality: Critical poolRef: group: inference.networking.x-k8s.io kind: InferencePool name: vllm-qwen-pool targetModels: - name: /model/qwen weight: 100 -
Apply the routing resources.
kubectl apply -f inference-gateway-llm.yaml
Step 4: Deploy and verify the gateway
This step creates a gateway with two listeners: port 8080 for standard HTTP routing and port 8081 for inference-aware routing.
-
Create a file named
inference-gateway.yaml.apiVersion: gateway.networking.k8s.io/v1 kind: GatewayClass metadata: name: qwen-inference-gateway-class spec: controllerName: gateway.envoyproxy.io/gatewayclass-controller --- apiVersion: gateway.networking.k8s.io/v1 kind: Gateway metadata: name: qwen-inference-gateway spec: gatewayClassName: qwen-inference-gateway-class listeners: - name: http protocol: HTTP port: 8080 - name: llm-gw protocol: HTTP port: 8081 --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: qwen-backend spec: parentRefs: - name: qwen-inference-gateway sectionName: llm-gw rules: - backendRefs: - group: inference.networking.x-k8s.io kind: InferencePool name: vllm-qwen-pool matches: - path: type: PathPrefix value: / --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: qwen-backend-no-inference spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: qwen-inference-gateway sectionName: http rules: - backendRefs: - group: "" kind: Service name: qwen port: 8000 weight: 1 matches: - path: type: PathPrefix value: / --- apiVersion: gateway.envoyproxy.io/v1alpha1 kind: BackendTrafficPolicy metadata: name: backend-timeout spec: timeout: http: requestTimeout: 1h targetRef: group: gateway.networking.k8s.io kind: Gateway name: qwen-inference-gateway -
Deploy the gateway.
kubectl apply -f inference-gateway.yamlThis creates the
envoy-gateway-systemnamespace and a Service namedenvoy-default-inference-gateway-645xxxxxin the cluster. -
Get the public IP address of the gateway.
export GATEWAY_HOST=$(kubectl get gateway/qwen-inference-gateway -o jsonpath='{.status.addresses[0].value}') -
Verify standard HTTP routing on port 8080.
curl -X POST ${GATEWAY_HOST}:8080/v1/chat/completions \ -H 'Content-Type: application/json' \ -d '{ "model": "/model/qwen", "max_completion_tokens": 100, "temperature": 0, "messages": [ { "role": "user", "content": "Write as if you were a critic: San Francisco" } ] }'Expected output:
{"id":"chatcmpl-aa6438e2-d65b-4211-afb8-ae8e76e7a692","object":"chat.completion","created":1747191180,"model":"/model/qwen","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"San Francisco, a city that has long been a beacon of innovation, culture, and diversity, continues to captivate the world with its unique charm and character. As a critic, I find myself both enamored and occasionally perplexed by the city's multifaceted personality.\n\nSan Francisco's architecture is a testament to its rich history and progressive spirit. The iconic cable cars, Victorian houses, and the Golden Gate Bridge are not just tourist attractions but symbols of the city's enduring appeal. However, the","tool_calls":[]},"logprobs":null,"finish_reason":"length","stop_reason":null}],"usage":{"prompt_tokens":39,"total_tokens":139,"completion_tokens":100,"prompt_tokens_details":null},"prompt_logprobs":null} -
Verify inference-aware routing on port 8081.
curl -X POST ${GATEWAY_HOST}:8081/v1/chat/completions \ -H 'Content-Type: application/json' \ -d '{ "model": "/model/qwen", "max_completion_tokens": 100, "temperature": 0, "messages": [ { "role": "user", "content": "Write as if you were a critic: Los Angeles" } ] }'Expected output:
{"id":"chatcmpl-cc4fcd0a-6a66-4684-8dc9-284d4eb77bb7","object":"chat.completion","created":1747191969,"model":"/model/qwen","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"Los Angeles, the sprawling metropolis often referred to as \"L.A.,\" is a city that defies easy description. It is a place where dreams are made and broken, where the sun never sets, and where the line between reality and fantasy is as blurred as the smog that often hangs over its valleys. As a critic, I find myself both captivated and perplexed by this city that is as much a state of mind as it is a physical place.\n\nOn one hand, Los","tool_calls":[]},"logprobs":null,"finish_reason":"length","stop_reason":null}],"usage":{"prompt_tokens":39,"total_tokens":139,"completion_tokens":100,"prompt_tokens_details":null},"prompt_logprobs":null}
(Optional) Step 5: Configure observability metrics and dashboards
This step requires Managed Service for Prometheus, which may incur additional fees.
Enable Prometheus metric collection
The vllm-service.yaml in Step 1 already includes the following annotations, which enable default service discovery for the Prometheus instance:
annotations:
prometheus.io/path: /metrics # The path where vLLM exposes metrics
prometheus.io/port: "8000" # The vLLM server listening port
prometheus.io/scrape: "true" # Enable scraping for this podThe following vLLM metrics are available once scraping is enabled:
| Metric | What it tells you |
|---|---|
vllm:gpu_cache_usage_perc |
Fraction of GPU KV cache in use per pod. Lower values mean more headroom for new requests. |
vllm:request_queue_time_seconds_sum |
Time requests spend waiting before the vLLM scheduler processes them. High values indicate the pod is overloaded. |
vllm:num_requests_running / vllm:num_requests_waiting / vllm:num_requests_swapped |
Real-time request pressure across the running, waiting, and swapped states. |
vllm:avg_generation_throughput_toks_per_s / vllm:avg_prompt_throughput_toks_per_s |
Token generation rate during decode and prefill stages. |
vllm:time_to_first_token_seconds_bucket |
Latency from request submission to the first token returned — a key user-experience metric. |
Set alert rules on these metrics to detect anomalies in LLM service performance automatically.
Import the Grafana dashboard
Import the following JSON into Grafana to visualize request rate, token throughput, time to first token (TTFT), KV cache utilization, scheduler state, and queue time for your vLLM deployment.
Preview:
Run a load test to compare routing strategies
Use vLLM benchmark to stress-test both routing paths and compare results in the Grafana dashboard.
-
Deploy the benchmark workload.
kubectl apply -f- <<EOF apiVersion: apps/v1 kind: Deployment metadata: labels: app: vllm-benchmark name: vllm-benchmark namespace: default spec: progressDeadlineSeconds: 600 replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: app: vllm-benchmark strategy: rollingUpdate: maxSurge: 25% maxUnavailable: 25% type: RollingUpdate template: metadata: creationTimestamp: null labels: app: vllm-benchmark spec: containers: - command: - sh - -c - sleep inf image: registry-cn-hangzhou.ack.aliyuncs.com/dev/llm-benchmark:random-and-qa imagePullPolicy: IfNotPresent name: vllm-benchmark resources: {} terminationMessagePath: /dev/termination-log terminationMessagePolicy: File dnsPolicy: ClusterFirst restartPolicy: Always schedulerName: default-scheduler securityContext: {} terminationGracePeriodSeconds: 30 EOF -
Get the gateway's internal cluster IP.
export GW_IP=$(kubectl get svc -n envoy-gateway-system -l gateway.envoyproxy.io/owning-gateway-namespace=default,gateway.envoyproxy.io/owning-gateway-name=qwen-inference-gateway -o jsonpath='{.items[0].spec.clusterIP}') -
Run the stress test.
Normal HTTP route
kubectl exec -it deploy/vllm-benchmark -- env GW_IP=${GW_IP} python3 /root/vllm/benchmarks/benchmark_serving.py \ --backend vllm \ --model /models/DeepSeek-R1-Distill-Qwen-7B \ --served-model-name /model/qwen \ --trust-remote-code \ --dataset-name random \ --random-prefix-len 10 \ --random-input-len 1550 \ --random-output-len 1800 \ --random-range-ratio 0.2 \ --num-prompts 3000 \ --max-concurrency 200 \ --host $GW_IP \ --port 8080 \ --endpoint /v1/completions \ --save-result \ 2>&1 | tee benchmark_serving.txtInference service route
kubectl exec -it deploy/vllm-benchmark -- env GW_IP=${GW_IP} python3 /root/vllm/benchmarks/benchmark_serving.py \ --backend vllm \ --model /models/DeepSeek-R1-Distill-Qwen-7B \ --served-model-name /model/qwen \ --trust-remote-code \ --dataset-name random \ --random-prefix-len 10 \ --random-input-len 1550 \ --random-output-len 1800 \ --random-range-ratio 0.2 \ --num-prompts 3000 \ --max-concurrency 200 \ --host $GW_IP \ --port 8081 \ --endpoint /v1/completions \ --save-result \ 2>&1 | tee benchmark_serving.txt -
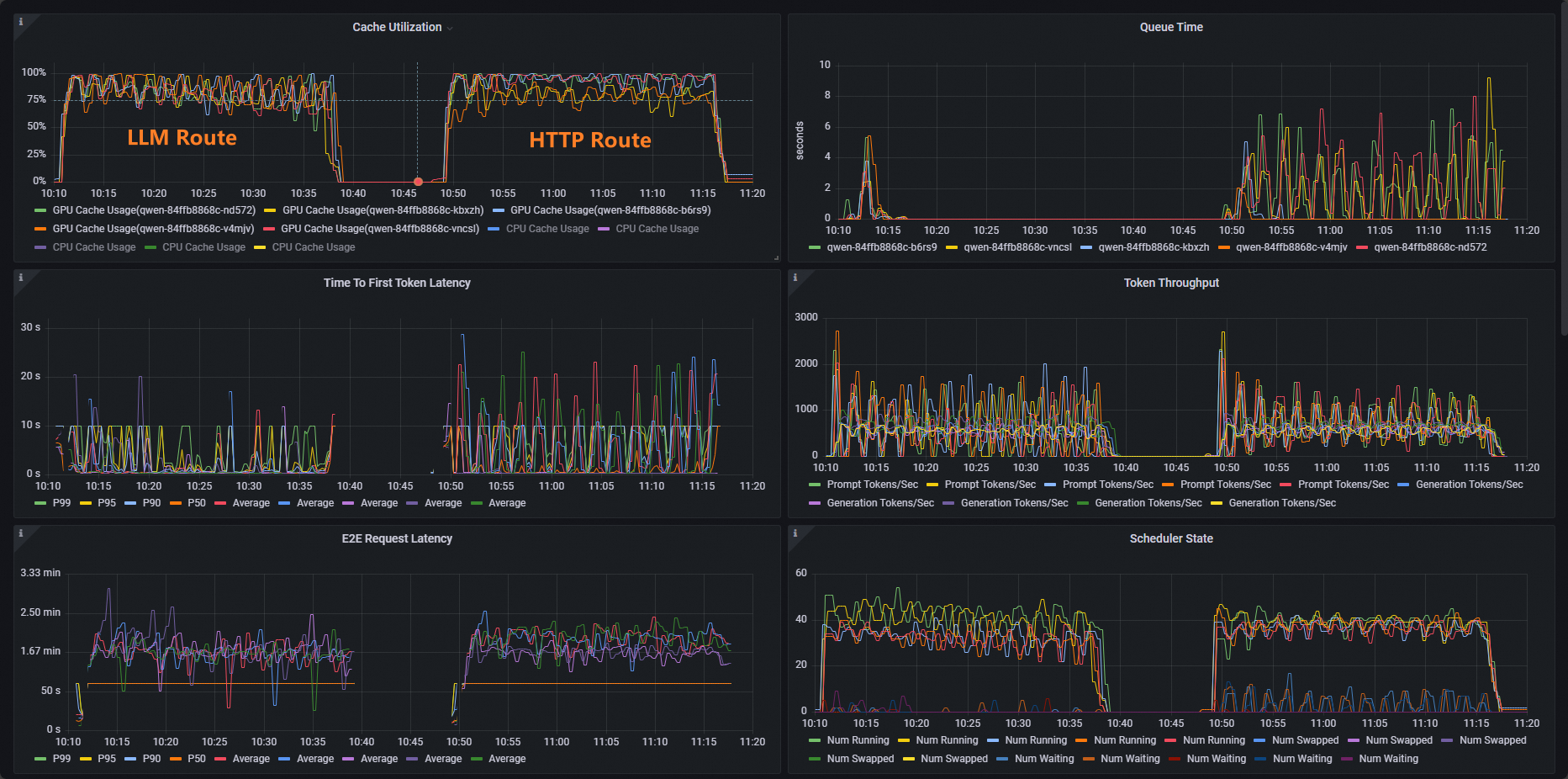
Open the Cache Utilization panel in your Grafana dashboard and compare the two runs. With standard HTTP routing, GPU cache utilization is skewed — some pods are saturated while others sit idle. With inference-aware routing, utilization distributes evenly across all pods, which reduces redundant KV cache computation and lowers latency under load.
What's next
Gateway with Inference Extension supports multiple load balancing policies. Set the inference.networking.x-k8s.io/routing-strategy annotation on an InferencePool to select the policy for that pool.
The following example uses the default policy:
apiVersion: inference.networking.x-k8s.io/v1alpha2
kind: InferencePool
metadata:
name: vllm-app-pool
annotations:
inference.networking.x-k8s.io/routing-strategy: "DEFAULT"
spec:
targetPortNumber: 8000
selector:
app: vllm-app
extensionRef:
name: inference-gateway-ext-proc| Policy | Best for |
|---|---|
DEFAULT |
General workloads. Routes based on request queue length and GPU cache utilization to balance load across all pods. |
PREFIX_CACHE |
Workloads with many requests sharing the same prefix. Routes matching requests to the same pod to maximize KV cache reuse. Typical use cases: long document Q&A (user guides, annual reports) and multi-turn conversations. Requires the auto prefix caching feature enabled on the inference server. |