Resolve common NGINX Ingress Controller issues with TLS, configuration, performance, and upgrades.
What are the known issues in earlier versions of the NGINX Ingress Controller?
Earlier versions have the following known issues. Upgrade to the latest version for stability.
-
Affected versions: 1.2.1-aliyun.1 and earlier.
Solution: Upgrade the NGINX Ingress Controller to version 1.5.1-aliyun.1 or later.
-
The temporary configuration files of nginx-cfg-xx are not cleared, which may cause disks to fill up
Affected versions: 1.10.2-aliyun.1 and earlier.
Solution: Upgrade the NGINX Ingress Controller to version 1.10.4-aliyun.1 or later.
-
Upload failures for files larger than 2 GB
Cause: The value of
client-body-buffer-sizeis larger than the storage limit for 32-bit integers.Solution: Set
client-body-buffer-sizeto a smaller value, such as200M.
Which TLS versions are supported?
Ingress-nginx supports TLS 1.2 and TLS 1.3. Clients using TLS versions earlier than 1.2 may encounter handshake errors.
To support additional TLS versions, add the following to the nginx-configuration ConfigMap in the kube-system namespace. See TLS/HTTPS.
To enable TLS 1.0 or 1.1 for NGINX Ingress Controller 1.7.0 and later, specify @SECLEVEL=0 in the ssl-ciphers parameter.

ssl-ciphers: "ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:DHE-RSA-CHACHA20-POLY1305:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA:ECDHE-RSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES256-SHA256:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:DES-CBC3-SHA"
ssl-protocols: "TLSv1 TLSv1.1 TLSv1.2 TLSv1.3"Are request headers passed to backend servers?
By default, ingress-nginx passes Layer 7 request headers to backend servers, but filters out non-standard HTTP headers (such as Mobile Version). To retain these headers, run kubectl edit cm -n kube-system nginx-configuration to update the ConfigMap. See ConfigMap.
enable-underscores-in-headers: trueHow do I forward requests to HTTPS backend servers?
To forward requests to HTTPS backend servers via ingress-nginx, add the following annotations to the Ingress:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: xxxx
annotations:
# You must specify HTTPS as the protocol used by the backend server.
nginx.ingress.kubernetes.io/backend-protocol: "HTTPS"How do I pass client IP addresses at Layer 7?
By default, ingress-nginx adds X-Forwarded-For and X-Real-IP headers to pass client IP addresses. However, if the client already includes these headers, the backend server cannot get the original client IP.
Run kubectl edit cm -n kube-system nginx-configuration to modify the nginx-configuration ConfigMap and enable ingress-nginx to pass client IP addresses at Layer 7:
compute-full-forwarded-for: "true"
forwarded-for-header: "X-Forwarded-For"
use-forwarded-headers: "true"If traffic passes multiple upstream proxy servers before reaching an NGINX Ingress, you must add the proxy-real-ip-cidr field to the nginx-configuration ConfigMap and set proxy-real-ip-cidr to the CIDR blocks of the upstream proxy servers (comma-separated). See Use WAF.
proxy-real-ip-cidr: "0.0.0.0/0,::/0" In IPv6 scenarios where NGINX Ingress receives an empty X-Forwarded-For header behind a Classic Load Balancer (CLB) instance, enable the Proxy protocol on CLB to retrieve the client IP. See Obtaining client IP addresses through a CLB Layer 4 listener.
How do I configure HSTS?
HTTP Strict Transport Security (HSTS) is enabled by default. When a browser first accesses the service via plain HTTP, the server triggers an HSTS response. In developer tools, you will see a Non-Authoritative-Reason: HSTS response header. HSTS-compatible browsers automatically switch to HTTPS for subsequent requests, resulting in a 307 Internal Redirect status code.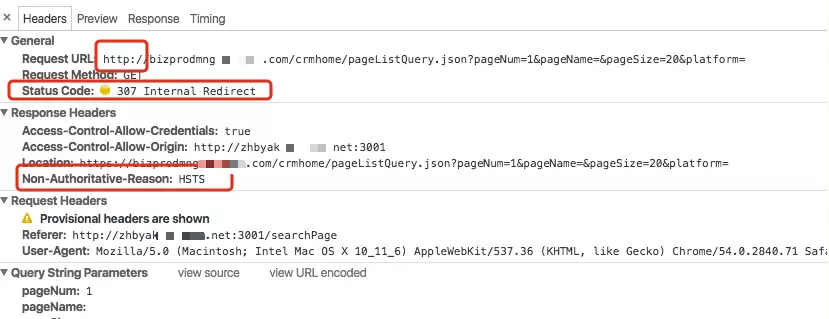
To prevent browsers from automatically upgrading subsequent requests to HTTPS, disable HSTS for nginx-ingress-controller. See HSTS.
Browsers cache HSTS configuration. Manually clear the browser cache after disabling HSTS for nginx-ingress-controller.
Which rewrite rules are supported?
Ingress-nginx supports only simple rewrite rules. For complex rewrite rules, use:
-
configuration-snippet: Add this annotation to the Ingress's location configuration.
-
server-snippet: Add to the Ingress's server configuration.
Other snippets add global configurations. See main-snippet.
What resources are updated during an NGINX Ingress Controller upgrade?
If the NGINX Ingress Controller version is earlier than 0.44, the following resources are included:
-
serviceaccount/ingress-nginx
-
configmap/nginx-configuration
-
configmap/tcp-services
-
configmap/udp-services
-
clusterrole.rbac.authorization.k8s.io/ingress-nginx
-
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx
-
role.rbac.authorization.k8s.io/ingress-nginx
-
rolebinding.rbac.authorization.k8s.io/ingress-nginx
-
service/nginx-ingress-lb
-
deployment.apps/nginx-ingress-controller
If the version is 0.44 or later, in addition to the preceding resources, the following resources are included:
-
validatingwebhookconfiguration.admissionregistration.k8s.io/ingress-nginx-admission
-
service/ingress-nginx-controller-admission
-
serviceaccount/ingress-nginx-admission
-
clusterrole.rbac.authorization.k8s.io/ingress-nginx-admission
-
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx-admission
-
role.rbac.authorization.k8s.io/ingress-nginx-admission
-
rolebinding.rbac.authorization.k8s.io/ingress-nginx-admission
-
job.batch/ingress-nginx-admission-create
-
job.batch/ingress-nginx-admission-patch
When you upgrade the NGINX Ingress Controller via the ACK console Add-ons page, the following resources remain unchanged:
-
configmap/nginx-configuration
-
configmap/tcp-services
-
configmap/udp-services
-
service/nginx-ingress-lb
All other resource configurations will reset to their default. For example, the default value of replicas in the deployment.apps/nginx-ingress-controller resource is 2. If you set replicas to 5 before upgrading NGINX Ingress Controller, it will revert to the default value of 2 after the upgrade.
How do I switch from Layer 4 to Layer 7 listeners?
By default, the LoadBalancer of ingress-nginx listens on TCP ports 80 and 443. Switch to Layer 7 listeners by changing the protocol to HTTP or HTTPS.
Service interruption occurs during listener changes. Perform this during off-peak hours.
-
Create a certificate and record the certificate ID (cert-id). See Use a certificate from Certificate Management Service.
-
Change the LoadBalancer listeners used by the Ingress from Layer 4 to Layer 7 via annotations.
Log on to the ACK console. In the left navigation pane, click Clusters.
On the Clusters page, click the name of your cluster. In the left navigation pane, click .
-
In the upper part of the Services page, set Namespace to
kube-system. Find theingress-nginx-lbService and click Edit YAML in the Actions column. -
In the Edit YAML panel, update the
targetPortto80for the port namedhttps(port 443).- name: https port: 443 protocol: TCP targetPort: 80 # Set targetPort to 80 for port 443.Add the following to the
annotationsfield, then click OK.service.beta.kubernetes.io/alibaba-cloud-loadbalancer-protocol-port: "http:80,https:443" service.beta.kubernetes.io/alibaba-cloud-loadbalancer-cert-id: "${YOUR_CERT_ID}"
-
Verify the result.
-
On the Services page, find the ingress-nginx-lb Service and click the
 icon in the Type column.
icon in the Type column. -
Click the Listener tab. If both
HTTP:80andHTTPS:443are displayed in the Frontend Protocol/Port column, the listeners of the LoadBalancer are changed from Layer 4 to Layer 7.
-
How do I use an existing SLB instance with ack-ingress-nginx?
Log on to the ACK console. In the left navigation pane, click .
-
On the App Catalog tab, select ack-ingress-nginx or ack-ingress-nginx-v1 based on your cluster version:
-
If your cluster runs Kubernetes 1.20 or earlier, select ack-ingress-nginx.
-
If your cluster runs a Kubernetes version later than 1.20, select ack-ingress-nginx-v1.
-
-
Deploy an Ingress controller. See Deploy multiple Ingress controllers for traffic isolation.
On the Parameters wizard page:
-
Delete all annotations in the controller.service.annotations section.

-
Add new annotations.
# Specify the SLB instance that you want to use. service.beta.kubernetes.io/alibaba-cloud-loadbalancer-id: "${YOUR_LOADBALANCER_ID}" # Overwrite the listeners. service.beta.kubernetes.io/alibaba-cloud-loadbalancer-force-override-listeners: "true"
-
-
Click OK to deploy the Ingress controller.
-
After the Ingress controller is deployed, configure an Ingress class. See Deploy multiple Ingress controllers for traffic isolation.
How do I collect access logs from multiple Ingress controllers?
Prerequisites
-
Logtail is installed in your cluster (installed by default during cluster creation; otherwise, see Collect container logs from ACK clusters).
-
Log collection is enabled for the default Ingress controller.
-
Labels of other Ingress controllers' pods are obtained. See How do I obtain the labels and environment variables of a Docker container?
Procedure:
-
Log on to the ACK console. In the left navigation pane, click Clusters.
-
On the Clusters page, click the target cluster name, then click Cluster Information in the left navigation pane.
-
On the Cluster Information page, click the Basic Information tab, then click the hyperlink to the right side of Log Service Project in the Cluster Resources section.
-
On the Logstores page, create a Logstore (see Manage Logstores). Create a separate Logstore per Ingress controller to avoid repeated collection.
-
Name the Logstore after the Ingress controller that uses it.
-
In the message that appears, click Data Collection Wizard.
-
-
In the Quick Data Import dialog box, choose . In the Note message, click Continue. On the Kubernetes Stdout and Stderr page, perform the following:
-
In the Create Machine Group step, click Use Existing Machine Groups.
-
In the Machine Group Configurations step, select the
k8s-group-<YOUR_CLUSTER_ID>machine group, and click>to move the machine group to the Applied Server Groups section. Then, click Next. -
In the Logtail Configuration step:
-
Click Import Other Configuration. Select the project used by the cluster and the
k8s-nginx-ingressconfiguration. Then, click OK. -
In the Global Configurations section, modify the configuration name. Enable the Container Filtering option, add the labels of the Ingress controller containers as key-value pairs.
-
In the Processor Configurations section, click Extract Field (Regex Mode) in the Processor Name column to view the log processing fields.
NoteIf different NGINX Ingress Controllers use different log formats, configure the corresponding log field keys and regex.
-
-
In the Query and Analysis Configurations step, click Next.
-
In the End step, click Query Log to view the collected logs.
-
How do I enable TCP listeners for nginx-ingress-controller?
By default, Ingresses forward only HTTP and HTTPS requests. Configure ingress-nginx to forward external TCP requests on ports specified in the relevant ConfigMap.
-
Use the tcp-echo template to deploy a Service and a Deployment.
-
Use the following template to create a ConfigMap.
-
Modify the
tcp-services-cm.yamlfile, save the changes and exit.apiVersion: v1 kind: ConfigMap metadata: name: tcp-services namespace: kube-system data: 9000: "default/tcp-echo:9000" # This configuration indicates that external TCP requests received on port 9000 are forwarded to the tcp-echo Service in the default namespace. 9001: "default/tcp-echo:9001" -
Create the ConfigMap.
kubectl apply -f tcp-services-cm.yaml
-
-
Add TCP ports for the Service used by
nginx-ingress-controller, then save the changes and exit.kubectl edit svc nginx-ingress-lb -n kube-systemapiVersion: v1 kind: Service metadata: labels: app: nginx-ingress-lb name: nginx-ingress-lb namespace: kube-system spec: allocateLoadBalancerNodePorts: true clusterIP: 192.168.xx.xx ipFamilies: - IPv4 ports: - name: http nodePort: 30xxx port: 80 protocol: TCP targetPort: 80 - name: https nodePort: 30xxx port: 443 protocol: TCP targetPort: 443 - name: tcp-echo-9000 # The port name. port: 9000 # The port number. protocol: TCP # The protocol. targetPort: 9000 # The destination port. - name: tcp-echo-9001 # The port name. port: 9001 # The port number. protocol: TCP # The protocol. targetPort: 9001 selector: app: ingress-nginx sessionAffinity: None type: LoadBalancer -
Verify the configuration:
-
Query the Ingress to obtain the SLB instance IP address:
kubectl get svc -n kube-system| grep nginx-ingress-lbExpected output:
nginx-ingress-lb LoadBalancer 192.168.xx.xx 172.16.xx.xx 80:31246/TCP,443:30298/TCP,9000:32545/TCP,9001:31069/TCP -
Send
helloworldto the IP address on port 9000 usingnc. If no response is returned, the configuration has taken effect.echo "helloworld" | nc <172.16.xx.xx> 9000 echo "helloworld" | nc <172.16.xx.xx> 9001
-
How does the NGINX Ingress Controller match a TLS certificate to a request?
In a Kubernetes Ingress resource, the TLS certificate is defined in the spec.tls field, but the hostname it applies to is specified in the spec.rules.host field.
The NGINX Ingress Controller processes these rules and stores the mapping between each hostname and its corresponding certificate in an internal Lua table.
Request Flow
-
When a client initiates an HTTPS request, it includes the requested hostname in the Server Name Indication (SNI) extension of the TLS handshake.
-
The NGINX Ingress Controller receives this request and uses the
certificate.call()function to look up the SNI hostname in its Lua mapping table. -
If a matching certificate is found, it is presented to the client to complete the TLS handshake.
-
If no matching certificate is found for the requested hostname, the controller presents a default, self-signed
fakecertificate.
The relevant NGINX configuration that implements this logic is shown below:
## Start server _
server {
server_name _ ;
listen 80 default_server reuseport backlog=65535 ;
listen [::]:80 default_server reuseport backlog=65535 ;
listen 443 default_server reuseport backlog=65535 ssl http2 ;
listen [::]:443 default_server reuseport backlog=65535 ssl http2 ;
set $proxy_upstream_name "-";
ssl_reject_handshake off;
ssl_certificate_by_lua_block {
certificate.call()
}
...
}
## Start server www.example.com
server {
server_name www.example.com ;
listen 80 ;
listen [::]:80 ;
listen 443 ssl http2 ;
listen [::]:443 ssl http2 ;
set $proxy_upstream_name "-";
ssl_certificate_by_lua_block {
certificate.call()
}
...
}ingress-nginx supports Online Certificate Status Protocol (OCSP) Stapling, which eliminates direct CA contact for revocation checks and reduces initial connection time. See Configure OCSP stapling.
What do I do if no certificate matches an NGINX Ingress?
HTTPS access errors can occur if the TLS certificate and its private key do not match, or if the domain name in the certificate does not match the hostname used by the client. Perform the following operations to troubleshoot this issue:
-
Verify that the certificate and private key match
Extract the certificate and private key from the Kubernetes Secret and compare their cryptographic moduli:
# Replace <YOUR-SECRET-NAME> and <SECRET-NAMESPACE> with your values kubectl get secret <YOUR-SECRET-NAME> -n <SECRET-NAMESPACE> -o jsonpath='{.data.tls\.crt}' | base64 -d > /tmp/tls.crt && \ # Replace with <YOUR-SECRET-NAME> with the Secret you use. kubectl get secret <YOUR-SECRET-NAME> -n <SECRET-NAMESPACE> -o jsonpath='{.data.tls\.key}' | base64 -d > /tmp/tls.key && \ # Calculate and compare the MD5 hash of the moduli for the certificate and the key openssl x509 -noout -modulus -in /tmp/tls.crt | openssl md5 && \ openssl rsa -noout -modulus -in /tmp/tls.key | openssl md5These commands extract the certificate and key to
/tmp/tls.crtand/tmp/tls.keyrespectively. Theopensslcommands calculate the MD5 hash of the public modulus for both.If the hash values are not identical, the certificate and private key do not match. Update the Secret with a valid, matching key pair.
-
Verify that the certificate matches the domain name
Inspect the certificate and check the domain names it covers:
kubectl get secret <YOUR-SECRET-NAME> -n <SECRET-NAMESPACE> -o jsonpath={.data."tls\.crt"} | base64 -d | openssl x509 -text -nooutReview the output:
-
Subject: Look for the Common Name (CN) field, which will be in a format similar to
CN = example.com. -
Subject Alternative Name (SAN): Look for the
DNS:entries.
If your hostname is not listed in the
CNor the SAN entries, the certificate is invalid for that domain. Obtain a new certificate covering the correct hostname(s). -
What do I do if NGINX pods fail health checks under high traffic?
Background
The NGINX Ingress Controller health check accesses the /healthz path on port 10246, verifying that the NGINX process is healthy.
Symptom
When health checks fail, logs indicate the healthz endpoint is unreachable:
I0412 11:01:52.581960 7 healthz.go:261] nginx-ingress-controller check failed: healthz
[-]nginx-ingress-controller failed: the ingress controller is shutting down
2024/04/12 11:01:55 Get "http://127.0.0.1:10246/nginx_status": dial tcp 127.0.0.1:10246: connect: connection refused
W0412 11:01:55.895683 7 nginx_status.go:171] unexpected error obtaining nginx status info: Get "http://127.0.0.1:10246/nginx_status": dial tcp 127.0.0.1:10246: connect: connection refused
I0412 11:02:02.582247 7 healthz.go:261] nginx-ingress-controller check failed: healthz
[-]nginx-ingress-controller failed: the ingress controller is shutting down
2024/04/12 11:02:05 Get "http://127.0.0.1:10246/nginx_status": dial tcp 127.0.0.1:10246: connect: connection refused
W0412 11:02:05.896126 7 nginx_status.go:171] unexpected error obtaining nginx status info: Get "http://127.0.0.1:10246/nginx_status": dial tcp 127.0.0.1:10246: connect: connection refused
I0412 11:02:12.582687 7 healthz.go:261] nginx-ingress-controller check failed: healthz
[-]nginx-ingress-controller failed: the ingress controller is shutting down
2024/04/12 11:02:15 Get "http://127.0.0.1:10246/nginx_status": dial tcp 127.0.0.1:10246: connect: connection refused
W0412 11:02:15.895719 7 nginx_status.go:171] unexpected error obtaining nginx status info: Get "http://127.0.0.1:10246/nginx_status": dial tcp 127.0.0.1:10246: connect: connection refused
I0412 11:02:22.582516 7 healthz.go:261] nginx-ingress-controller check failed: healthz
[-]nginx-ingress-controller failed: the ingress controller is shutting down
2024/04/12 11:02:25 Get "http://127.0.0.1:10246/nginx_status": dial tcp 127.0.0.1:10246: connect: connection refused
W0412 11:02:25.896955 7 nginx_status.go:171] unexpected error obtaining nginx status info: Get "http://127.0.0.1:10246/nginx_status": dial tcp 127.0.0.1:10246: connect: connection refused
I0412 11:02:28.983016 7 nginx.go:408] "NGINX process has stopped"
I0412 11:02:28.983033 7 sigterm.go:44] Handled quit, delaying controller exit for 10 seconds
I0412 11:02:32.582587 7 healthz.go:261] nginx-ingress-controller check failed: healthz
[-]nginx-ingress-controller failed: the ingress controller is shutting down
2024/04/12 11:02:35 Get "http://127.0.0.1:10246/nginx_status": dial tcp 127.0.0.1:10246: connect: connection refused
W0412 11:02:35.895853 7 nginx_status.go:171] unexpected error obtaining nginx status info: Get "http://127.0.0.1:10246/nginx_status": dial tcp 127.0.0.1:10246: connect: connection refused
I0412 11:02:38.986048 7 sigterm.go:47] "Exiting" code=0Cause
Under high traffic, NGINX worker processes can reach near-100% CPU utilization, leaving insufficient resources to respond to health check probes in time.
Solution
Increase the number of pod replicas for the NGINX Ingress Controller to distribute traffic and reduce per-pod CPU pressure.
What do I do if cert-manager fails to issue a certificate?
This occurs when Web Application Firewall (WAF) is enabled. WAF may intercept the HTTP01 requests that cert-manager uses for domain ownership verification, preventing certificate issuance.
To resolve this, temporarily disable the WAF to allow the HTTP-01 challenge to succeed.
Before disabling your WAF, you must fully assess the potential security implications to avoid exposing your application to unnecessary risks.
Why is NGINX using a large amount of memory under high traffic?
Symptom
Under high traffic, the NGINX Ingress Controller's memory usage increases significantly, eventually causing an Out-of-Memory (OOM) event.
Cause
If the controller process consumes excessive memory, the issue is likely a memory leak in Prometheus metrics collection.
This is a known issue in NGINX Ingress Controller version 1.6.4, often linked to high-cardinality metrics such as nginx_ingress_controller_ingress_upstream_latency_seconds.
Solution
Upgrade the NGINX Ingress Controller to the latest version, which fixes this issue. When configuring NGINX Ingress for high-traffic environments, monitor metrics that significantly impact memory usage.
Community resources:
What do I do if the NGINX Ingress Controller is in a stalled upgrade state?
Symptom
During a staged rollout (canary upgrade) of the NGINX Ingress Controller, the process gets stuck in the validation phase. You may see: Operation is forbidden for task in a failed state.
Cause
This occurs when the add-on upgrade task is cleaned up by the system after exceeding its 4-day expiration period. Manually reset the add-on's deployment state to resolve this.
Note: If the add-on has already reached the final Released phase of the upgrade, no action is required. Simply wait for the current task to time out and terminate automatically.
Procedure
Reset the Deployment and allow the upgrade to proceed.
-
Open the
Deploymentmanifest for editing:kubectl edit deploy -n kube-system nginx-ingress-controller -
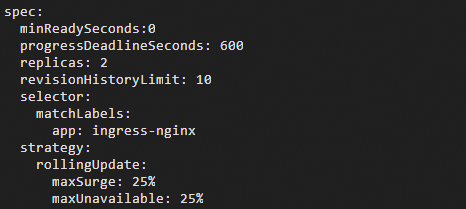
In the editor, locate the following fields under the
specsection and restore them to their default values as shown below:-
spec.minReadySeconds: 0 -
spec.progressDeadlineSeconds: 600 -
spec.strategy.rollingUpdate.maxSurge: 25% -
spec.strategy.rollingUpdate.maxUnavailable: 25%
-
-
Save the changes and exit the editor.
Expected outcome
After saving, the add-on upgrade automatically resumes and old pods are replaced to complete the staged rollout.
The upgrade completes in the background, but the add-on status on the ACK console Add-ons page may show Upgrading for up to two weeks before auto-resolving.
Why has chunked transfer encoding (Transfer-Encoding: chunked) stopped working since controller version 1.10?
Symptom
Your application sets Transfer-Encoding: chunked, and the controller logs show errors related to duplicate headers.
Cause
Starting in v1.10, the underlying NGINX version (see NGINX update logs) enforces stricter HTTP response validation. If a backend returns multiple Transfer-Encoding: chunked headers, NGINX now treats the response as invalid.
Solution
Ensure your backend returns only a single Transfer-Encoding: chunked header. See GitHub Issue #11162.
How do I configure an IP allowlist/denylist for access control?
NGINX Ingress supports IP-based access control using either annotations on an Ingress resource or key-value pairs in the global ConfigMap.
-
ConfigMap: Applies globally to all Ingresses.
-
Ingress annotation: Applies only to the specific Ingress resource.
Annotations on an Ingress resource will always take precedence over the global ConfigMap setting.
Use the following annotations in your Ingress manifest:
|
Annotation |
Description |
|
|
A denylist of client IP addresses or CIDR blocks. Multiple values can be provided, separated by commas (,). |
|
|
An allowlist of client IP addresses or CIDR blocks. Multiple values can be provided, separated by commas (,). |
See the official documentation for Denylist Source Range and Whitelist Source Range.
Known issue in NGINX Ingress v1.2.1 with defaultBackend
Symptom
Configuring a defaultBackend in an Ingress resource may incorrectly override the defaultBackend setting of the default server.
Solution
This is a known issue (see GitHub Issue #8823). Upgrade the NGINX Ingress Controller to version 1.3 or later. See Upgrade the NGINX Ingress Controller.
Why do I get a Connection reset by peer error when using curl?
Symptom
When using curl to access an external public service over HTTP, you receive the error: curl: (56) Recv failure: Connection reset by peer.
Cause
This typically occurs when a plain-text HTTP request contains keywords that are flagged as sensitive by network intermediaries, causing the connection to be blocked or reset.
Solution
Configure a TLS certificate for your Ingress route and use HTTPS for all communications to ensure the traffic is encrypted.
How does path matching priority work?
NGINX regular expression paths are evaluated in the order they are defined, and the first match is used. To enable more precise path matching, ingress-nginx first sorts all paths in descending order by length and then writes them as location blocks in the nginx.conf file.
Why are non-idempotent requests not retried?
Starting with version 1.9.13, NGINX will not retry non-idempotent requests (POST, LOCK, and PATCH) when an error occurs.
To restore the previous behavior, set retry-non-idempotent: "true" in the nginx-configuration ConfigMap.
How do I support requests with large client headers or cookies?
Symptom
When accessing your service via the NGINX Ingress, you receive a 400 Bad Request error with the message Request Header Or Cookie Too Large.
Cause
This error occurs when the size of the client's request headers or cookies exceeds the default buffer sizes configured in Nginx.
Solution
Increase the relevant buffer sizes. The two key parameters are:
-
client-header-buffer-size: The buffer size for client request headers. The default is
1k. -
large-client-header-buffers: The maximum number and size of buffers for reading large client request headers. The default is
4 8k.
Modify these parameters by editing the nginx-configuration ConfigMap:kubectl edit cm -n kube-system nginx-configuration
Example:
client-header-buffer-size: "16k"
large-client-header-buffers: "4 32k" After applying the changes, verify that they have taken effect in the NGINX configuration. You can inspect the nginx.conf file inside one of the Ingress controller pods:kubectl exec <nginx-ingress-pod> -n kube-system -- cat /etc/nginx/nginx.conf
Why are my Exact or Prefix paths still being treated as regular expressions?
If any Ingress rule for a given host uses either the use-regex or rewrite-target annotation, all paths under that same host will be forced to use case-insensitive regular expression matching. This is the current implementation logic of the NGINX Ingress Controller. See Community documentation.

Why is the validation webhook slow to respond when adding an Ingress in a cluster with many Ingresses ?
This is a known performance issue in NGINX Ingress Controller V1.12 and earlier. The validation webhook performs a full check against all existing Ingresses, which can be slow in large environments. See #11115.
Solution:
-
Option 1: Increase the webhook timeout
If you can tolerate the longer response times and do not want to use incremental validation, increase the timeout for the validation webhook. The default is10s.-
Action: Edit the
validatingwebhookconfigurationsobject namedingress-nginx-admissionand increase thetimeoutSecondsvalue (maximum30s). -
Caution: This value will be overwritten during an add-on upgrade.
-
-
Option 2: Enable incremental validation
Modify the NGINX Ingress Controller'sDeploymentto add the--disable-full-test=truestartup argument.-
Effect: With this flag, the webhook will only perform an incremental validation on the new Ingress rule. This significantly improves validation speed but will not detect conflicts between different Ingress resources.
-
A note on using snippets
Issue
If you configure server-snippet annotations for the
same
domain across multiple Ingress resources, you may encounter a warning in the logs, and only the first snippet will be applied. This can lead to unexpected behavior.
Example log warning:
W0619 14:58:49.323721 7 controller.go:1314] Server snippet already configured for server "test.example.com", skipping (Ingress "default/test.example.com")
W0619 14:58:49.323727 7 controller.go:1314] Server snippet already configured for server "test.example.com", skipping (Ingress "default/test.example.com")
W0619 14:58:49.323734 7 controller.go:1314] Server snippet already configured for server "test.example.com", skipping (Ingress "default/test.example.com")This warning indicates that a snippet for test.example.com has already been defined, and subsequent definitions from other Ingress resources are being ignored.
Why is the TLS certificate I configured in a Secret not working?
Check the controller logs
Inspect the logs of your NGINX Ingress Controller pod for certificate-related errors.
kubectl -n kube-system logs <nginx-ingress-controller-pod-name> | grep "Error getting SSL certificate"If you see an error similar to the one below, it indicates a problem loading your certificate Secret (where xxxx is your Secret's name).
Error getting SSL certificate "xxxx": local SSL certificate xxxx tls was not found. Using default certificateThis error can have three primary causes:
Cause 1: The Secret does not exist
Verify that the Secret named in the log message actually exists in the correct namespace.
Cause 2: The certificate and private key do not match
The tls.crt (public key) and tls.key (private key) stored in the Secret must be a matching pair.
-
If you attempt to create a
tlsSecret with a mismatched pair usingkubectl create secret tls, the command will fail with an error:error: tls: private key does not match public key -
To check an existing Secret for a mismatch, run the following script:
export SECRET_NAME=<Your Secret Name> export NAME_SPACE=<Your Secret Namespace> diff <(kubectl get secret $SECRET_NAME -n $NAME_SPACE -o jsonpath='{.data.tls\.crt}' | base64 -d | openssl x509 -noout -modulus | openssl md5) <(kubectl get secret $SECRET_NAME -n $NAME_SPACE -o jsonpath='{.data.tls\.key}' | base64 -d | openssl rsa -noout -modulus | openssl md5) && echo "Certificate and Key match" || echo "Certificate and Key do not match"This command compares the moduli of the certificate and key. If the key and certificate do not match, the output will show two different hash values and the message
Certificate and Key do not match. Update the Secret with a valid key pair.root@Aliyun ~/ssl # export SECRET_NAME=test root@Aliyun ~/ssl # export NAME_SPACE=default root@Aliyun ~/ssl # diff <(kubectl get secret $SECRET_NAME -n $NAME_SPACE -o jsonpath='{.data.tls\.crt}' | base64 -d | openssl x509 -noout -modulus | openssl md5) <(kubectl get secret $SECRET_NAME -n $NAME_SPACE -o jsonpath='{.data.tls\.key}' | base64 -d | openssl rsa -noout -modulus | openssl md5) && echo "Certificate and Key match" || echo "Certificate and Key do not match" 1c1 < (stdin)= 66a309089e87e32d1b6fe361ebf8cd88 --- > (stdin)= 12e15c5fe35585b6fd9920abc8e8706d Certificate and Key do not match
Cause 3: A misconfigured TLS entry in another Ingress for the same domain
If you have defined tls sections for the same domain across multiple Ingress resources, an error in just one of those configurations can prevent the certificate from being loaded correctly. Review all Ingress resources that reference the domain and correct any misconfigurations.
Why do I still receive certificate expiration alerts after updating my certificate?
Cause
Older versions have a known bug where the nginx_ingress_controller_ssl_expire_time_seconds metric is not updated after certificate renewal, causing stale certificate expired alerts.
Solution
Clear the stale metric by performing a rolling restart of the NGINX Ingress Controller pods.
Upgrade NGINX Ingress Controller to version 1.11.4 or later, because this issue is resolved in newer versions.
How can I find the default configuration for a specific NGINX Ingress Controller version?
The default values for configuration parameters change between versions of the NGINX Ingress Controller. For example, use-gzip was enabled by default in versions 0.35.0 and earlier, but it is disabled by default in version 1.11.4.
To find the default behavior for a specific parameter in a particular version, consult the configmap.md file in the corresponding version branch of the official documentation.
Example: For controller-v1.8.0, use the version selector on the left side of the page to switch to other versions.