By default, the minimum memory allocation unit for shared GPU scheduling is 1 GiB. If your workloads require finer-grained GPU memory allocation, you can reduce this unit to 128 MiB. This topic describes how to adjust the minimum memory allocation unit by configuring the ack-ai-installer component in Cloud-native AI Suite.
Prerequisites
An ACK managed Pro cluster that runs Kubernetes 1.18.8 or later is created. For more information, see Create an ACK managed cluster and UpgradeCluster.
Constraints
Before you adjust the minimum memory allocation unit, review the following constraints:
| Constraint | Details |
|---|---|
| Delete existing GPU pods first | If the aliyun.com/gpu-mem field is specified for a pod, the pod requests GPU resources. You must delete all such pods before you change the minimum memory allocation unit. Otherwise, the scheduler ledger may become disordered. |
| Supported node types | You can adjust the minimum memory allocation unit only for nodes that have GPU sharing enabled but memory isolation disabled. These nodes have the ack.node.gpu.schedule=share label. Nodes with both GPU sharing and memory isolation enabled have the ack.node.gpu.schedule=cgpu label. Due to the limits of the memory isolation module, each GPU can create at most 16 pods even if you change the minimum memory allocation unit to 128 MiB. |
| Autoscaling limitation | If you set the minimum memory allocation unit to 128 MiB, the nodes in the cluster cannot be automatically scaled even if you enable autoscaling for the nodes. For example, if you set the aliyun.com/gpu-mem field to 32 for a pod and the available GPU memory in the cluster is insufficient, no new node is added and the pod remains in the Pending state. |
| Legacy clusters | If you use a cluster that was created before October 20, 2021, you must submit a ticket to restart the scheduler. The new minimum memory allocation unit takes effect only after the scheduler is restarted. |
Procedure
Choose one of the following procedures based on whether ack-ai-installer is already installed in your cluster.
Scenario 1: ack-ai-installer is not installed
Log on to the Container Service Management Console . In the navigation pane on the left, click Clusters.
On the Clusters page, click the name of your cluster. In the navigation pane on the left, click .
In the lower part of the page, click Deploy. On the page that appears, select Scheduling Policy Extension (Batch Task Scheduling, GPU Sharing, Topology-aware GPU Scheduling) and click Advanced.
Add the
gpuMemoryUnit: 128MiBparameter in the configuration section, and then click OK.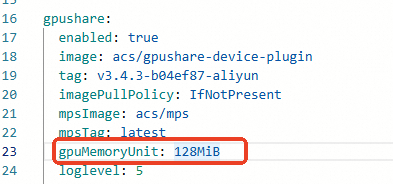
Click Deploy Cloud-native AI Suite.
Wait until the status of ack-ai-installer changes from Deploying to Deployed, which indicates that ack-ai-installer is deployed.
Scenario 2: ack-ai-installer is already installed
If ack-ai-installer is already installed, you must uninstall it and redeploy it with the new configuration.
Log on to the Container Service Management Console . In the navigation pane on the left, click Clusters.
On the Clusters page, click the name of your cluster. In the navigation pane on the left, click .
On the Cloud-native AI Suite page, find ack-ai-installer in the component list and click Uninstall in the Actions column. In the Uninstall Component message, click Confirm.
After ack-ai-installer is uninstalled, click Deploy in the Actions column. In the Parameters panel, add
gpuMemoryUnit: 128MiBto the code.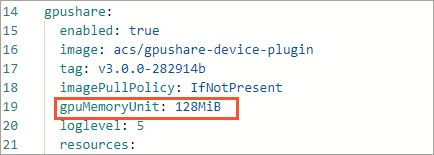
Click OK.
Wait until the status of ack-ai-installer changes from Deploying to Deployed, which indicates that ack-ai-installer is deployed.
Example: Request GPU memory with the 128 MiB allocation unit
The following example shows how to request GPU memory for a pod by using a StatefulSet. The aliyun.com/gpu-mem field specifies the number of allocation units to request. When the minimum memory allocation unit is 128 MiB, setting aliyun.com/gpu-mem to 16 requests a total of 16 x 128 MiB = 2 GiB of GPU memory.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: binpack
labels:
app: binpack
spec:
replicas: 1
serviceName: "binpack-1"
podManagementPolicy: "Parallel"
selector: # Define how the deployment finds the pods it manages.
matchLabels:
app: binpack-1
template: # The pod specifications.
metadata:
labels:
app: binpack-1
spec:
containers:
- name: binpack-1
image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:tensorflow-1.5
command:
- bash
- gpushare/run.sh
resources:
limits:
aliyun.com/gpu-mem: 16 # 16 units x 128 MiB/unit = 2 GiB total GPU memory