This page answers common questions about node instant scaling in Container Service for Kubernetes (ACK). Use the symptom descriptions below to jump to the section most relevant to your issue.
Common symptoms:
-
Pods stuck in the
Pendingstate and nodes are not being added — see Why does node instant scaling fail to add nodes? -
Nodes are not being removed after workloads scale down — see Why does node instant scaling fail to remove nodes?
-
Node scaling is not triggered at all on a managed cluster — see Why is node scaling not working on my ACK managed cluster even though role authorization is complete?
Limitations
What are the known limitations of node instant scaling?
Feature limitations:
-
Node instant scaling does not support swift mode.
-
A node pool can contain up to 180 nodes per scale-out batch.
-
Scale-in cannot be disabled at the cluster level. To protect individual nodes from scale-in, see How do I prevent node instant scaling from removing specific nodes?
-
Node instant scaling cannot check the inventory of preemptible instances. If the Billing Method of a node pool is set to preemptible instances and Use Pay-as-you-go Instances When Spot Instances Are Insufficient is enabled, a pay-as-you-go instance is provisioned even when preemptible inventory is sufficient.
Resource estimation gap:
The available resources on a newly provisioned node may be slightly less than the instance type's listed specifications, because the underlying OS and system daemons consume a portion of the resources. For details, see Why is the memory size of a purchased instance different from the memory size defined in its instance type?
Because of this overhead, the resource estimates used by the add-on may be slightly higher than the actual allocatable resources on a new node. Keep the following in mind when setting pod resource requests:
-
Stay under full instance capacity. The total requested resources — CPU, memory, and disk — must be less than the instance type's listed specifications. As a general guideline, keep a pod's total resource requests below 70% of the node's capacity.
-
Account for static pods manually. The add-on only considers the resource requests of Kubernetes-managed pods (pending pods and DaemonSet pods). If you run static pods outside DaemonSet management, reserve capacity for them manually.
-
Test large pods in advance. If a pod requests more than 70% of a node's resources, test and confirm that the pod can be scheduled to a node of the same instance type before relying on automatic scale-out.
Limited simulatable resource types:
Node instant scaling can simulate and evaluate only certain resource types when deciding whether to scale out. For the full list, see What resource types can node instant scaling simulate?
Storage constraints:
The autoscaler is unaware of pod-level storage constraints, such as:
-
Needing to run in a specific zone to access a persistent volume (PV).
-
Requiring a node that supports a specific disk type, such as ESSD.
If your workload has such storage dependencies, configure a dedicated node pool before enabling Auto Scaling on that pool. Preset the zone, instance type, and disk type in the node pool configuration so that newly provisioned nodes always meet the pod's storage requirements.
Scale-out behavior
What resource types can node instant scaling simulate?
Node instant scaling evaluates scale-out decisions based on the following resource types:
cpu
memory
ephemeral-storage
aliyun.com/gpu-mem # Shared GPUs only
nvidia.com/gpuDoes node instant scaling select the right-sized instance type for a pod?
Yes. The autoscaler picks the most resource-efficient instance type that satisfies the pod's requests.
For example, if a node pool contains a 4 vCPU / 8 GiB type and a 12 vCPU / 48 GiB type, a pod requesting 2 vCPU triggers provisioning of a 4 vCPU / 8 GiB node. If you later replace the 4 vCPU / 8 GiB type with an 8 vCPU / 16 GiB type, the add-on automatically adapts and provisions 8 vCPU / 16 GiB nodes for similar future requests.
If a node pool has multiple instance types, how does node instant scaling choose which one to provision?
Node instant scaling follows a three-step selection process:
-
Filter by availability. Instance types with insufficient inventory in the region are periodically identified and excluded.
-
Sort by size. Remaining instance types are sorted in ascending order by vCPU count.
-
Select the first match. Starting from the smallest, the add-on checks each type against the pending pod's resource requests and provisions the first type that satisfies them. Larger types are not evaluated once a match is found.
How can I monitor the inventory health of instance types in my node pool?
Node instant scaling periodically updates inventory status for instance types in Auto Scaling-enabled node pools. When the inventory status of an instance type changes, the add-on emits a Kubernetes event named InstanceInventoryStatusChanged. Watch for these events to track availability and adjust your node pool configuration before scale-out failures occur. For details, see View the health status of node instant scaling.
How do I reduce the risk of scale-out failures from insufficient inventory?
Configure your node pool with a broader range of instance types:
-
Add multiple instance types to the node pool, or use a generalized instance configuration.
-
Enable multiple zones for the node pool.
Why does node instant scaling fail to add nodes?
Check the following common causes:
Insufficient inventory
The instance types in the node pool are out of stock. To diagnose, watch for InstanceInventoryStatusChanged events or check the node pool health status. To resolve, add more instance types or zones. See How do I reduce the risk of scale-out failures from insufficient inventory?
Instance type too small for the pod
The pod's resource requests exceed what the instance can provide after system overhead is subtracted. The listed instance specification is the raw capacity. ACK reserves a portion for Kubernetes system processes (kubelet, kube-proxy, Terway, the container runtime, and other add-ons).
To diagnose, compare the pod's resource requests against the node's allocatable resources using kubectl describe node <node-name> and check the Allocatable section. For details on reserved resources, see:
Authorization incomplete
Node scaling requires role authorization. To diagnose, check whether the required token (addon.aliyuncsmanagedautoscalerrole.token) exists in a Secret within the kube-system namespace. To resolve, follow Enable instant elasticity for nodes to complete the setup.
Abnormal nodes in the node pool
Node instant scaling pauses scale-out when the node pool contains abnormal nodes, to preserve system stability. To diagnose, check for nodes in a NotReady or error state using kubectl get nodes. Resolve all abnormal nodes before scale-out resumes.
How do I configure custom resources for a node pool with node instant scaling enabled?
Add ECS tags with the following prefix to the node pool. The add-on reads these tags to determine available custom resources and their values.
ACK GOATScaler version 0.2.18 or later is required. To upgrade, see Manage add-ons.
Tag format:
goatscaler.io/node-template/resource/{resource-name}:{resource-size}Example:
goatscaler.io/node-template/resource/hugepages-1Gi:2GiScale-in behavior
Why does node instant scaling fail to remove nodes?
Nodes are protected from scale-in under several conditions. Run kubectl describe node <node-name> and review events or annotations to narrow down the cause.
Pod-related blockers:
-
Scale-in threshold not met. The total resource requests of pods on the node exceed the configured scale-in threshold.
-
kube-system pods present. Pods running in the
kube-systemnamespace block scale-in. -
Mandatory scheduling constraints. Pods have affinity or topology rules that prevent them from running on other nodes.
-
PodDisruptionBudget (PDB) active. The pods are governed by a PodDisruptionBudget and the minimum available count has already been reached.
Node-level blockers:
-
Scale-in-only-empty-nodes is enabled, but the node is not empty. See Can node instant scaling be configured to only scale in empty nodes?
-
Node was added within the last 10 minutes. The add-on enforces a 10-minute cooldown after a node joins the pool before it becomes eligible for scale-in.
-
Offline nodes exist in the pool. An offline node is a running ECS instance that has no corresponding Kubernetes node object. The add-on pauses scale-in when offline nodes are detected. Version 0.5.3 and later includes automatic cleanup of offline nodes. Version 0.5.3 is in canary release — submit a ticket to request access. For earlier versions, delete the residual ECS instances manually. To check for offline nodes: on the Node Pools page, click Sync Node Pool, then click Details. On the Nodes tab, look for nodes in the offline state. To upgrade the add-on, see Add-ons.
What types of pods can prevent node instant scaling from removing a node?
Pods not managed by a native Kubernetes controller — such as Deployment, ReplicaSet, Job, or StatefulSet — may block scale-in. Pods that cannot be safely terminated or migrated to another node also block scale-in.
Custom scaling behavior
How do I control scale-in behavior on a per-pod basis?
Use the goatscaler.io/safe-to-evict annotation on the pod:
-
To prevent the node from being scaled in: set
"goatscaler.io/safe-to-evict": "false". -
To allow the node to be scaled in: set
"goatscaler.io/safe-to-evict": "true".
How do I force-delete specific nodes during a scale-in?
Add the taint goatscaler.io/force-to-delete:true:NoSchedule to the target node. After you add this taint, node instant scaling deletes the node immediately without checking pod status or draining pods.
Force deletion skips pod eviction and may cause service interruptions or data loss. Use with caution.
How do I prevent node instant scaling from removing specific nodes?
Add the annotation "goatscaler.io/scale-down-disabled": "true" to the node:
kubectl annotate node <nodename> goatscaler.io/scale-down-disabled=trueCan node instant scaling be configured to only scale in empty nodes?
Yes. Configure this at the node level or the cluster level. Node-level settings take precedence over cluster-level settings.
Node-level configuration:
Add a label to the specific node:
-
To enable (scale in only if empty):
goatscaler.io/scale-down-only-empty:true -
To disable (allow scale-in with pods):
goatscaler.io/scale-down-only-empty:false
Cluster-level configuration:
-
In the ACK consoleACK console, go to the Add-ons page.
-
Find ACK GOATScaler and follow the on-screen instructions to set
ScaleDownOnlyEmptyNodestotrueorfalse.
The node instant scaling add-on
Does the node instant scaling add-on update automatically?
No. ACK does not automatically update ACK GOATScaler, except during system-wide maintenance or major platform upgrades. Upgrade it manually on the Add-ons page in the ACK consoleACK console.
Why is node scaling not working on my ACK managed cluster even though role authorization is complete?
The most likely cause is a missing token. Node scaling on ACK managed clusters relies on a token named addon.aliyuncsmanagedautoscalerrole.token in a Secret within the kube-system namespace. ACK uses the cluster's Worker Role to authenticate autoscaling operations, and if this token is absent, scaling fails.
To verify, run the following command and check whether the token exists:
kubectl get secret -n kube-system | grep addon.aliyuncsmanagedautoscalerroleTo fix this, re-apply the required policy through the authorization wizard:
-
On the Clusters page, click the cluster name. In the left navigation pane, choose Nodes > Node Pools.
-
On the Node Pools page, click Enable next to Node Scaling.
-
Follow the on-screen instructions to authorize
KubernetesWorkerRoleand attach theAliyunCSManagedAutoScalerRolePolicysystem policy.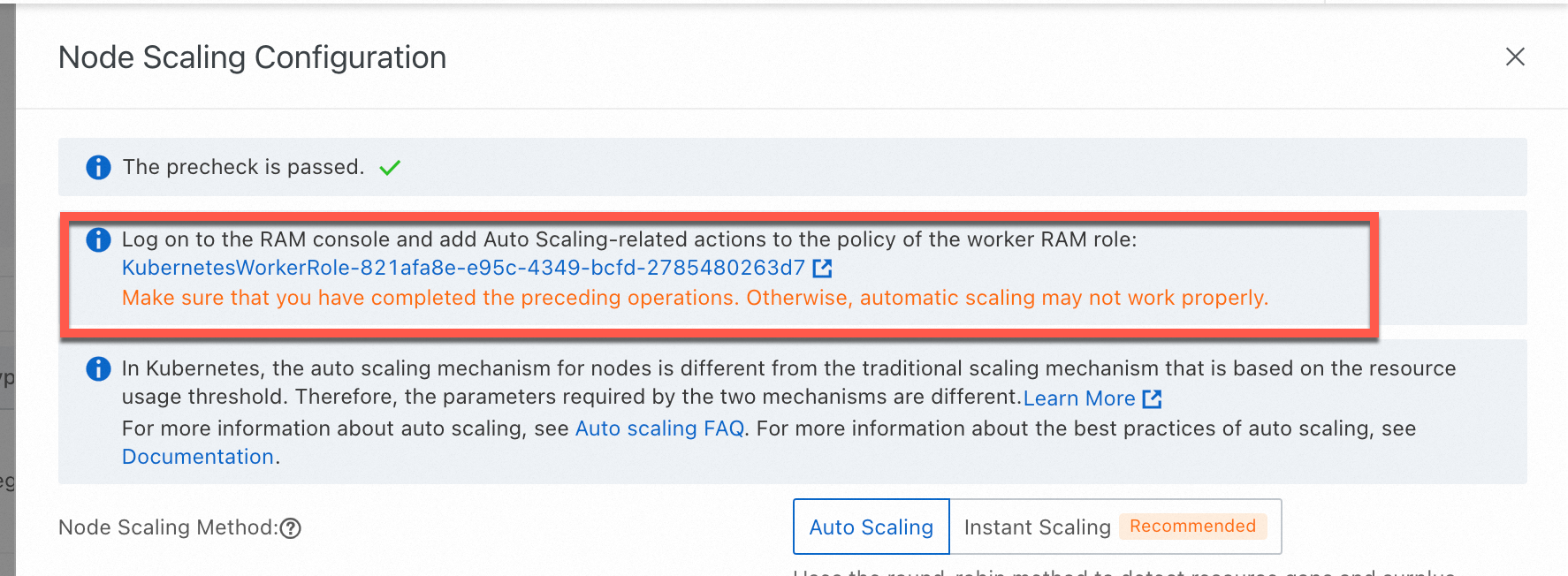
-
Manually restart the
cluster-autoscalerDeployment (node auto scaling) or theack-goatscalerDeployment (node instant scaling) in thekube-systemnamespace for the updated permissions to take effect.