Learn how to configure and use Spark's Dynamic Resource Allocation (DRA) to maximize cluster resource utilization, reduce idle resources, and improve task execution flexibility and system performance.
What is DRA?
DRA is a mechanism in Spark that dynamically adjusts the computing resources used by a job based on its workload. If an Executor is idle for an extended period, the Driver automatically releases it, returning the resources to the cluster. Alternatively, if tasks are waiting too long to be scheduled, the Driver requests more Executors. DRA helps Spark adapt to workload changes, preventing slow jobs from insufficient resources and resource waste from over-provisioning. This improves cluster resource utilization.
Resource allocation policy
When DRA is enabled and tasks are pending, the Driver requests additional Executors. If tasks are pending for more than spark.dynamicAllocation.schedulerBacklogTimeout (default: 1 second), the Driver starts requesting Executors in rounds. If tasks remain pending, the Driver continues to request Executors at each interval defined by spark.dynamicAllocation.sustainedSchedulerBacklogTimeout (default: 1 second). The number of Executors requested in each round increases exponentially, starting with 1, then 2, 4, and 8.
Resource release policy
The Driver automatically releases any Executor that is idle for more than spark.dynamicAllocation.executorIdleTimeout (default: 60 seconds) to optimize resource utilization.
Enable DRA
Spark's DRA mechanism is available in Standalone, YARN, Mesos, and Kubernetes modes, but is disabled by default. To enable DRA, set spark.dynamicAllocation.enabled to true and configure the following options:
Enable External Shuffle Service (ESS): Set
spark.shuffle.service.enabledtotrueand configure an External Shuffle Service (ESS) on each worker node in the cluster.Enable shuffled data tracking: Set
spark.dynamicAllocation.shuffleTracking.enabledtotrue. Spark tracks the location and status of shuffle data to ensure that the data is not lost and can be recomputed if necessary.Enable node decommissioning: Set
spark.decommission.enabledandspark.storage.decommission.shuffleBlocks.enabledtotrue. This ensures that when a node is decommissioned, Spark proactively copies its shuffle data blocks to other available nodes.Configure the ShuffleDataIO plug-in: Use
spark.shuffle.sort.io.plugin.classto specify the ShuffleDataIO plug-in class. This lets you customize shuffle data I/O and write shuffle data to different storage systems.
Configuration differs by mode:
Spark Standalone mode: Configure option 1 only.
Spark on Kubernetes mode:
Without Celeborn as a Remote Shuffle Service (RSS): Set
spark.dynamicAllocation.shuffleTracking.enabledtotrue(corresponds to option 2).Use Celeborn as an RSS:
Spark 3.5.0 or later: Configure
spark.shuffle.sort.io.plugin.classasorg.apache.spark.shuffle.celeborn.CelebornShuffleDataIO(corresponds to option 4).Spark versions earlier than 3.5.0: Apply a patch for the corresponding Spark version. No additional configuration is required. For details, see Support Spark Dynamic Allocation.
Spark 3.4.0 or later: Set
spark.dynamicAllocation.shuffleTracking.enabledtofalseto ensure idle Executors are released promptly.
The following sections provide examples of configuring Spark on Kubernetes, both with and without Celeborn as an RSS.
Prerequisites
The ack-spark-operator component is deployed.
NoteThese examples use
spark.jobNamespaces=["spark"]during deployment. If you use a different namespace, update thenamespacefield accordingly.The ack-spark-history-server component is deployed.
NoteThis example assumes you have created a Persistent Volume (PV) named
nas-pvand a Persistent Volume Claim (PVC) namednas-pvc. It also assumes the Spark History Server is configured to read the Spark Event Log from the/spark/event-logspath on NAS.(Optional) The ack-celeborn component is deployed.
Test data is prepared and uploaded to Object Storage Service (OSS).
Procedure
Without Celeborn
In this Spark 3.5.4 example, to enable DRA without Celeborn as an RSS, set the following parameters:
Enable dynamic resource allocation: Set
spark.dynamicAllocation.enabledto"true".Enable shuffled data tracking: To use DRA without an ESS dependency, set
spark.dynamicAllocation.shuffleTracking.enabledto"true".
Create a SparkApplication manifest file named
spark-pagerank-dra.yamlwith the following content:apiVersion: sparkoperator.k8s.io/v1beta2 kind: SparkApplication metadata: name: spark-pagerank-dra namespace: spark spec: type: Scala mode: cluster # Replace <SPARK_IMAGE> with your Spark image. image: <SPARK_IMAGE> mainApplicationFile: local:///opt/spark/examples/jars/spark-examples_2.12-3.5.4.jar mainClass: org.apache.spark.examples.SparkPageRank arguments: # Replace <OSS_BUCKET> with the name of your OSS bucket. - oss://<OSS_BUCKET>/data/pagerank_dataset.txt - "10" sparkVersion: 3.5.4 hadoopConf: # Use the oss:// format to access OSS data. fs.AbstractFileSystem.oss.impl: org.apache.hadoop.fs.aliyun.oss.OSS fs.oss.impl: org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem # The endpoint to access OSS. You must replace <OSS_ENDPOINT> with your OSS access endpoint. # For example, the internal endpoint to access OSS in the China (Beijing) region is oss-cn-beijing-internal.aliyuncs.com fs.oss.endpoint: <OSS_ENDPOINT> # Obtain OSS access credentials from environment variables. fs.oss.credentials.provider: com.aliyun.oss.common.auth.EnvironmentVariableCredentialsProvider sparkConf: # ==================== # Event logs # ==================== spark.eventLog.enabled: "true" spark.eventLog.dir: file:///mnt/nas/spark/event-logs # ==================== # Dynamic resource allocation # ==================== # Enable dynamic resource allocation spark.dynamicAllocation.enabled: "true" # Enable shuffled file tracing to implement dynamic resource allocation without relying on ESS. spark.dynamicAllocation.shuffleTracking.enabled: "true" # The initial value of the number of executors. spark.dynamicAllocation.initialExecutors: "1" # The minimum number of executors. spark.dynamicAllocation.minExecutors: "0" # The maximum number of executors. spark.dynamicAllocation.maxExecutors: "5" # The idle timeout period of the executor. If the timeout period is exceeded, the executor is released. spark.dynamicAllocation.executorIdleTimeout: 60s # The idle timeout period of the executor that cached the data block. If the timeout period is exceeded, the executor is released. The default value is infinity, which specifies that the data block is not released. # spark.dynamicAllocation.cachedExecutorIdleTimeout: # When a job exceeds the specified scheduled time, additional executors are requested. spark.dynamicAllocation.schedulerBacklogTimeout: 1s # After each time interval, subsequent batches of executors are requested. spark.dynamicAllocation.sustainedSchedulerBacklogTimeout: 1s driver: cores: 1 coreLimit: 1200m memory: 512m envFrom: - secretRef: name: spark-oss-secret volumeMounts: - name: nas mountPath: /mnt/nas serviceAccount: spark-operator-spark executor: cores: 1 coreLimit: "2" memory: 8g envFrom: - secretRef: name: spark-oss-secret volumeMounts: - name: nas mountPath: /mnt/nas volumes: - name: nas persistentVolumeClaim: claimName: nas-pvc restartPolicy: type: NeverNoteThe Spark image in the example above must include the Hadoop OSS SDK dependency. Use the following Dockerfile to build the image and push it to an image registry:
ARG SPARK_IMAGE=spark:3.5.4 FROM ${SPARK_IMAGE} # Add dependency for Hadoop Aliyun OSS support ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aliyun/3.3.4/hadoop-aliyun-3.3.4.jar ${SPARK_HOME}/jars ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/com/aliyun/oss/aliyun-sdk-oss/3.17.4/aliyun-sdk-oss-3.17.4.jar ${SPARK_HOME}/jars ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/org/jdom/jdom2/2.0.6.1/jdom2-2.0.6.1.jar ${SPARK_HOME}/jarsRun the following command to submit the Spark job.
kubectl apply -f spark-pagerank-dra.yamlExpected output:
sparkapplication.sparkoperator.k8s.io/spark-pagerank-dra createdCheck the Driver logs.
kubectl logs -n spark spark-pagerank-dra-driver | grep -a2 -b2 "Going to request"Expected output:
3544-25/01/16 03:26:04 INFO SparkKubernetesClientFactory: Auto-configuring K8s client using current context from users K8s config file 3674-25/01/16 03:26:06 INFO Utils: Using initial executors = 1, max of spark.dynamicAllocation.initialExecutors, spark.dynamicAllocation.minExecutors and spark.executor.instances 3848:25/01/16 03:26:06 INFO ExecutorPodsAllocator: Going to request 1 executors from Kubernetes for ResourceProfile Id: 0, target: 1, known: 0, sharedSlotFromPendingPods: 2147483647. 4026-25/01/16 03:26:06 INFO ExecutorPodsAllocator: Found 0 reusable PVCs from 0 PVCs 4106-25/01/16 03:26:06 INFO BasicExecutorFeatureStep: Decommissioning not enabled, skipping shutdown script -- 10410-25/01/16 03:26:15 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0) (192.168.95.190, executor 1, partition 0, PROCESS_LOCAL, 9807 bytes) 10558-25/01/16 03:26:15 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.95.190:34327 (size: 12.5 KiB, free: 4.6 GiB) 10690:25/01/16 03:26:16 INFO ExecutorPodsAllocator: Going to request 1 executors from Kubernetes for ResourceProfile Id: 0, target: 2, known: 1, sharedSlotFromPendingPods: 2147483647. 10868-25/01/16 03:26:16 INFO ExecutorAllocationManager: Requesting 1 new executor because tasks are backlogged (new desired total will be 2 for resource profile id: 0) 11030-25/01/16 03:26:16 INFO ExecutorPodsAllocator: Found 0 reusable PVCs from 0 PVCsThe logs show that the Driver requested one Executor at
03:26:06and another at03:26:16.Verify the job in the Spark History Server. For access instructions, see Use Spark History Server to view information about Spark jobs.
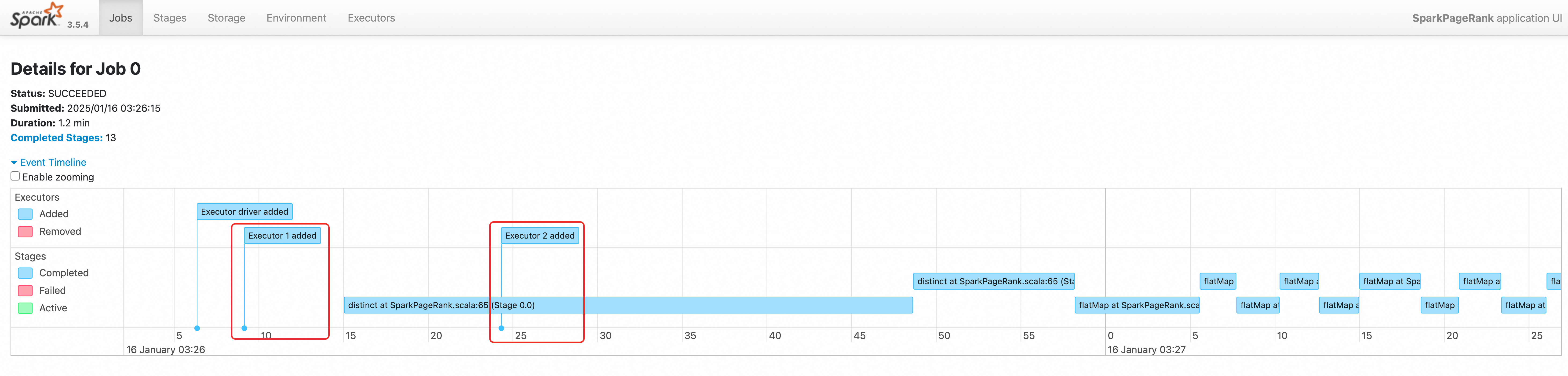
The job's event timeline confirms that two Executors were created sequentially.
With Celeborn
In this Spark 3.5.4 example, to enable DRA with Celeborn as an RSS, set the following parameters:
Enable dynamic resource allocation: Set
spark.dynamicAllocation.enabledto"true".Enable DRA support (for Spark 3.5.0 or later): Set
spark.shuffle.sort.io.plugin.classtoorg.apache.spark.shuffle.celeborn.CelebornShuffleDataIO.Release idle Executors promptly: Set
spark.dynamicAllocation.shuffleTracking.enabledto"false".
Create a SparkApplication manifest file named
spark-pagerank-celeborn-dra.yamlwith the following content:apiVersion: sparkoperator.k8s.io/v1beta2 kind: SparkApplication metadata: name: spark-pagerank-celeborn-dra namespace: spark spec: type: Scala mode: cluster # Replace <SPARK_IMAGE> with your Spark image. The image must contain JindoSDK. image: <SPARK_IMAGE> mainApplicationFile: local:///opt/spark/examples/jars/spark-examples_2.12-3.5.4.jar mainClass: org.apache.spark.examples.SparkPageRank arguments: # Replace <OSS_BUCKET> with the name of your OSS bucket. - oss://<OSS_BUCKET>/data/pagerank_dataset.txt - "10" sparkVersion: 3.5.4 hadoopConf: # Use the oss:// format to access OSS data. fs.AbstractFileSystem.oss.impl: org.apache.hadoop.fs.aliyun.oss.OSS fs.oss.impl: org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem # The endpoint to access OSS. You must replace <OSS_ENDPOINT> with your OSS access endpoint. # For example, the internal endpoint to access OSS in the China (Beijing) region is oss-cn-beijing-internal.aliyuncs.com fs.oss.endpoint: <OSS_ENDPOINT> # Obtain OSS access credentials from environment variables. fs.oss.credentials.provider: com.aliyun.oss.common.auth.EnvironmentVariableCredentialsProvider sparkConf: # ==================== # Event logs # ==================== spark.eventLog.enabled: "true" spark.eventLog.dir: file:///mnt/nas/spark/event-logs # ==================== # Celeborn # Ref: https://github.com/apache/celeborn/blob/main/README.md#spark-configuration # ==================== # Shuffle manager class name changed in 0.3.0: # before 0.3.0: `org.apache.spark.shuffle.celeborn.RssShuffleManager` # since 0.3.0: `org.apache.spark.shuffle.celeborn.SparkShuffleManager` spark.shuffle.manager: org.apache.spark.shuffle.celeborn.SparkShuffleManager # Must use kryo serializer because java serializer do not support relocation spark.serializer: org.apache.spark.serializer.KryoSerializer # Configure this parameter based on the number of replicas on the Celeborn master node. spark.celeborn.master.endpoints: celeborn-master-0.celeborn-master-svc.celeborn.svc.cluster.local,celeborn-master-1.celeborn-master-svc.celeborn.svc.cluster.local,celeborn-master-2.celeborn-master-svc.celeborn.svc.cluster.local # options: hash, sort # Hash shuffle writer use (partition count) * (celeborn.push.buffer.max.size) * (spark.executor.cores) memory. # Sort shuffle writer uses less memory than hash shuffle writer, if your shuffle partition count is large, try to use sort hash writer. spark.celeborn.client.spark.shuffle.writer: hash # We recommend setting `spark.celeborn.client.push.replicate.enabled` to true to enable server-side data replication # If you have only one worker, this setting must be false # If your Celeborn is using HDFS, it's recommended to set this setting to false spark.celeborn.client.push.replicate.enabled: "false" # Support for Spark AQE only tested under Spark 3 spark.sql.adaptive.localShuffleReader.enabled: "false" # we recommend enabling aqe support to gain better performance spark.sql.adaptive.enabled: "true" spark.sql.adaptive.skewJoin.enabled: "true" # If the Spark version is 3.5.0 or later, configure this parameter to support dynamic resource allocation. spark.shuffle.sort.io.plugin.class: org.apache.spark.shuffle.celeborn.CelebornShuffleDataIO spark.executor.userClassPathFirst: "false" # ==================== # Dynamic resource allocation # Ref: https://spark.apache.org/docs/latest/job-scheduling.html#dynamic-resource-allocation # ==================== # Enable dynamic resource allocation spark.dynamicAllocation.enabled: "true" # Enable shuffled file tracing and implement dynamic resource allocation without relying on ESS. # If the Spark version is 3.4.0 or later, we recommend that you disable this feature when you use Celeborn as RSS. spark.dynamicAllocation.shuffleTracking.enabled: "false" # The initial value of the number of executors. spark.dynamicAllocation.initialExecutors: "1" # The minimum number of executors. spark.dynamicAllocation.minExecutors: "0" # The maximum number of executors. spark.dynamicAllocation.maxExecutors: "5" # The idle timeout period of the executor. If the timeout period is exceeded, the executor is released. spark.dynamicAllocation.executorIdleTimeout: 60s # The idle timeout period of the executor that cached the data block. If the timeout period is exceeded, the executor is released. The default value is infinity, which specifies that the data block is not released. # spark.dynamicAllocation.cachedExecutorIdleTimeout: # When a job exceeds the specified scheduled time, additional executors are requested. spark.dynamicAllocation.schedulerBacklogTimeout: 1s # After each time interval, subsequent batches of executors are requested. spark.dynamicAllocation.sustainedSchedulerBacklogTimeout: 1s driver: cores: 1 coreLimit: 1200m memory: 512m envFrom: - secretRef: name: spark-oss-secret volumeMounts: - name: nas mountPath: /mnt/nas serviceAccount: spark-operator-spark executor: cores: 1 coreLimit: "1" memory: 4g envFrom: - secretRef: name: spark-oss-secret volumeMounts: - name: nas mountPath: /mnt/nas volumes: - name: nas persistentVolumeClaim: claimName: nas-pvc restartPolicy: type: NeverNoteThe Spark image in the example above must include the Hadoop OSS SDK and Celeborn client dependencies. Use the following Dockerfile to build the image and push it to an image registry:
ARG SPARK_IMAGE=spark:3.5.4 FROM ${SPARK_IMAGE} # Add dependency for Hadoop Aliyun OSS support ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aliyun/3.3.4/hadoop-aliyun-3.3.4.jar ${SPARK_HOME}/jars ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/com/aliyun/oss/aliyun-sdk-oss/3.17.4/aliyun-sdk-oss-3.17.4.jar ${SPARK_HOME}/jars ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/org/jdom/jdom2/2.0.6.1/jdom2-2.0.6.1.jar ${SPARK_HOME}/jars # Add dependency for Celeborn ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/org/apache/celeborn/celeborn-client-spark-3-shaded_2.12/0.5.3/celeborn-client-spark-3-shaded_2.12-0.5.3.jar ${SPARK_HOME}/jarsRun the following command to submit the SparkApplication.
kubectl apply -f spark-pagerank-celeborn-dra.yamlExpected output:
sparkapplication.sparkoperator.k8s.io/spark-pagerank-celeborn-dra createdCheck the Driver logs.
kubectl logs -n spark spark-pagerank-celeborn-dra-driver | grep -a2 -b2 "Going to request"Expected output:
3544-25/01/16 03:51:28 INFO SparkKubernetesClientFactory: Auto-configuring K8s client using current context from users K8s config file 3674-25/01/16 03:51:30 INFO Utils: Using initial executors = 1, max of spark.dynamicAllocation.initialExecutors, spark.dynamicAllocation.minExecutors and spark.executor.instances 3848:25/01/16 03:51:30 INFO ExecutorPodsAllocator: Going to request 1 executors from Kubernetes for ResourceProfile Id: 0, target: 1, known: 0, sharedSlotFromPendingPods: 2147483647. 4026-25/01/16 03:51:30 INFO ExecutorPodsAllocator: Found 0 reusable PVCs from 0 PVCs 4106-25/01/16 03:51:30 INFO CelebornShuffleDataIO: Loading CelebornShuffleDataIO -- 11796-25/01/16 03:51:41 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0) (192.168.95.163, executor 1, partition 0, PROCESS_LOCAL, 9807 bytes) 11944-25/01/16 03:51:42 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.95.163:37665 (size: 13.3 KiB, free: 2.1 GiB) 12076:25/01/16 03:51:42 INFO ExecutorPodsAllocator: Going to request 1 executors from Kubernetes for ResourceProfile Id: 0, target: 2, known: 1, sharedSlotFromPendingPods: 2147483647. 12254-25/01/16 03:51:42 INFO ExecutorAllocationManager: Requesting 1 new executor because tasks are backlogged (new desired total will be 2 for resource profile id: 0) 12416-25/01/16 03:51:42 INFO ExecutorPodsAllocator: Found 0 reusable PVCs from 0 PVCsThe logs show that the Driver requested one Executor at
03:51:30and another at03:51:42.Verify the job in the Spark History Server. For access instructions, see Use Spark History Server to view information about Spark jobs.
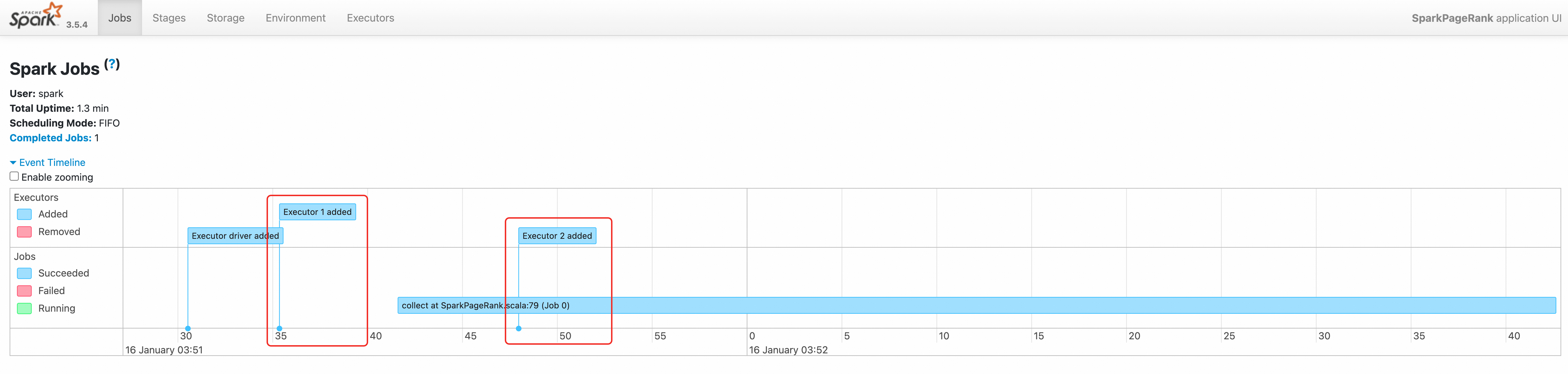
The job's event timeline confirms that two Executors were created sequentially.