Classic Load Balancer (CLB) offers 99.95% multi-zone service availability and 99.90% single-zone service availability. To protect against region-level failures, deploy CLB instances across multiple zones or regions and use Alibaba Cloud DNS to route traffic across deployments.
How it works
CLB instances run in clusters to synchronize sessions and eliminate single points of failure (SPOFs), ensuring redundancy and service stability.
Layer 4: CLB uses the open-source Linux Virtual Server (LVS) software and the Keepalived framework to distribute traffic. Requests from the internet reach the LVS cluster through the equal-cost multi-path (ECMP) routing mechanism. Each physical server in the cluster uses multicast packets to synchronize sessions across all nodes.
Layer 7: CLB uses Tengine — a high-performance web server developed by Taobao and built on NGINX. The LVS cluster continuously health-checks the Tengine cluster and removes unhealthy nodes to maintain Layer 7 availability.
Session synchronization protects persistent connections from server failures within a cluster, but does not cover short-lived connections or connections where the TCP three-way handshake fails before synchronization triggers. Add a retry mechanism to your application to reduce the impact of such failures on users.
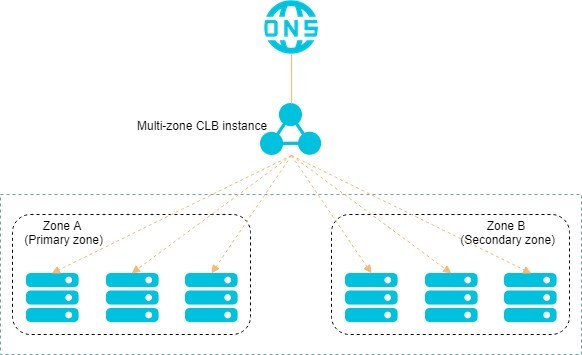
Resilience to zone failure
CLB supports cross-zone deployment in most regions. Deploy a CLB instance across two zones in the same region — one primary zone and one secondary zone. When the entire CLB cluster in the primary zone becomes unavailable (for example, due to a power outage or connectivity loss), CLB automatically fails over to the secondary zone within 30 seconds. When the primary zone recovers, CLB automatically switches back.
A failover is triggered only when the entire CLB cluster in the primary zone is completely unavailable. A single instance failure in the primary zone does not trigger a failover.
What happens during a failover:
| Aspect | Behavior |
|---|---|
| Detection and response | CLB detects the primary zone failure and initiates the failover automatically. No action is required on your part. |
| Failover time | Traffic switches to the secondary zone within 30 seconds. |
| Recovery | When the primary zone recovers, CLB automatically switches traffic back. |
Best practices for cross-zone deployment:
Create CLB instances in regions that support primary/secondary zone deployment.
Place the majority of your Elastic Compute Service (ECS) instances in the primary zone to minimize latency.
Deploy a small number of ECS instances in the secondary zone so traffic can be served there if the primary zone fails.
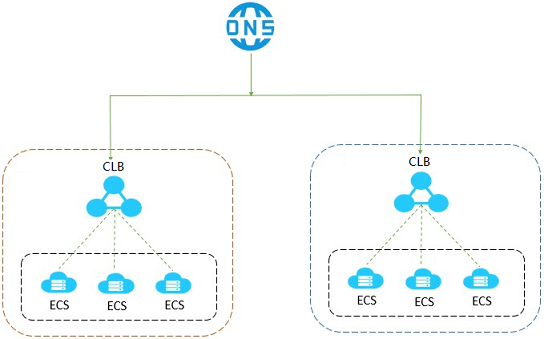
Resilience to region failure
Zone-level failover does not protect against scenarios where a CLB instance itself becomes unavailable — for example, due to a network attack or misconfiguration. In those cases, no automatic failover occurs because the instance is no longer reachable.
To protect against region-level failures, deploy CLB instances and ECS instances across multiple zones within a region or across multiple regions, then use Alibaba Cloud DNS to route requests across your deployments.
High availability of backend ECS instances
CLB continuously monitors backend ECS instances through health checks. When an unhealthy instance is detected, CLB stops routing new requests to it and redirects traffic to healthy instances. After the instance recovers, CLB automatically resumes sending requests to it.
Enable and configure the health check feature to make sure CLB can accurately detect backend instance availability. For configuration details, see Configure and manage health checks.
For an overview of how health checks work, see Health check overview.