Collect text logs from ECS instances, on-premises servers, or third-party cloud hosts into Simple Log Service using LoongCollector (Logtail). Two modes are available: continuous collection (real-time incremental) and one-time collection (batch historical import).
Select a collection mode
Scenario | Recommended mode |
Logs are written continuously; real-time monitoring and alerting required. | Continuous collection |
Import archived historical files once. | One-time collection |
System or data migration; backfilling historical data. | One-time collection |
Ad-hoc investigation of logs from a specific time period. | One-time collection |
LoongCollector collects only incremental logs by default. To collect existing static files, use one-time collection mode.
Usage notes
Supported operating systems and architectures:
LoongCollector supports Linux only. For Windows hosts, use Logtail.
For new deployments, use LoongCollector — the next-generation Logtail replacement. Install one or the other, not both.
Computing resource requirements:
CPU: Minimum 0.4 cores.
Memory: Minimum 300 MB.
Keep usage below 80% of the limit. Actual consumption depends on collection speed, directory and file count, and send queue backlog.
Permission requirements:
If you use a Resource Access Management (RAM) user, you must grant the
AliyunLogFullAccessandAliyunECSFullAccesspermissions. For fine-grained authorization, see Appendix: Custom permission policies.
Collection configuration workflow
Preparations: Create a project (resource isolation) and a logstore (log storage).
Configure a machine group (Install LoongCollector): Install LoongCollector on your servers and add them to a machine group.
Create and configure log collection rules:
Global and input configurations: Define the name of the collection configuration and the source and scope of log collection.
Log processing and structuring: Configure processing rules based on the log format.
Multiline logs: For logs that span multiple lines (such as Java exception stacks), configure a regular expression to identify the start of each log and merge consecutive lines into a single entry.
Structured parsing: Use parsing plugins (regular expression, separator, or NGINX pattern) to extract raw strings into structured key-value pairs for independent query and analysis.
Log filtering: Configure blacklists and content filters to exclude redundant data and reduce storage costs.
Log categorization: Use topics to distinguish logs from different applications, servers, or path sources.
Query and analysis configuration: Full-text index is enabled by default for keyword searches. Enable field index for precise queries on structured fields.
Verification and troubleshooting: Verify that logs are collected. For issues such as no data, heartbeat failures, or parsing errors, see the FAQ.
Preparations
Create a project and logstore to store logs. If these already exist, skip to Configure a machine group (Install LoongCollector).
Create a project
Create a logstore
Click the project name to go to the target project.
In the navigation pane on the left, choose
 and click +.
and click +.On the Create Logstore page, complete the following core configurations:
Logstore Name: Must be unique within the project. Cannot be changed after creation.
Logstore Type: Select Standard or Query based on your requirements.
Billing Mode:
Pay-by-feature: Storage, indexing, and read/write operations are charged individually. Best for small-scale or unpredictable usage.
Pay-by-ingested-data: Billed by raw data volume. Includes 30-day free storage plus complimentary data transformation and delivery. Ideal for ~30-day retention or complex processing pipelines.
Data Retention Period: Log retention in days (1–3,650). 3,650 = permanent. Default: 30 days.
Keep the default settings for other configurations and click OK. For more information about other configurations, see Manage Logstores.
Step 1: Configure a machine group (Install LoongCollector)
After you complete the Preparations, install LoongCollector on your servers and add them to a machine group.
These steps apply only to ECS instances in the same account and region as the SLS project.
For cross-account, cross-region, or on-premises scenarios, see Install and configure LoongCollector.
Procedure:
On the
 Logstores page, click the
Logstores page, click the  icon before the target logstore name to expand it.
icon before the target logstore name to expand it.Click the
 icon next to Data Collection, and in the Quick Data Import dialog box, select a text log collection template (such as Single Line - Text Log) and click Integrate Now.
icon next to Data Collection, and in the Quick Data Import dialog box, select a text log collection template (such as Single Line - Text Log) and click Integrate Now.All text log templates share the same configuration and differ only in parsing plugins. You can modify the configuration later.
On the Machine Group Configurations page, configure the following parameters:
Scenario: Servers
Installation Environment: ECS
Select Machine Group: Based on the LoongCollector installation status and machine group configuration of the target server, select the corresponding operation:
If LoongCollector is already installed and added to a machine group, select the machine group from Source Machine Group and move it to Applied Server Groups.
If LoongCollector is not installed, click Create Machine Group:
Follow these steps to install LoongCollector automatically and create a machine group.
The system lists ECS instances in the same region as the project. Select the instances to collect logs from.
Click Install and Create Machine Group. The system automatically installs LoongCollector on the selected ECS instances.
Configure the machine group Name and click OK.
NoteIf the installation fails or remains in a waiting state, check whether the ECS region is the same as the project region.
To add a server with LoongCollector already installed to an existing machine group, see the FAQ How do I add a server to an existing machine group?
Check the heartbeat status: Click Next. The Machine Group Heartbeat section appears. Check the Heartbeat status. If it is OK, the machine group connection is normal. Click Next to go to the Logtail configuration page.
If the status is FAIL, wait about two minutes and refresh. If still FAIL, see Machine group heartbeat is FAIL for further troubleshooting.
Step 2: Create and configure log collection rules
After completing LoongCollector installation and machine group configuration, go to the Logtail Configuration page to define collection and processing rules.
1. Global and input configurations
Define the name of the collection configuration and the source and scope of log collection.
Global Configurations:
Configuration Name: A custom name for the collection configuration. This name must be unique within the project and cannot be changed after it is created. Naming conventions:
Can contain only lowercase letters, digits, hyphens (-), and underscores (_).
Must start and end with a lowercase letter or a digit.
Input Configurations:
Type: Text Log Collection.
File Path: The log collection path.
Linux: The path must start with a forward slash (/). For example,
/data/mylogs/**/*.logindicates all files with the .log extension in the/data/mylogsdirectory and its subdirectories.Windows: The path must start with a drive letter. For example,
C:\Program Files\Intel\**\*.Log.
Maximum Directory Monitoring Depth: The maximum depth of directories matched by the
**wildcard character in the File Path. The default value is 0, which indicates that only the current directory is monitored.
2. Log processing and structuring
Configure processing rules to structure raw logs into searchable key-value pairs. First, add a log sample:
In the Processor Configurations section of the Logtail Configuration page, click Add Sample Log and enter a sample log. The system identifies the format and generates parsing rules automatically.
Use case 1: Process multiline logs (such as Java stack logs)
Logs such as Java exception stacks span multiple lines. Without multiline mode, they are split into incomplete records. Enable multiline mode and set a Regex to Match First Line to merge consecutive lines into a single log.
Example:
Raw log without any processing | In default collection mode, each line is a separate log, breaking the stack trace and losing context | With multiline mode enabled, a Regex to Match First Line identifies the complete log, preserving its full semantic structure. |
|
|
|



Procedure: In the Processor Configurations section of the Logtail Configuration page, enable Multi-line Mode:
For Type, select Custom or Multi-line JSON.
Custom: For raw logs with a variable format, configure a Regex to Match First Line to identify the starting line of each log.
Regex to Match First Line: Automatically generate or manually enter a regular expression that matches a complete line of data. For example, the regular expression for the preceding example is
\[\d+-\d+-\w+:\d+:\d+,\d+]\s\[\w+]\s.*.Automatic generation: Click Generate. Then, in the Log Sample text box, select the log content that you want to extract and click Automatically Generate.
Manual entry: Click Manually Enter Regular Expression. After you enter the expression, click Validate.
Multi-line JSON: SLS automatically handles line breaks within a single raw log if the log is in standard JSON format.
Processing Method If Splitting Fails:
Discard: Discards a text segment if it does not match the start-of-line rule.
Retain Single Line: Retains unmatched text on separate lines.
Use case 2: Structured logs
Raw logs in unstructured formats (such as NGINX access logs) are hard to query directly. SLS parsing plugins convert them into structured key-value pairs for analysis and alerting.
Example:
Raw log | Structured log |
| |
Procedure: In the Processor Configurations section of the Logtail Configuration page
Add a parsing plugin: Click Add Processor and configure a plugin such as regular expression parsing, separator parsing, or JSON parsing based on the actual format. This example uses NGINX log collection and selects .
NGINX Log Configuration: Copy the
log_formatdefinition from the NGINX server configuration file (nginx.conf) and paste it into this text box.Example:
log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$request_time $request_length ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent"';ImportantThe format definition here must be exactly the same as the format that generates the logs on the server. Otherwise, log parsing fails.
Description of common configuration parameters: The following parameters appear in multiple data parsing plugins and have a unified function and usage.
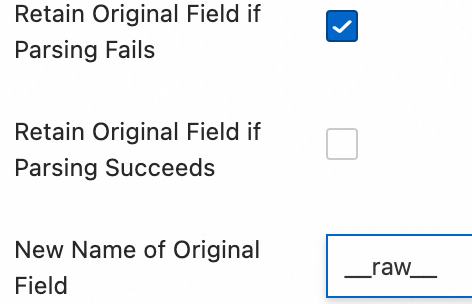
Original Field: The source field to parse. Default:
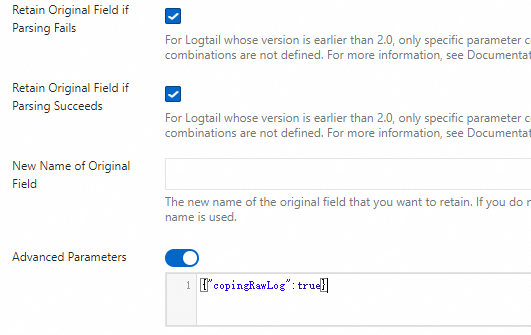
content(the entire collected log entry).Retain Original Field if Parsing Fails: Preserves the original log content when parsing fails (for example, due to a format mismatch).
Retain Original Field if Parsing Succeeds: Retains the original log content even after successful parsing.
3. Log filtering
Low-value logs (DEBUG, INFO) waste storage, increase costs, reduce query efficiency, and risk data exposure. Use filtering to collect only relevant logs.
Reduce costs with content filtering
Filter fields based on log content, such as collecting only logs where the level is WARNING or ERROR.
Example:
Raw log without any processing | Collect only |
| |
Procedure: In the Processor Configurations section of the Logtail Configuration page
Click Add Processor and select :
Field Name: The log field to use for filtering.
Field Value: The regular expression used for filtering. Only full matches are supported, not partial keyword matches.
Control collection scope with a blacklist
Use a blacklist to exclude specified directories or files, preventing irrelevant or sensitive logs from being uploaded.
Procedure: In the section of the Logtail Configuration page, enable Collection Blacklist and click Add.
Supports full and wildcard matching for directories and filenames. The only supported wildcard characters are the asterisk (*) and the question mark (?).
File Path Blacklist: Specifies the file paths to exclude. Examples:
/home/admin/private*.log: Ignores all files in the/home/admin/directory that start with private and end with .log./home/admin/private*/*_inner.log: Ignores files that end with _inner.log within directories that start with private under the/home/admin/directory.
File Blacklist: A list of filenames to ignore during collection. Example:
app_inner.log: Ignores all files namedapp_inner.logduring collection.
Directory Blacklist: Directory paths cannot end with a forward slash (/). Examples:
/home/admin/dir1/: The directory blacklist will not take effect./home/admin/dir*: Ignores files in all subdirectories that start with dir under the/home/admin/directory during collection./home/admin/*/dir: Ignores all files in subdirectories named dir at the second level of the/home/admin/directory. For example, files in the/home/admin/a/dirdirectory are ignored, but files in the/home/admin/a/b/dirdirectory are collected.
4. Log categorization
When logs from multiple applications or instances share the same format but have different paths (for example, /apps/app-A/run.log and /apps/app-B/run.log), topics help distinguish their sources for precise queries within a single logstore.
Procedure: : Select a method for generating topics. The following three types are supported:
Machine Group Topic: When a collection configuration is applied to multiple machine groups, LoongCollector uses the server's machine group name as the
__topic__field. Suitable for dividing logs by host.Custom: Uses the format
customized://<custom_topic_name>, such ascustomized://app-login. This format is suitable for static topic use cases with fixed business identifiers.File Path Extraction: Extract key information from the log file path to dynamically mark the log source. This is suitable when multiple users or applications share the same log filename but differ in path:
/data/logs ├── userA │ └── serviceA │ └── service.log ├── userB │ └── serviceA │ └── service.log └── userC └── serviceA └── service.logConfigure File Path Extraction and use a regular expression to extract key information from the full path. The matched result is then uploaded to the logstore as the topic.
File path extraction rule: Based on regular expression capturing groups
When you configure a regular expression, the system automatically determines the output field format based on the number and naming of capturing groups. The rules are as follows:
In the regular expression for a file path, you must escape the forward slash (/).
Capturing group type
Use case
Generated field
Regex example
Matching path example
Generated field example
Single capturing group (only one
(.*?))Only one dimension is needed to distinguish the source (such as username or environment)
Generates the
__topic__field\/logs\/(.*?)\/app\.log/logs/userA/app.log__topic__: userAMultiple capturing groups - unnamed (multiple
(.*?))Multiple dimensions are needed to distinguish the source, but no semantic tags are required
Generates a tag field
__tag__:__topic_{i}__, where{i}is the ordinal number of the capturing group\/logs\/(.*?)\/(.*?)\/app\.log/logs/userA/svcA/app.log__tag__:__topic_1__userA__tag__:__topic_2__svcAMultiple capturing groups - named (using
(?P<name>.*?)Multiple dimensions are needed to distinguish the source, and the field meanings should be clear for easy querying and analysis
Generates a tag field
__tag__:{name}\/logs\/(?P<user>.*?)\/(?P<service>.*?)\/app\.log/logs/userA/svcA/app.log__tag__:user:userA;__tag__:service:svcA
5. Output configuration
By default, all logs are sent to the current logstore with lz4 compression. To send logs from the same source to different logstores:
Dynamic distribution to multiple targets
Sending logs to multiple targets is available only for LoongCollector 3.0.0 and later. This feature is not supported by Logtail.
Up to five output targets can be configured.
After you configure multiple output targets, the collection configuration is no longer visible in the collection configuration list of the current logstore. To view, modify, or delete the multi-target distribution configuration, see How do I manage multi-target distribution configurations?
Procedure: In the Output Configurations section of the Logtail Configuration page
Click
 to expand the output configuration.
to expand the output configuration.Click Add Output Targets and configure the following settings:
Logstore: Select the target logstore.
Compression Method: Select lz4 or zstd.
Route Settings: Routes logs based on tag fields. Logs that match the routing rules are sent to the target logstore. If this configuration is empty, all collected logs are sent to the target logstore.
Tag Name: The name of the tag field used for routing. Enter the field name directly, such as
__path__, without the__tag__:prefix. Tag fields fall into two categories:For more information about tags, see Manage LoongCollector collection tags.
Agent-related: These tags are related to the collection agent and are independent of any plugins. Examples include
__hostname__and__user_defined_id__.Input plugin-related: These tags depend on the input plugin, which adds and enriches the log with relevant information. Examples include
__path__for file collection, and_pod_name_and_container_name_for Kubernetes collection.
Tag Value: If a log's tag value matches this value, the log is sent to this target logstore.
Discard this tag?: If you enable this option, this tag field is removed from the uploaded logs.
Step 3: Query and analysis configuration
After configuring log processing and plugins, click Next to go to the Query and Analysis Configurations page:
Full-text index is enabled by default, which supports keyword searches on raw log content.
For precise queries by field, wait for the Preview Data to load, and then click Automatic Index Generation. SLS generates a field index based on the first entry in the preview data.
After the configuration is complete, click Next to finish setting up the entire collection process.
Step 4: Verification and troubleshooting
After saving the configuration and applying it to the machine group, verify log collection with the following checklist.
Verification checklist
Confirm that the log file has new content: LoongCollector collects only incremental logs. Run
tail -f /path/to/your/log/fileand trigger a business operation to ensure that new logs are being written.Check the LoongCollector status:
sudo /etc/init.d/loongcollectord status.Check the machine group heartbeat: Go to the
 Resources > Machine Groups page. Click the target machine group name. In the section, check the Heartbeat status.
Resources > Machine Groups page. Click the target machine group name. In the section, check the Heartbeat status.If the heartbeat is OK, the machine group is connected to the SLS project.
If the heartbeat is FAIL, see Machine group heartbeat is FAIL for troubleshooting.
Query logs: Go to the query and analysis page of the target logstore. Click Search & Analyze (the default time range is the last 15 minutes) and check whether new logs are flowing in.
Troubleshooting common issues
Machine group heartbeat is FAIL
Check the user ID: If your server is not an ECS instance, or if the ECS instance and the project belong to different Alibaba Cloud accounts, check whether the correct user ID exists in the specified directory. If it does not, run the following command to create it manually.
Linux: Run the
cd /etc/ilogtail/users/ && touch <uid>command to create the user ID file.Windows: Go to the
C:\LogtailData\users\directory and create an empty file named<uid>.
Check the machine group ID: If you used a custom ID when you created the machine group, check whether the
user_defined_idfile exists in the specified directory. If it exists, check whether the content of the file is consistent with the custom ID configured for the machine group.Linux:
# Configure a custom ID. If the directory does not exist, create it manually. echo "user-defined-1" > /etc/ilogtail/user_defined_idWindows: In the
C:\LogtailDatadirectory, create a new file nameduser_defined_idand write the custom ID to it. (If the directory does not exist, create it manually.)
If both the user ID and the machine group ID are configured correctly, see Troubleshooting LoongCollector (Logtail) machine group issues for further investigation.
No data is collected
Check for incremental logs: LoongCollector (Logtail) collects only incremental logs. If no new logs are added to the target file, no data is collected.
Check the machine group heartbeat status: Go to the
 Resources > Machine Groups page. Click the target machine group name. In the section, check the Heartbeat status.
Resources > Machine Groups page. Click the target machine group name. In the section, check the Heartbeat status.If the heartbeat is OK, the machine group is connected to the SLS project.
If the heartbeat is FAIL, see Machine group heartbeat is FAIL for troubleshooting.
Confirm the collection configuration is applied to the machine group: A collection configuration that is not applied to a machine group cannot collect logs.
Go to the
 Resources > Machine Groups page, click the target machine group name, and go to the Machine Group Configurations page.
Resources > Machine Groups page, click the target machine group name, and go to the Machine Group Configurations page.On the page, view Manage Configuration. The left side shows All Logtail Configurations, and the right side shows Applied Logtail Configs. If the target LoongCollector (Logtail) collection configuration has been moved to the applied area on the right, the configuration has been successfully applied to the target machine group.
If the target LoongCollector (Logtail) collection configuration has not been moved to the applied area on the right, click Modify. In the All Logtail Configurations list on the left, select the target LoongCollector (Logtail) configuration name, click
 to move it to the applied area on the right, and then click Save.
to move it to the applied area on the right, and then click Save.
Log collection errors or format errors
Network and basic configuration are normal. The problem is likely a mismatch between log content and parsing rules:
On the Logtail Configuration page, click the name of the LoongCollector (Logtail) configuration that has a collection error. On the Log Collection Error tab, click Select Time Range to set the query time.
In the section, view the alarm metric of the error log and find the corresponding solution in Common errors in data collection.
Limitations
Item | Limitations |
Length of a single log | The default limit is 512 KB. Adjust this using the max_read_buffer_size startup parameter, up to a maximum of 8 MB. For more information, see Logtail network types, startup parameters, and configuration. After a multiline log is split by the Regex to Match First Line, the size limit for each log is still 512 KB. If a log exceeds 512 KB, it is forcibly split into multiple entries for collection. For example, if a single log is 1,025 KB, the first 512 KB is processed, then the next 512 KB, and finally the remaining 1 KB. The final result is multiple incomplete log entries. |
File encoding | Supports log files with UTF-8 or GBK encoding. Use UTF-8 for better processing performance. Warning If the log file uses another encoding format, issues such as garbled characters and data loss may occur. |
Log file rotation | The default size of the log rotation queue is 20. Adjust this using the logreader_max_rotate_queue_size startup parameter. For more information, see Logtail network types, startup parameters, and configuration. Set the collection path to Important Do not mix these two formats in the same Logtail instance. Otherwise, the same file may match multiple Logtail collection configurations, which results in duplicate collection. If more than 20 files are not yet processed, newly generated logs will be lost. In such cases, first check whether the logstore shard write quota is exceeded and adjust the Logtail concurrency level. For more information, see Logtail network types, startup parameters, and configuration. |
Collection behavior when log parsing is blocked | When log parsing is blocked, Logtail keeps the log file descriptor open to prevent the file from being deleted, which would cause data loss. If multiple log file rotations occur while parsing is blocked, Logtail places the files in the rotation queue. |
Regular expression | Supports Perl Compatible Regular Expressions (PCRE). |
JSON | Fully supports standard JSON (RFC7159, ECMA-404). Non-standard JSON, such as |
File opening behavior | Logtail keeps the collected file and the files in the rotation queue open to ensure data integrity. The file is closed in the following situations:
To release the file handle within a set time after the file is deleted, configure the force_release_deleted_file_fd_timeout startup parameter. For more information, see Logtail network types, startup parameters, and configuration. |
Initial log collection behavior | Logtail collects only incremental logs. When a file is first detected as modified, if it exceeds 1 MB (512 KB for container standard output), collection starts from the last 1 MB. Otherwise, collection starts from the beginning. Adjust the initial collection size for new files using the tail_size_kb parameter in the Logtail collection configuration. For more information, see Logtail Configuration (legacy). If the log file is not modified after the Logtail collection configuration is applied, Logtail does not collect that file. To collect historical files, see Import historical log files. |
Behavior when a file is overwritten | Logtail identifies files using the inode plus a hash of the first 1,024 bytes. If a file is overwritten and either value changes, it is treated as a new file and collected from the beginning. Otherwise, it is skipped. |
Behavior when a file is moved | After a file is moved, if it matches a Logtail configuration that has never matched this file before, it is treated as a new file and collected from the beginning. Otherwise, it is skipped. |
File collection history | Logtail keeps file collection history in memory to ensure only incremental data is collected. If a write targets a log outside the retention range, duplicate collection may occur.
|
Non-standard text logs | For lines in logs that contain |
Billing
Installing LoongCollector or Logtail is free of charge.
Log ingestion, storage, indexing, queries, transformation, and shipping are charged based on the logstore's billing mode.
If you enable Global Accelerator during installation or configuration, additional traffic fees apply for data transmitted over the accelerated network.
FAQ
How do I manage multi-target distribution configurations?
Multi-target distribution configurations are associated with multiple logstores. Manage them from the project-level page:
Log on to the Simple Log Service console and click the name of the target project.
On the project page, choose
 from the navigation pane on the left.Note
from the navigation pane on the left.NoteThis page provides centralized management for all collection configurations in the project, including those left behind after logstore deletion.
How do I send logs from an ECS server to a project in another Alibaba Cloud account?
If you have not installed LoongCollector, see Install LoongCollector and select the appropriate cross-account use case for installation.
If LoongCollector is already installed, configure a user ID to authorize the SLS project owner to access and collect logs from this server.
Configure a user ID only when collecting logs from non-account ECS instances, on-premises servers, or third-party cloud servers.
Copy the ID of the Alibaba Cloud account that owns SLS: Hover your mouse over the profile picture in the upper-right corner. View and copy the account ID from the tab that appears.
Log on to the server from which you want to collect logs and create an Alibaba Cloud account ID file to configure the user ID:
touch /etc/ilogtail/users/{Alibaba_Cloud_account_ID} # If the /etc/ilogtail/users directory does not exist, create it manually. The user ID configuration file only needs a filename, not a file extension.
How do I send logs from an ECS server to a project in the same account but a different region?
If you have not installed LoongCollector, see Install LoongCollector and select the appropriate cross-region use case for installation.
If LoongCollector is already installed, modify its configuration.
Run the
sudo /etc/init.d/ilogtaild stopcommand to stop LoongCollector.Modify the LoongCollector startup configuration file
ilogtail_config.json. Choose one of the following two methods based on your network requirements:Configuration file path:
/usr/local/ilogtail/ilogtail_config.jsonMethod 1: Use the Internet for transmission
See RegionID and replace the region in the configuration file with the region where SLS is located. The fields to modify include the following:
primary_regionThe region part in
config_serversThe
regionand the region part ofendpoint_listindata_servers
Method 2: Use transfer acceleration
Replace the endpoint line in the data_server_list parameter with
log-global.aliyuncs.com. For the file path, see Logtail network types, startup parameters, and configuration.
Run the
sudo /etc/init.d/ilogtaild startcommand to start LoongCollector.
How do I add a server to an existing machine group?
To add a new server (such as a new ECS instance or on-premises server) to an existing machine group so it inherits the collection configuration, follow these steps.
Prerequisites:
A configured machine group already exists.
The new server has LoongCollector installed.
Procedure:
View the target machine group ID:
On the target project page, click
 in the navigation pane on the left.
in the navigation pane on the left.On the Machine Groups page, click the target machine group name.
On the machine group configuration page, view the machine group ID.
Perform the corresponding operation based on the ID type:
NoteA single machine group cannot contain both Linux and Windows servers. Do not configure the same custom ID on both Linux and Windows servers. A server can be configured with multiple custom IDs, separated by line feeds.
Type 1: Machine group ID is an IP address
On the server, run the following command to open the
app_info.jsonfile and view theipvalue.cat /usr/local/ilogtail/app_info.jsonOn the target machine group configuration page, click Modify and enter the server's IP address. Separate multiple IP addresses with line feeds.
After the configuration is complete, click Save and confirm the heartbeat status. After the heartbeat is OK, the server automatically applies the machine group's collection configuration.
If the heartbeat status is FAIL, see the FAQ Machine group heartbeat is FAIL for further troubleshooting.
Type 2: Machine group ID is a custom ID
Depending on the operating system, write the custom ID string that matches the target machine group to the specified file:
If the directory does not exist, you must create it manually. The file path and name are fixed by SLS and cannot be customized.
Linux: Write the custom string to the
/etc/ilogtail/user_defined_idfile.Windows: Write the custom string to
C:\LogtailData\user_defined_id.
How do I import a collection configuration from another project?
After completing Preparations and Machine Group Configuration, import a collection configuration from an existing project into the current logstore to avoid repetitive setup.
Procedure:
After you complete the machine group configuration, click Next to go to the Logtail Configuration page.
Click Import Other Configuration in the upper-right corner of the page.
Select the project to import from and the collection configuration under that project.
Click OK. The system automatically loads the selected configuration.
After you check that the imported configuration information is correct, click Next to go to the Query and Analysis Configurations page and complete the subsequent configuration.
How do I get a server's IP address to use as a machine group ID?
On a server where LoongCollector (Logtail) is installed, open the /usr/local/ilogtail/app_info.json file and view the ip value.
The server IP address automatically obtained by Logtail is recorded in the ip field of the app_info.json file, as shown below.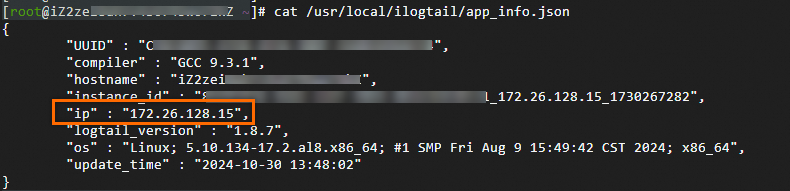
If there are multiple servers, enter their corresponding IP addresses manually. IP addresses must be separated by line feeds.
A single machine group cannot contain both Linux and Windows servers. Do not add the IP addresses of both Windows and Linux servers to the same machine group.
How can the same log file be collected by multiple collection configurations at the same time?
By default, each text log file can match only one Logtail configuration. To allow multiple configurations to collect the same file, enable multi-collection.
Procedure:
When you collect multiple copies, the file read IO, computing resources, and network IO increase linearly.
Log on to the Simple Log Service console and go to the target project.
In the navigation pane on the left, choose
 Logstores and find the target logstore.
Logstores and find the target logstore.Click the
 icon before its name to expand the logstore.
icon before its name to expand the logstore.Click Logtail Configuration. In the configuration list, find the target Logtail configuration and click Manage Logtail Configuration in the Actions column.
On the Logtail configuration page, click Edit:
In , enable Allow File to Be Collected for Multiple Times.
After the configuration is complete, click Save.
Why is the last log entry reported after a long delay? Why is it sometimes truncated?
Cause: This usually occurs when a log file is missing a trailing line feed, or when a multiline log (such as an exception stack) has not been fully written. The agent cannot determine whether the log has ended, so the last content may be split prematurely or delayed. Different LoongCollector (Logtail) versions handle this differently:
Versions before 1.8:
If the last line of a log does not have a line feed (carriage return), or if a multiline log paragraph is not finished, the agent waits for the next write to trigger an output. This can cause the last log entry to be held for a long time without being sent, until a new log is written.Version 1.8 and later:
A timeout refresh mechanism was introduced to prevent logs from getting stuck. When an incomplete log line is detected, the system starts a timer. After the timeout, it automatically submits the current content, which ensures the log is eventually collected.Default timeout: 60 seconds (to ensure completeness in most use cases)
Adjust this value as needed, but do not set it to 0, as this may cause log truncation or partial content loss.
Solution:
Extend the waiting time to ensure the complete log is written before it is collected:
Log on to the Simple Log Service console and go to the target project.
In the navigation pane on the left, choose
Logstores and find the target logstore.Click the
icon before its name to expand the logstore.Click Logtail Configuration. In the configuration list, find the target Logtail configuration and click Manage Logtail Configuration in the Actions column.
On the Logtail configuration page, click Edit:
In , add the following JSON configuration to customize the timeout:
{ "FlushTimeoutSecs": 1 }Default value: Determined by the startup parameter
default_reader_flush_timeout(usually a few seconds).Unit: Seconds.
Recommended value: ≥1 second. Do not set it to 0, as this may cause log truncation or partial content loss.
After the configuration is complete, click Save.
Why does LoongCollector (Logtail) switch from an internal endpoint to the Internet during operation? Can it switch back automatically?
If LoongCollector (Logtail) detects a communication failure with the internal same-region endpoint (network failure or connection timeout), it automatically switches to the public endpoint to maintain log collection continuity.
LoongCollector: Automatically switches back to the internal network after it recovers.
Logtail: Does not switch back automatically. It must be manually restarted to resume internal network communication.
Appendix: Details of native processors
In the Processor Configurations section of the Logtail Configuration page, add processors to structure raw logs. To add a processing plugin to an existing configuration:
In the navigation pane on the left, choose
 Logstores and find the target logstore.
Logstores and find the target logstore.Click the
 icon before its name to expand the logstore.
icon before its name to expand the logstore.Click Logtail Configuration. In the configuration list, find the target Logtail configuration and click Manage Logtail Configuration in the Actions column.
On the Logtail configuration page, click Edit.
This section introduces only commonly used processing plugins that cover common log processing use cases. For more features, see Extended processors.
Rules for combining plugins (for LoongCollector / Logtail 2.0 and later):
Native and extended processors can be used independently or combined as needed.
Prioritize native processors because they offer better performance and stability.
When native features cannot meet your business needs, add extended processors after the configured native ones for supplementary processing.
Order constraint:
Plugins run sequentially in configured order, forming a processing chain. All native processors must precede any extended processors. After adding an extended processor, you cannot add more native processors.
Regular expression parsing
Extract log fields using a regular expression and parse the log into key-value pairs. Each field can be independently queried and analyzed.
Example:
Raw log without any processing | Using the regular expression parsing plugin |
| |
Procedure: In the Processor Configurations section of the Logtail Configuration page, click Add Processor and select :
Regular Expression: The expression used to match logs. Generate it automatically or enter it manually:
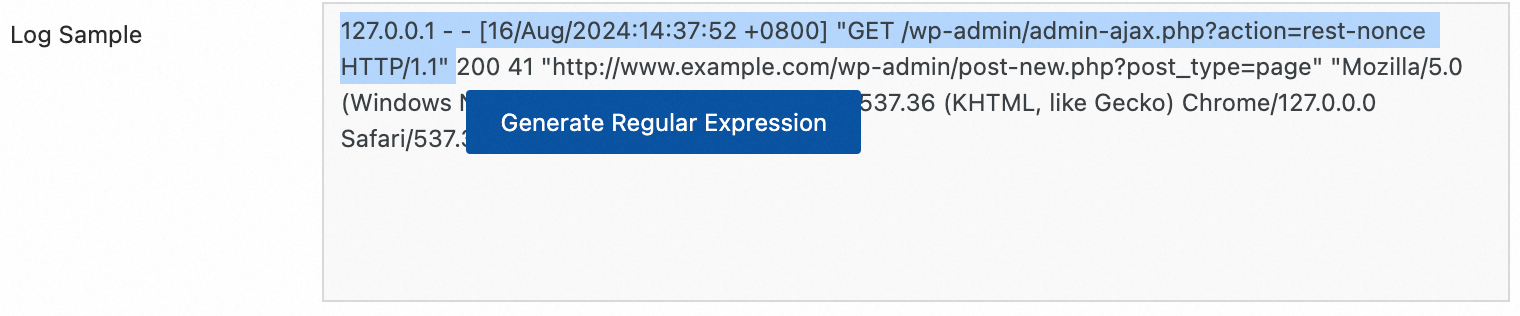
Automatic generation:
Click Generate.
In the Log Sample, select the log content to extract.
Click Generate Regular Expression.
Manual entry: Manually Enter Regular Expression based on the log format.
After configuration, click Validate to test whether the regular expression can correctly parse the log content.
Extracted Field: The field name (Key) that corresponds to the extracted log content (Value).
For other parameters, see the description of common configuration parameters in Use case 2: Structured logs.
Separator parsing
Structure log content using a separator to parse it into multiple key-value pairs. Both single-character and multi-character separators are supported.
Example:
Raw log without any processing | Fields split by the specified character |
| |
Procedure: In the Processor Configurations section of the Logtail Configuration page, click Add Processor and select :
Delimiter: Specifies the character used to split log content.
Example: For a CSV file, select Custom and enter a comma (,).
Quote: If a field value contains the separator, you must enclose the field value in quotes to prevent incorrect splitting.
Extracted Field: Specify the field name (Key) for each column in the order that they appear. The rules are as follows:
Field names can contain only letters, digits, and underscores (_).
Must start with a letter or an underscore (_).
Maximum length: 128 bytes.
For other parameters, see the description of common configuration parameters in Use case 2: Structured logs.
Standard JSON parsing
Structure an Object-type JSON log by parsing it into key-value pairs.
Example:
Raw log without any processing | Automatic extraction of standard JSON key-value pairs |
| |
Procedure: In the Processor Configurations section of the Logtail Configuration page, click Add Processor and select :
Original Field: The field that contains the raw log to be parsed. The default value is content.
For other parameters, see the description of common configuration parameters in Use case 2: Structured logs.
Nested JSON parsing
Parse a nested JSON log into key-value pairs by specifying the expansion depth.
Example:
Raw log without any processing | Expansion depth: 0, using expansion depth as a prefix | Expansion depth: 1, using expansion depth as a prefix |
| | |
Procedure: In the Processor Configurations section of the Logtail Configuration page, click Add Processor and select :
Original Field: Specifies the name of the source field to expand, such as
content.JSON Expansion Depth: The expansion depth of the JSON object, where 0 (the default) indicates full expansion, 1 indicates expansion of the current level, and so on.
Character to Concatenate Expanded Keys: The separator for field names when a JSON object is expanded. The default value is an underscore (_).
Name Prefix of Expanded Keys: The prefix for field names after JSON expansion.
Expand Array: Expands an array into key-value pairs with indexes.
Example:
{"k":["a","b"]}is expanded to{"k[0]":"a","k[1]":"b"}.To rename the expanded fields (for example, from prefix_s_key_k1 to new_field_name), add a rename fields plugin afterward to complete the mapping.
For other parameters, see the description of common configuration parameters in Use case 2: Structured logs.
JSON array parsing
Use the json_extract function to extract JSON objects from a JSON array.
Example:
Raw log without any processing | Extract JSON array structure |
| |
Procedure: In the Processor Configurations section of the Logtail Configuration page, switch the Processing Mode to SPL, configure the SPL Statement, and use the json_extract function to extract JSON objects from the JSON array.
Example: Extract elements from the JSON array in the log field content and store the results in new fields json1 and json2.
* | extend json1 = json_extract(content, '$[0]'), json2 = json_extract(content, '$[1]')Apache log parsing
Structure the log content into multiple key-value pairs based on the definition in the Apache log configuration file.
Example:
Raw log without any processing | Apache Common Log Format |
| |
Procedure: In the Processor Configurations section of the Logtail Configuration page, click Add Processor and select :
The Log Format is combined.
The APACHE LogFormat Configuration are automatically populated based on the Log Format.
ImportantMake sure to verify the auto-filled content to ensure it is exactly the same as the LogFormat defined in your server's Apache configuration file (usually located at /etc/apache2/apache2.conf).
For other parameters, see the description of common configuration parameters in Use case 2: Structured logs.
IIS log parsing
Structure the log content into multiple key-value pairs based on the IIS log format definition.
Comparison example:
Raw log | Adaptation for Microsoft IIS server-specific format |
| |
Procedure: In the Processor Configurations section of the Logtail Configuration page, click Add Processor and select :
Log Format: Select the log format for your IIS server.
IIS: The log file format for Microsoft Internet Information Services.
NCSA: Common Log Format.
W3C refers to the W3C Extended Log File Format.
IIS Configuration Fields: When you select IIS or NCSA, SLS uses the default IIS configuration fields. When you select W3C, you must set the fields to the value of the
logExtFileFlagsparameter in your IIS configuration file. For example:logExtFileFlags="Date, Time, ClientIP, UserName, SiteName, ComputerName, ServerIP, Method, UriStem, UriQuery, HttpStatus, Win32Status, BytesSent, BytesRecv, TimeTaken, ServerPort, UserAgent, Cookie, Referer, ProtocolVersion, Host, HttpSubStatus"For other parameters, see the description of common configuration parameters in Use case 2: Structured logs.
Data masking
Mask sensitive data in logs.
Example:
Raw log without any processing | Masking result |
| |
Procedure: In the Processor Configurations section of the Logtail Configuration page, click Add Processor and select :
Original Field: The field that contains the log content before parsing.
Data Masking Method:
const: Replaces sensitive content with a constant string.
md5: Replaces sensitive content with its MD5 hash.
Replacement String: If Data Masking Method is set to const, enter a string to replace the sensitive content.
Content Expression that Precedes Replaced Content: The expression used to find sensitive content, which is configured using RE2 syntax.
Content Expression to Match Replaced Content: The regular expression used to match sensitive content. The expression must be written in RE2 syntax.
Time parsing
Parse the time field in the log and set the parsing result as the log's __time__ field.
Example:
Raw log without any processing | Time parsing |
|
|
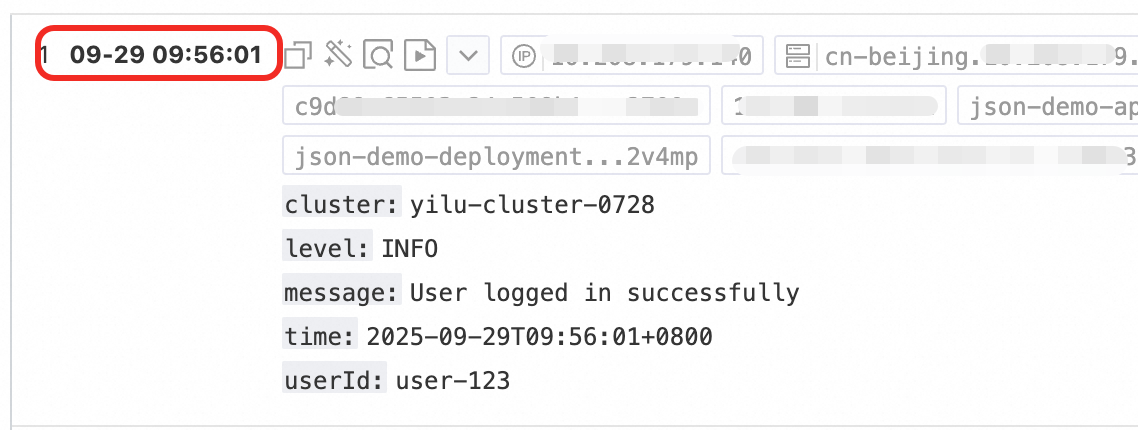
Procedure: In the Processor Configurations section of the Logtail Configuration page, click Add Processor and select :
Original Field: The field that contains the log content before parsing.
Time Format: Set the time format that corresponds to the timestamps in the log.
Time Zone: Select the time zone for the log time field. By default, this is the time zone of the environment where the LoongCollector (Logtail) process is running.
Appendix: Permission policy reference
Alibaba Cloud account logon: Has full permissions by default.
RAM user logon: The Alibaba Cloud account must grant the required access policies to the RAM user.
Custom permission policies (fine-grained control)
If system policies do not meet the principle of least privilege, create custom policies for fine-grained authorization. Example policy with the following permissions:
View projects: View the project list and the details of a specified project.
Manage logstores: Create, modify, or delete logstores under a project.
Manage collection configuration: Create, delete, and modify collection configurations.
View logs: Query and analyze data in a specified logstore under a specified project.
Replace${regionName},${uid},${projectName}, and${logstoreName}with the actual region name, Alibaba Cloud account ID, target project, and logstore.
Permission | Action | Resource |
Read-only Project |
|
|
Get a specified project |
|
|
Manage logstores |
|
|
Manage LoongCollector (Logtail) data import |
|
|
Query saved searches |
|
|
Query dashboards |
|
|
Query logs in a specified logstore |
|
|
Permissions to operate ECS |
|
|
Permissions to operate OOS (Optional) Required only when LoongCollector (Logtail) is automatically installed via OOS in the same account and region as the SLS and ECS instance. |
|
|
System permission policies
If you use system-defined policies, add the following permissions:
AliyunLogFullAccess: Permission to manage SLS.AliyunECSFullAccess: Permission to manage ECS.(Optional)
AliyunOOSFullAccess: Required when LoongCollector (Logtail) is installed with one click using OOS.
More information
Processor Configurations
Parameter | Description |
Log Sample | A sample of the log to be collected. Be sure to use a log from your actual use case. The log sample helps you configure log processing parameters and simplifies the configuration. Multiple samples can be added, with a total length not exceeding 1,500 characters. |
Multi-line Mode |
|
Processing Method | Processors, which includes Native Processor and Extended Processor. See Usage notes for native and extended processors. Important Processing plugin limits are shown on the console page.
|