A scorecard is a common modeling tool that is used in the field of credit risk assessment. The scorecard performs binning to implement the discretization of variables and uses linear models, such as linear and logistic regression models, to train a model. The model training process includes feature selection and score transformation. The scorecard also allows you to add constraints to the variables during model training.
If you use the scorecard without binning, scorecard training is equivalent to logistic or linear regression.
Limits
The temporary model that is generated by using the Scorecard Training component can store data only in a MaxCompute temporary table. The default lifecycle of the temporary table in Machine Learning Studio is 369 days. The default lifecycle equals the retention period of temporary tables that you specified in the current workspace in Machine Learning Designer. For more information, see Manage workspaces. If you want to use the temporary model for long-term business, you must persist data by using Write Table. For more information, see FAQ about algorithm components.
Terms
The following section describes the terms involved in scorecard training:
Feature engineering
The main difference between the scorecard and normal linear models is that the scorecard performs feature engineering before it trains linear models. The Scorecard Training component supports the following methods for feature engineering:
The Binning component is used to implement feature discretization. Then, one-hot encoding is performed for each variable based on the binning results to generate N dummy variables. N represents the number of bins.
NoteWhen you convert original variables into dummy variables, you can specify constraints for these dummy variables.
The Binning component is used to implement feature discretization. Then, the weight of evidence (WOE) conversion is performed to replace the original value of a variable with the WOE value of the bin into which the variable falls.
Score transformation
In scenarios such as credit scoring, you must perform a linear transformation to convert the predicted sample odds into a score. The following figure shows the formula used for linear transformation.
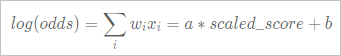 You can use the following parameters to specify the linear transformation relationship:
You can use the following parameters to specify the linear transformation relationship:scaledValue: specifies a scaled score.
odds: specifies the odds of the scaled score.
pdo: specifies the points at which the odds are doubled.
For example, set the scaledValue parameter to 800, the odds parameter to 50, and the pdo parameter to 25. In this case, the following two dots are determined for a line:
log(50)=a×800+b log(100)=a×825+bCalculate the values of a and b, and perform a linear transformation to obtain the scores of a and b.
The scaling information is specified in the JSON format by using the
-Dscaleparameter.{"scaledValue":800,"odds":50,"pdo":25}If you specify the
-Dscaleparameter, you must also specify scaledValue, odds, and pdo.Constraint addition during training
During scorecard training, you can add constraints to variables. For example, you can specify the score of a specific bin as a fixed value, specify the scores of two bins to meet a specific proportional relationship, or limit the scores between bins, such as sorting bin scores by WOE value. The implementation of constraints depends on the underlying optimization algorithm that contains constraints. You can specify the constraints in the Binning component in the Machine Learning Platform for AI console. After the constraints are specified, the Binning component generates constraints in the JSON format and automatically transfers them to the connected training component. The system supports the following JSON constraints:
"<": The weights of variables must be sorted in ascending order.
">": The weights of variables must be sorted in descending order.
"=": The weight of a specific variable must be a fixed value.
"%": The weights of two variables must meet a proportional relationship.
"UP": the upper limit for the weights of variables. For example, a value of 0.5 indicates that the weight of a variable after training is at most 0.5.
"LO": the lower limit for the weights of variables. For example, a value of 0.5 indicates that the weight of a variable after training is at least 0.5.
Each JSON constraint is stored in a table as a string. The table contains only one row and one column. Example:
{ "name": "feature0", "<": [ [0,1,2,3] ], ">": [ [4,5,6] ], "=": [ "3:0","4:0.25" ], "%": [ ["6:1.0","7:1.0"] ] }Built-in constraints
Each original variable has a built-in constraint: For each variable, the average score of a population must be 0. Due to the constraint, the value of the scaled_weight parameter in the intercept options of the scorecard model equals the average score of the population in terms of all variables.
Optimization algorithms
On the Parameters Setting tab, select Advanced Options. Then, you can configure the optimization algorithm that is used during scorecard training. The system supports the following optimization algorithms:
L-BFGS: This algorithm is a first-order optimization algorithm that is used to process large amounts of feature data. The algorithm does not contain constraints. If you select this algorithm, the system automatically ignores the constraints that you specify.
Newton's method: This algorithm is a classic second-order optimization algorithm. It is fast in convergence and accurate. However, the algorithm is not suitable for processing large amounts of feature data because it needs to calculate a second-order Hessian matrix. The algorithm does not contain constraints. If you select this algorithm, the system automatically ignores the constraints that you specify.
Barrier method: This algorithm is a second-order optimization algorithm. If the algorithm does not contain constraints, it is completely equivalent to the Newton's method algorithm. The barrier method algorithm provides almost the same computing performance and accuracy as the SQP algorithm. In most cases, we recommend that you select SQP.
SQP
This algorithm is a second-order optimization algorithm. If the algorithm does not contain constraints, it is completely equivalent to the Newton's method algorithm. The SQP algorithm provides almost the same computing performance and accuracy as the barrier method algorithm. In most cases, we recommend that you select SQP.
NoteL-BFGS and Newton's method are optimization algorithms without constraints. Barrier method and SQP are optimization algorithms with constraints.
If you are not familiar with optimization algorithms, we recommend that you set the Optimization Method parameter to Auto Selection. In this case, the system selects the most appropriate algorithm based on the data amount and constraints.
Feature selection
The Scorecard Training component supports stepwise feature selection. Stepwise feature selection is a combination of forward and backward selection. Each time the system performs a forward selection to select a new variable and adds it to the model, the system also performs a backward selection. The backward selection is used to remove the variables whose significance does not meet the requirements. Stepwise feature selection supports various functions and feature transformation methods. Therefore, stepwise feature selection also supports multiple selection standards. The following standards are supported:
Marginal contribution: This standard can be applied to all functions and feature engineering methods.
For this standard, two models must be trained: Model A and Model B. Model A does not contain Variable X, and Model B contains Variable X in addition to all the variables of Model A. The difference between the functions of the two models in final convergence is the marginal contribution of Variable X to all the other variables in Model B. In scenarios where variables are converted into dummy variables, the marginal contribution of Variable X is the difference between the functions of all dummy variables in Model A and the functions of all dummy variables in Model B. Therefore, the marginal contribution standard is supported by all feature engineering methods.
Marginal contribution is flexible and is not limited to a specific type of model. Only variables that contribute to functions are passed to the model. Marginal contribution has disadvantages when compared with statistical significance. Typically, 0.05 is used as the threshold for statistical significance. Marginal contribution does not provide a recommended threshold for beginners. We recommend that you set the threshold to 10E-5.
Score test: This standard supports only WOE conversion and logistic regression without feature engineering.
During a forward selection, a model that has only intercept options is trained first. In each subsequent iteration, the score chi-squares of the variables that are not passed to the model are measured. The variable with the largest score chi-square is passed to the model. In addition, the p-value of the variable with the largest score chi-square is calculated based on chi-square distribution. If the p-value of the variable is greater than the given SLENTRY value, the variable is not passed to the model, and feature selection is terminated.
After the forward selection is complete, a backward selection is performed for the variable that is passed to the model. The Wald chi-square of the variable and the related p-value are calculated. If the p-value is greater than the given SLSTAY value, the variable is removed from the model. Then, the system starts a new iteration.
F test: This standard supports only WOE conversion and linear regression without feature engineering.
During a forward selection, a variable that has only intercept options is trained first. In each subsequent iteration, the F-values of the variables that are not passed to the model are calculated. F-value calculation is similar to marginal contribution calculation. Two models must be trained to calculate the F-value of a variable. The F-value follows F distribution. The related p-value can be calculated based on the probability density function of F distribution. If the p-value is greater than the given SLENTRY value, the variable is not passed to the model, and the forward selection is terminated.
During the backward selection, the F-value is used to calculate the significance of a variable in a way similar to a score test.
forced selection of the variables that you want to pass to a model
Before a feature selection is performed, you can specify the variables that you want to forcibly pass to the model. No forward or backward selection is performed for the specified variables. These variables are directly passed to the model regardless of their significance. You can specify the number of iterations and significance thresholds by using the -Dselected parameter. Specify this parameter in the JSON format. Example:
{"max_step":2, "slentry": 0.0001, "slstay": 0.0001}If the -Dselected parameter is left empty or the max_step parameter is set to 0, no feature selection is performed.
Parameter settings
Machine Learning Designer allows you to configure the Scorecard Training component in a visualized manner or by running Machine Learning Platform for AI commands. The following code provides a sample command:
pai -name=linear_model -project=algo_public
-DinputTableName=input_data_table
-DinputBinTableName=input_bin_table
-DinputConstraintTableName=input_constraint_table
-DoutputTableName=output_model_table
-DlabelColName=label
-DfeatureColNames=feaname1,feaname2
-Doptimization=barrier_method
-Dloss=logistic_regression
-Dlifecycle=8Parameter | Description | Required | Default |
inputTableName | The name of the input feature table. | Yes | N/A |
inputTablePartitions | The partitions that are selected from the input feature table. | No | Full table |
inputBinTableName | The name of the binning result table. If you specify this parameter, the system automatically performs discretization for features based on the binning rules in the binning result table. | No | N/A |
featureColNames | The feature columns that are selected from the input table. | No | All columns except the label column |
labelColName | The name of the label column. | Yes | N/A |
outputTableName | The name of the output model table. | Yes | N/A |
inputConstraintTableName | The name of the table that stores constraints. The constraints are a JSON string that is stored in a cell of the table. | No | N/A |
optimization | The optimization algorithm. Valid values:
Only sqp and barrier_method support constraints. If you set the optimization parameter to auto, the system automatically selects an appropriate optimization algorithm based on user data and related parameter settings. If you are not familiar with optimization algorithms, we recommend that you set the optimization parameter to auto. | No | auto |
loss | The loss type. Valid values: logistic_regression and least_square. | No | logistic_regression |
iterations | The maximum number of iterations for optimization. | No | 100 |
l1Weight | The parameter weight of L1 regularization. This parameter is valid only if the optimization parameter is set to lbfgs. | No | 0 |
l2Weight | The parameter weight of L2 regularization. | No | 0 |
m | The historical step size for optimization that is performed by using the L-BFGS algorithm. This parameter is valid only if the optimization parameter is set to lbfgs. | No | 10 |
scale | The weight scaling information of the scorecard. | No | Empty |
selected | Specifies whether to enable feature selection during scorecard training. | No | Empty |
convergenceTolerance | The convergence tolerance. | No | 1e-6 |
positiveLabel | Specifies whether the samples are positive samples. | No | 1 |
lifecycle | The lifecycle of the output table. | No | N/A |
coreNum | The number of cores. | No | Determined by the system |
memSizePerCore | The memory size of each core. Unit: MB. | No | Determined by the system |
Output
The Scorecard Training component generates data to a model report. The model report contains basic model evaluation statistics, such as binning information, binning constraints, WOE values, and marginal contribution information. The following table describes the columns in a model report.
Column | Type | Description |
feaname | STRING | The name of the feature. |
binid | BIGINT | The ID of the bin. |
bin | STRING | The description of the bin, which indicates the interval of the bin. |
constraint | STRING | The constraints that are added to the bin during training. |
weight | DOUBLE | The weight of a binning variable. For a non-scorecard model without binning, this field indicates the weight of a model variable. |
scaled_weight | DOUBLE | The score that is linearly transformed from the weight of a binning variable in scorecard training. |
woe | DOUBLE | A metric. It indicates the WOE value of a bin in the training set. |
contribution | DOUBLE | A metric. It indicates the marginal contribution value of a bin in the training set. |
total | BIGINT | A metric. It indicates the total number of samples in a bin in the training set. |
positive | BIGINT | A metric. It indicates the number of positive samples in a bin in the training set. |
negative | BIGINT | A metric. It indicates the number of negative samples in a bin in the training set. |
percentage_pos | DOUBLE | A metric. It indicates the proportion of positive samples in a bin to total positive samples in the training set. |
percentage_neg | DOUBLE | A metric. It indicates the proportion of negative samples in a bin to total negative samples in the training set. |
test_woe | DOUBLE | A metric. It indicates the WOE value of a bin in the testing set. |
test_contribution | DOUBLE | A metric. It indicates the marginal contribution value of a bin in the testing set. |
test_total | BIGINT | A metric. It indicates the total number of samples in a bin in the testing set. |
test_positive | BIGINT | A metric. It indicates the number of positive samples in a bin in the testing set. |
test_negative | BIGINT | A metric. It indicates the number of negative samples in a bin in the testing set. |
test_percentage_pos | DOUBLE | A metric. It indicates the proportion of positive samples in a bin to total positive samples in the testing set. |
test_percentage_neg | DOUBLE | A metric. It indicates the proportion of negative samples in a bin to total negative samples in the testing set. |