MaxCompute Graph is an iterative graph computing framework. It lets you build graph models and run algorithms—such as PageRank, single-source shortest path (SSSP), and k-means clustering—directly on data stored in MaxCompute. Use the SDK for Java provided by MaxCompute Graph to write your graph computing programs.
How it works
Graph algorithms are inherently iterative: the property of a vertex depends on the properties of its neighbors, which in turn depend on their neighbors. MaxCompute Graph captures this by repeatedly modifying a graph until a convergence condition is met. Each iteration is called a superstep.
A graph program runs in three phases:
-
Graph loading — A custom
GraphLoaderreads records from an input table and converts them into vertices and edges. A customPartitionerthen distributes vertices across workers. By default, MaxCompute Graph partitions vertices by hashing each vertex ID modulo the number of workers. -
Iterative computing — Each superstep traverses all non-halted vertices and any halted vertices that received messages, then calls
compute(ComputeContext context, Iterable messages)on each of them. Insidecompute(), each vertex can:-
Process messages sent by the previous superstep.
-
Change the values of vertices or edges.
-
Send messages to other vertices.
-
Add or remove vertices or edges.
-
Use an
Aggregatorto collect and update global information. For details, see Aggregator implementation mechanism. -
Set itself to halted or non-halted.
MaxCompute Graph asynchronously sends messages to the related workers in each superstep. The messages are then processed in the next superstep.
-
-
Iteration termination — The computation stops when any of the following conditions is true:
-
All vertices are halted (Halted = true) and no new messages have been generated.
-
The maximum number of iterations is reached.
-
The
terminate()method of an aggregator returnstrue.
-
The following pseudocode shows the full execution flow:
// 1. load
for each record in input_table {
GraphLoader.load();
}
// 2. setup
WorkerComputer.setup();
for each aggr in aggregators {
aggr.createStartupValue();
}
for each v in vertices {
v.setup();
}
// 3. superstep
for (step = 0; step < max; step ++) {
for each aggr in aggregators {
aggr.createInitialValue();
}
for each v in vertices {
v.compute();
}
}
// 4. cleanup
for each v in vertices {
v.cleanup();
}
WorkerComputer.cleanup();Key concepts
| Term | Definition |
|---|---|
| Graph | An abstract data structure that represents relationships between objects using vertices and edges. |
| Vertex | Represents an object in a graph. Structure: <ID, Value, Halted, Edges>. |
| Edge | A single directed edge representing the relationship between two objects. Structure: <DestVertexID, Value>. |
| Directed graph | A graph in which edges have directions. Edges are classified as outgoing edges or incoming edges. |
| Undirected graph | A graph in which edges have no directions. |
| Outgoing edge | A directed edge for which the current vertex is the origin. |
| Incoming edge | A directed edge for which the current vertex is the destination. |
| Degree | The number of edges connected to a vertex. |
| Outdegree | The number of outgoing edges connected to a vertex. |
| Indegree | The number of incoming edges connected to a vertex. |
| Superstep | One iteration of the graph computation. |
Graph data structure
MaxCompute Graph processes directed graphs. Because MaxCompute uses a two-dimensional table storage structure, you must convert graph data into two-dimensional tables before storing it.
During computation, a custom GraphLoader converts the table records back into vertices and edges.
Vertex structure: <ID, Value, Halted, Edges>
| Field | Description |
|---|---|
ID |
The vertex ID. |
Value |
The vertex value. |
Halted |
Whether the vertex has stopped iterating. |
Edges |
The outgoing edges from this vertex. |
Edge structure: <DestVertexID, Value>
| Field | Description |
|---|---|
DestVertexID |
The ID of the destination vertex. |
Value |
The edge value. |
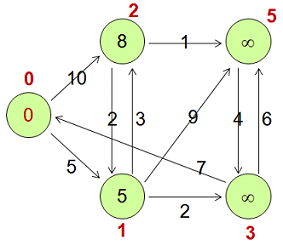
The graph above maps to the following two-dimensional table:
| Vertex | <ID, Value, Halted, Edges> |
|---|---|
| v0 | <0, 0, false, [<1,5>, <2,10>]> |
| v1 | <1, 5, false, [<2,3>, <3,2>, <5,9>]> |
| v2 | <2, 8, false, [<1,2>, <5,1>]> |
| v3 | <3, Long.MAX_VALUE, false, [<0,7>, <5,6>]> |
| v5 | <5, Long.MAX_VALUE, false, [<3,4>]> |
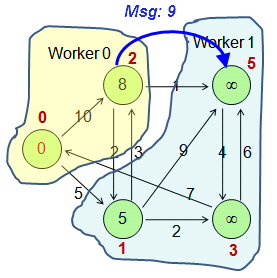
The following figure shows how vertices are distributed across two workers during graph loading. Vertex IDs are hashed modulo 2: v0 and v2 (ID modulo 2 = 0) go to Worker 0; v1, v3, and v5 (ID modulo 2 = 1) go to Worker 1.
When you edit a vertex or edge, use code to maintain the relationships between vertices and edges.