本文为您介绍MaxCompute支持的MapReduce编程接口及使用限制。
MaxCompute提供两个MapReduce编程接口:
MaxCompute MapReduce:MaxCompute的原生接口,执行速度快、开发快捷、不暴露文件系统。
MaxCompute扩展MapReduce(MR2):支持更复杂的作业调度逻辑,且实现方式与MaxCompute原生接口一致。相比于传统的MapRedce,MaxCompute提供的扩展MapReduce模型(简称MR2)改变了底层的调度和IO模型,可避免作业时冗余的IO操作。
以上版本在基本概念、作业提交、输入与输出、资源使用等方面基本一致,仅各版本的Java SDK有所不同。更多详情请参见Hadoop Map/Reduce教程。
您无法通过MapReduce读写外部表中的数据。
MapReduce
应用场景
MapReduce支持下列场景:
搜索:网页爬取、倒排索引、PageRank。
Web访问日志分析:
分析和挖掘用户在Web上的访问、购物行为特征,实现个性化推荐。
分析用户访问行为。
文本统计分析:
热门小说的字数统计(WordCount)、词频TFIDF分析。
学术论文、专利文献的引用分析和统计。
维基百科数据分析。
海量数据挖掘:非结构化数据、时空数据和图像数据挖掘。
机器学习:监督学习、无监督学习和分类算法(例如决策树、SVM)。
自然语言处理:
基于大数据的训练和预测。
基于语料库构建单词同现矩阵,频繁项集数据挖掘、重复文档检测等。
广告推荐:用户单击(CTR)和购买行为(CVR)预测。
MapReduce流程说明
MapReduce处理数据过程主要分成Map和Reduce两个阶段。首先执行Map阶段,再执行Reduce阶段。Map和Reduce的处理逻辑由用户自定义实现,但要符合MapReduce框架的约定。MapReduce处理数据的完整流程如下:
输入数据:在正式执行Map前,需要对输入数据进行分片(即将输入数据切分为大小相等的数据块),将每片内的数据作为单个Map Worker的输入,以便多个Map Worker同时工作。
Map阶段:每个Map Worker读取数据后进行计算处理,并为每条输出数据指定一个Key,决定这条数据将会被发送给哪一个Reduce Worker。
说明Key值和Reduce Worker是多对一的关系,具有相同Key的数据会被发送给同一个Reduce Worker,单个Reduce Worker有可能会接收到多个Key值的数据。
Shuffle阶段:在进入Reduce阶段之前,MapReduce框架会将数据按照Key值排序,使得具有相同Key的数据彼此相邻。如果您指定了合并操作(Combiner),框架会调用Combiner,将具有相同Key的数据进行聚合。Combiner的逻辑可以由您自定义实现。与经典的MapReduce框架协议不同,在MaxCompute中,Combiner的输入、输出的参数必须与Reduce保持一致,这部分的处理通常也叫做洗牌(Shuffle)。
Reduce阶段:相同Key的数据会传送至同一个Reduce Worker。同一个Reduce Worker会接收来自多个Map Worker的数据。每个Reduce Worker会对Key相同的多个数据进行Reduce操作。最后,一个Key的多条数据经过Reduce的作用后,将变成一个值。
输出结果数据。
上文仅是对MapReduce框架的简单介绍,更多详情请查阅功能介绍。
下文将以WordCount为例,为您介绍MaxCompute MapReduce各个阶段的概念。
假设存在一个文本a.txt,文本内每行是一个数字,您要统计每个数字出现的次数。文本内的数字称为Word,数字出现的次数称为Count。如果MaxCompute MapReduce完成这一功能,需要经历以下流程,图示如下。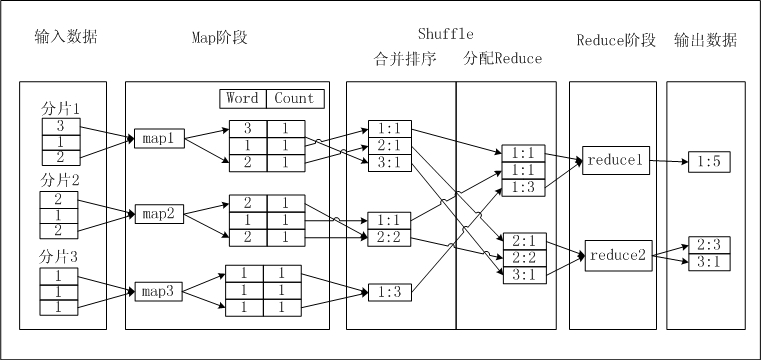
操作步骤
输入数据:对文本进行分片,将每片内的数据作为单个Map Worker的输入。
Map阶段:Map处理输入,每获取一个数字,将数字的Count设置为1,并将此<Word, Count>对输出,此时以Word作为输出数据的Key。
Shuffle>合并排序:在Shuffle阶段前期,首先对每个Map Worker的输出,按照Key值(即Word值)进行排序。排序后进行Combiner操作,即将Key值(Word值)相同的Count累加,构成一个新的<Word, Count>对。此过程被称为合并排序。
Shuffle>分配Reduce:在Shuffle阶段后期,数据被发送到Reduce端。Reduce Worker收到数据后依赖Key值再次对数据排序。
Reduce阶段:每个Reduce Worker对数据进行处理时,采用与Combiner相同的逻辑,将Key值(Word值)相同的Count累加,得到输出结果。
输出结果数据。
由于MaxCompute的所有数据都被存放在表中,因此MaxCompute MapReduce的输入、输出只能是表,不允许您自定义输出格式,不提供类似文件系统的接口。
使用限制
MapReduce使用限制请参见使用限制汇总。
有关本地运行的MapReduce使用限制,请参见本地运行和分布式环境运行差异。
扩展MapReduce(MR2)
与MaxCompute相比,MR2在Map、Reduce等函数编写方式上基本一致,较大的不同点发生在执行作业时,示例请参见Pipeline示例。
MR2模型产生背景
传统的MapReduce模型要求在经过每一轮MapReduce操作后,得到的数据结果必须存储到分布式文件系统中(例如,HDFS或MaxCompute数据表)。MapReduce模型通常由多个MapReduce作业组成,每个作业执行完成后都需要将数据写入磁盘,然而后续的Map任务很可能只需要读取一遍这些数据,为之后的Shuffle阶段做准备,这种情况就产生了冗余的磁盘IO操作。
MaxCompute的计算调度逻辑可以支持更复杂的编程模型, 针对上述情况,可以在Reduce后直接执行下一次的Reduce操作,而不需要中间插入一个Map操作。因此,MaxCompute提供了扩展的MapReduce模型,即可以支持Map后连接任意多个Reduce操作,例如Map>Reduce>Reduce。
与Hadoop Chain Mapper/Reducer对比
Hadoop Chain Mapper/Reducer也支持类似的串行化Map或Reduce操作,但和MaxCompute的扩展MapReduce(MR2)模型有本质的区别。
Chain Mapper/Reducer基于传统的MapReduce模型,仅可以在原有的Mapper或Reducer后增加一个或多个Mapper操作(不允许增加Reducer)。这样的优点是,您可以复用之前的Mapper业务逻辑,把一个Map或Reduce拆成多个Mapper阶段,同时本质上并没有改变底层的调度和I/O模型。