MaxCompute is an enterprise-grade Software as a Service (SaaS) Cloud Data Warehouse built for Data Analytics. With its Serverless Architecture, it delivers a fast, fully managed online data warehouse service that eliminates the scalability and elasticity constraints of traditional data platforms. This approach minimizes your operational overhead, letting you analyze and process massive datasets economically and efficiently.
As data collection methods evolve and industry data accumulates, data volumes have grown to terabyte (TB), petabyte (PB), and even exabyte (EB) scales, reaching levels that traditional software cannot handle. MaxCompute provides both offline and real-time data ingestion, and supports large-scale data processing and query acceleration. It offers versatile data warehouse solutions and analytical modeling services for a wide range of computing scenarios. With comprehensive data import solutions and a variety of classic distributed computing models, you can easily analyze big data without the complexity of managing and maintaining distributed systems.
MaxCompute is designed for storage and compute needs ranging from 100 GB to the exabyte (EB) level and has been battle-tested at scale within Alibaba Group. It is ideal for use cases such as data warehousing and BI analytics for large internet companies, website log analysis, e-commerce transaction analysis, and analyzing user behavior and interests.
MaxCompute is deeply integrated with the following Alibaba Cloud products:
An end-to-end platform for data synchronization, workflow design, data development, management, and operations.
A machine learning platform with algorithm components for training models on MaxCompute data.
A real-time data warehouse that can accelerate queries on MaxCompute data via external tables or for interactive analysis on data exported from MaxCompute.
A business intelligence tool for creating reports and visually analyzing MaxCompute data.
Core features
Feature | Description |
Fully managed Serverless online service |
|
Elasticity and Scalability |
|
Unified and rich computing and storage capabilities |
|
Data modeling, development, and governance capabilities | You can centralize, integrate, process, and govern all your data with DataWorks, a one-stop Data Development and Data Governance platform. DataWorks supports MaxCompute project management and web-based query editing. |
Integrated AI capabilities |
|
Deep integration with the Spark engine |
|
Lakehouse |
For more information, see Lakehouse of MaxCompute. |
Unified offline and real-time processing |
|
Support for stream writing and near real-time analytics |
|
Continuous SaaS-based data protection in the cloud | Provides over 20 security features that meet Level 3 standards for classified information security protection. These features cover infrastructure, data centers, networks, power supply, platform security, permission management, and privacy protection, combining the security capabilities of both open-source big data and managed databases. |
Product architecture
The following figure shows the MaxCompute architecture.
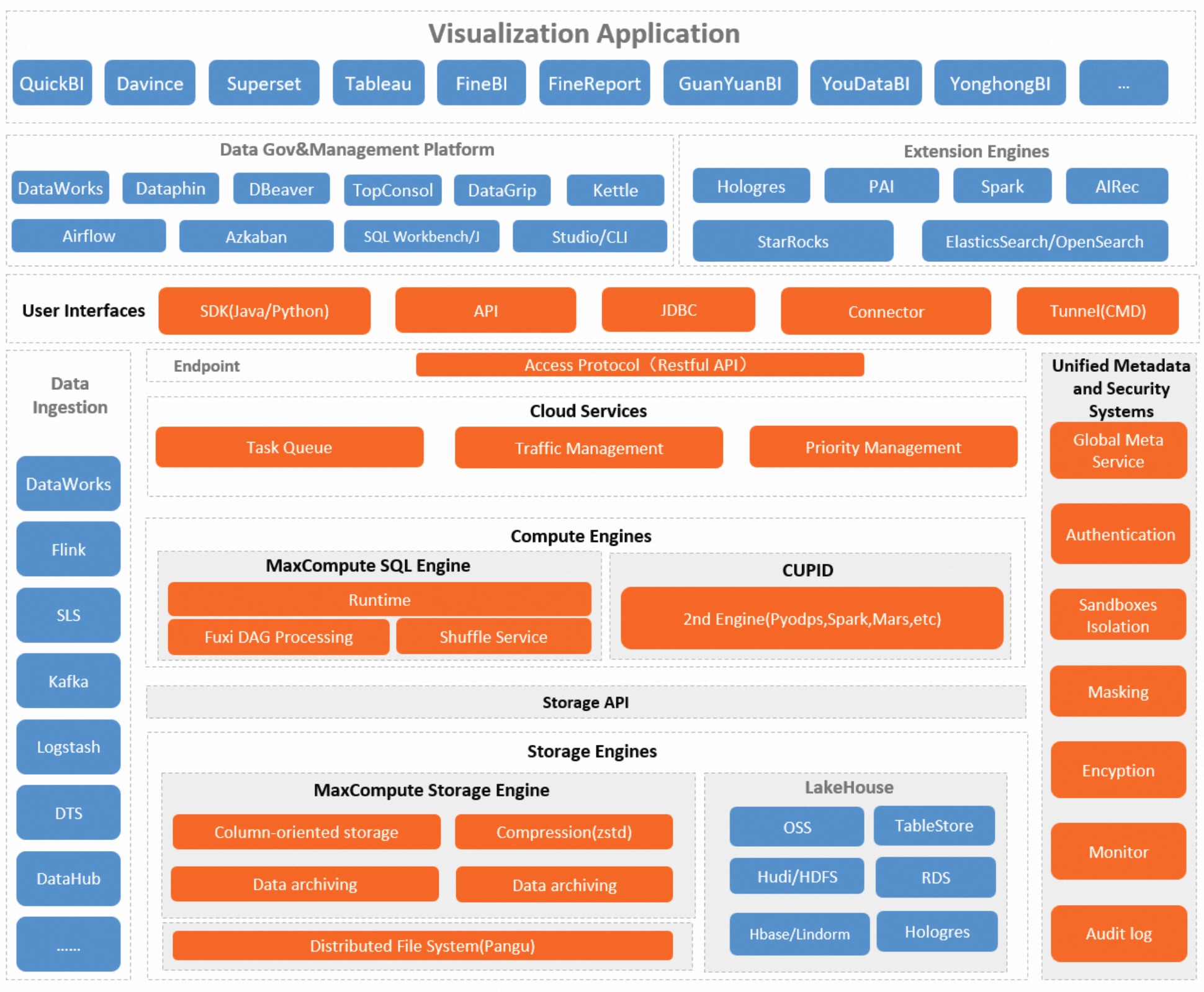
The core modules are described below.
Module | Description |
Storage engine | MaxCompute provides the MaxCompute Storage Engine (internal storage) to store MaxCompute tables and resources. You can also directly read data stored in other products like OSS, Tablestore, and RDS using external tables. The MaxCompute Storage Engine primarily uses Columnar Storage, which typically achieves a 5x compression ratio. |
Compute engine | MaxCompute provides the MaxCompute SQL Compute Engine and the CUPID computing platform.
|
Cloud service layer | MaxCompute allows you to create different task queues and configure unique resources and priorities for each, enabling fine-grained control over task execution. To enhance overall system efficiency, its powerful scheduling system manages and optimizes the allocation and use of computing resources. To ensure data security and privacy, MaxCompute also provides multi-layered data protection, including project-level isolation, access control, and data encryption. |
Unified metadata and security systems | MaxCompute's offline, tenant-level metadata is provided through Information Schema. You can also use Information Schema to query historical usage data logs, enabling you to analyze metrics like resource consumption, run duration, and data processed. This helps you optimize jobs or plan resource capacity. MaxCompute also offers a comprehensive security management system with features like access control, data encryption, and dynamic data masking to ensure data security. For more security-related information, see Security features. |
User interfaces and openness | MaxCompute provides the following user interfaces:
|
Data ecosystem support | MaxCompute is deeply integrated with Alibaba Cloud DataWorks to provide one-stop data development, analytics, and governance. It also supports various other data development and analysis scenarios:
|
TopConsole (MaxCompute console) | Provides basic configuration and management capabilities, including MaxCompute project management, quota management, and tenant management. It also offers fundamental O&M features like job O&M and resource observation, as well as enhanced features like materialized views and cost analytics and optimization. For more information, see Resource management and use. |
Product advantages
MaxCompute offers the following key advantages:
Easy to use
High-performance storage and compute optimized for data warehousing.
Pre-integrated with services and supports standard SQL for simple development.
Built-in management and security capabilities.
Fully managed with a pay-as-you-go model; you incur no compute costs when not in use.
Elasticity that matches business growth
With decoupled storage and compute, resources scale independently and dynamically. This on-demand elasticity meets sudden business growth without upfront capacity planning.
Support for various analytics scenarios
Supports an open data ecosystem, providing a unified platform for data warehousing, BI, Near-real-time Analytics, Data Lake Analysis, and Machine Learning.
Open platform
Provides open APIs and a rich ecosystem, offering flexibility for data and application migration and Custom Development.
Flexibly combines with open-source and commercial products like Airflow and Tableau to build a wide range of data applications.
Contact us
If you have any questions or suggestions while using MaxCompute, please fill out the DingTalk group application form to join our DingTalk group for feedback.