After the data opening package is installed, you can use the data opening feature to obtain the metadata of a node. Before you perform this operation, make sure that the node has generated the latest metadata. Otherwise, you may fail to obtain the metadata. This topic describes how to use an ancestor node to check whether the data opening feature has obtained the metadata of a node.
Background information
Based on the dependency principles of nodes in DataWorks, the system runs a node only after the ancestor node of the node is successfully run. To check whether the data opening feature has obtained the metadata of a node (Node A), create a node (Node B) and configure Node B as the ancestor node of Node A. If Node B detects that the data opening feature has obtained the metadata of Node A, the running of Node B is complete. The following figure shows the process. 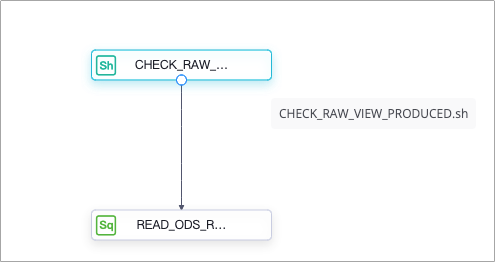 The process involves the following two nodes:
The process involves the following two nodes:
The
CHECK_RAW_VIEW_PRODUCED.shnode is created to check whether the data opening feature has obtained the metadata of the READ_ODS_RAW_DATA.sql node. If the CHECK_RAW_VIEW_PRODUCED.sh node detects that the metadata has been obtained, the running of the CHECK_RAW_VIEW_PRODUCED.sh node is complete. Then, the system starts to run the READ_ODS_RAW_DATA.sql node.READ_ODS_RAW_DATA.sqlis the node for which you want to check whether the data opening feature has obtained the metadata.
This topic only describes how to use the data opening feature to check whether the data opening feature has obtained the metadata of a node. For more information about how to use this feature, see Use the data opening feature.
You can use a Shell node as an ancestor node to check whether the data opening feature has obtained the metadata of a node.
You must use an Alibaba Cloud account that has permissions to access the data opening package and create task instances in the current MaxCompute project.
To ensure both data and node security, we recommend that you use a RAM user of the Alibaba Cloud account. In addition, assign the visitor role and grant only the read permissions on the data opening package to the RAM user.
You can refer to the following steps to check whether the data opening feature has obtained the metadata of a node:
Create a RAM user and grant permissions to the RAM user
This section describes how to create a RAM user and grant permissions to the RAM user.
Create a RAM user.
To ensure data security, we recommend that you do not authorize the RAM user to log on to the Alibaba Cloud Management Console but only create an AccessKey pair for the RAM user. For more information about how to create a RAM user, see Prepare a RAM user. In this example, a RAM user named
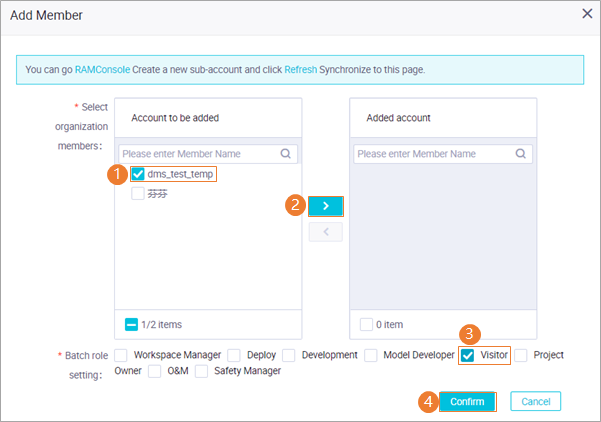
dw_odps_testis created.Assign the visitor role to the RAM user.
Add the RAM user to the required DataWorks workspace and assign the visitor role that has the minimum permissions to the RAM user. For more information, see Add workspace members and assign roles to them.
Grant the read permissions on the data opening package to the RAM user.
To enable the RAM user to read the data provided by the data opening package of DataWorks, you must grant the read permissions on the data opening package to the RAM user. In addition, you must grant the CreateInstance permission to the RAM user. This way, the RAM user can create task instances in the MaxCompute project when it reads data from the data opening package. For more information, see Grant a role or user.
-- Authorize the RAM user to create task instances in the MaxCompute project GRANT CreateInstance ON PROJECT {Name of the MaxCompute project for which the DataWorks data opening package is installed} TO USER RAM$ {The Alibaba Cloud account of the RAM user}: dw_odps_test; -- Authorize the RAM user to read data from the data opening package (In this example, the RAM user is authorized to read data from a data opening package installed for a MaxCompute project that resides in the China (Hangzhou) region. For data in the data opening package installed for a MaxCompute project that resides in another region, change the region information in the project name.) GRANT READ ON PACKAGE u_meta_hangzhou.systables TO USER RAM$ (The Alibaba Cloud account of the RAM user): dw_odps_test; -- View the authorization result show grants for RAM${The Alibaba Cloud account of the RAM user}: dw_odps_test;The following code provides an authorization example:
-- Authorization example [roles] role_project_guest Authorization Type: ACL [user/RAM${The Alibaba Cloud account of the RAM user}: dw_odps_test] A projects/{Name of the MaxCompute project for which the DataWorks data opening package is installed}: CreateInstance A projects/{Name of the MaxCompute project for which the DataWorks data opening package is installed}/packages/u_meta_hangzhou.systables: Read
Check whether the data opening package has obtained the metadata of a node
You can create a Shell node and configure it as the ancestor node of the node for which you want to check whether the data opening feature has obtained the metadata.
Create a Shell node. For more information about how to create a Shell node, see Create a Shell node.
Compile code for the Shell node.
In the following example, the raw_v_meta_database_v1_1 view in the data opening package installed for a MaxCompute project that resides in the China (Hangzhou) region is used to query whether the data opening feature has obtained the metadata of a node. Where:
u_meta_hangzhou specifies the name of the MaxCompute project for which the data opening package is installed. This project resides in the China (Hangzhou) region. You can change the region information in the project name based on your business requirements. For more information about u_meta project names in different regions, see Appendix 2: Available data opening packages.
raw_v_meta_database_v1_1 is a view that is provided by the data opening package for querying the metadata of a node. You can change the view name in the following code to the name of the view that you want to use. For more information about the views provided by the data opening package, see Appendix 1: List and structure details of tables and views.
## check if specified view had been produced already # $1 view name to check # $2 bizdate to check # $3 endpoint for this odps project # $4 name of this odps project # $5 AccessKey id being used # $6 AccessKey secret being used function checkIfSpecifiedViewProduced() { CHECK_SQL="SELECT CASE WHEN COUNT(*) > 0 THEN 'PRODUCED_ALREADY' ELSE 'NOT_PRODUCED_YET' END AS PRODUCE_FLAG FROM u_meta_hangzhou.$1('$2')" /opt/taobao/tbdpapp/odpswrapper/odpsconsole/bin/odpscmd --endpoint=$3 --project=$4 -u $5 -p $6 -e "$CHECK_SQL" | grep --color "PRODUCED_ALREADY" return $? } ## check if view raw_v_meta_database_v1_1 had been produced already checkIfSpecifiedViewProduced "raw_v_meta_database_v1_1" $1 $2 $3 $4 $5 RET_VAL=$? while [ $RET_VAL -ne 0 ] do echo "DataWorks open data was NOT produced yet, sleep for 300 seconds" sleep 300 checkIfSpecifiedViewProduced "raw_v_meta_database_v1_1" $1 $2 $3 $4 $5 RET_VAL=$? done echo "DataWorks opend data was produced already."NoteIn the preceding code,
sleep 300specifies the interval between two checks (unit: seconds) if no metadata is obtained by using the raw_v_meta_database_v1_1 view. You can change the value of sleep based on the actual situation of the project.
Configure dependencies for the Shell node
The following items must be configured for the Shell node:
Scheduling dependency
The Shell node must be configured as the ancestor node of the node for which you want to check whether the data opening feature has obtained the metadata. Therefore, you must configure the output of the Shell node as the input of the node. This way, a dependency is established between the node and Shell node. For more information, see Configure same-cycle scheduling dependencies.
Parameters
The code of the Shell node contains the following custom parameters. You must also configure these custom parameters in the General section of the Properties tab. Separate these parameters with spaces. For more information, see Supported formats of scheduling parameters.
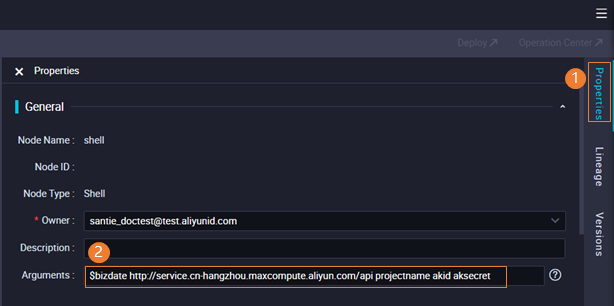
Parameter 1: $bizdate, which specifies the date on which the business was performed. This parameter is equivalent to ${yyyymmdd}.
Parameter 2: a character constant parameter, which can be set to the endpoint of MaxCompute in a specific region.
For example, your MaxCompute service is activated in the China (Hangzhou) region. In this case, set this parameter to
http://service.cn-hangzhou.maxcompute.aliyun.com/api. For more information about the endpoints of MaxCompute in other regions, see Endpoints.Parameter 3: a character constant parameter, which can be set to the name of the MaxCompute project for which the data opening package is installed.
Parameter 4: a character constant parameter, which can be set to the AccessKey ID of the RAM user. For more information about how to obtain an AccessKey ID, see Obtain an AccessKey pair.
Parameter 5: a character constant parameter, which can be set to the AccessKey secret of the RAM user. For more information about how to obtain an AccessKey secret, see Obtain an AccessKey pair.
What to do next
After the Shell node is configured, you can refer to the instructions in Use the data opening feature to create a node for which you want to check whether the data opening feature has obtained the metadata and configure the node. After you commit the node, the Shell node starts to check whether the data opening feature has obtained the metadata of the node. If the Shell node detects that the data opening feature has obtained the metadata of the node, the running of the Shell node is complete. Then, the system starts to run the node. This ensures that you can obtain your desired metadata from the data opening package.