This topic describes how the optimizer and executor of PolarDB-X process JOIN operations and subqueries. A JOIN operation is an operation that combines rows from multiple tables based on one or more common columns among these tables. A subquery is a SELECT statement that is nested inside the WHERE or HAVING clause of a query.
Concepts
JOIN operations are commonly used in SQL queries. The semantics of JOIN is equivalent to calculating the Cartesian product of two tables and then retaining the data that meets the filter conditions. In most cases, equi-joins are used. An equi-join is used to combine two tables based on the values of a specified column.
A subquery is a query nested inside another SQL query. The result of a subquery is passed to the outer query and then used to process the outer query. Subqueries can be used in different components of an SQL statement. For example, a subquery can be used as the output data in a SELECT clause, an input view in a FROM clause, or a filter condition in a WHERE clause.
The JOIN operations described in this topic are executed at the computing layer. The MySQL engine at the storage layer determines how to execute the JOIN operations that are pushed down to LogicalView.
Types of JOIN operations
PolarDB-X 1.0 supports the following common JOIN operation types: inner joins, left outer joins, and right outer joins.
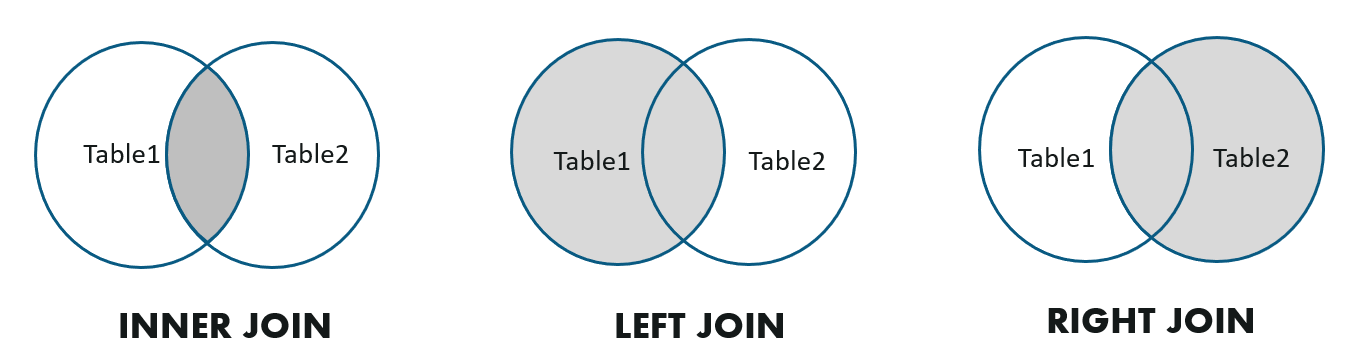
The following examples show different types of JOIN operations:
/* Inner Join */
SELECT * FROM A, B WHERE A.key = B.key;
/* Left Outer Join */
SELECT * FROM A LEFT JOIN B ON A.key = B.key;
/* Right Outer Join */
SELECT * FROM A RIGHT OUTER JOIN B ON A.key = B.key;PolarDB-X 1.0 also supports semi joins and anti joins. Semi joins and anti joins cannot be written in SQL. They are implemented by using subqueries nested inside an EXISTS or IN condition.
The following code provide examples of semi joins and anti joins:
/* Semi Join - 1 */
SELECT * FROM Emp WHERE Emp.DeptName IN (
SELECT DeptName FROM Dept
)
/* Semi Join - 2 */
SELECT * FROM Emp WHERE EXISTS (
SELECT * FROM Dept WHERE Emp.DeptName = Dept.DeptName
)
/* Anti Join - 1 */
SELECT * FROM Emp WHERE Emp.DeptName NOT IN (
SELECT DeptName FROM Dept
)
/* Anti Join - 2 */
SELECT * FROM Emp WHERE NOT EXISTS (
SELECT * FROM Dept WHERE Emp.DeptName = Dept.DeptName
)JOIN algorithms
PolarDB-X 1.0 supports multiple distributed join algorithms, such as nested loop join, hash join, sort-merge join, and lookup join. Lookup join is also known as BKA join.
Nested-Loop Join (NLJoin)
Nested loop joins are commonly used for non-equi joins. A nested loop join works in the following way:
Selects all rows from the inner table and caches the rows in memory. The inner table refers to the right table that contains less data in most cases.
Scans the entire outer table, compares each row in the outer table to the inner table, and creates a result set.
Checks whether the result set meets the join condition, and returns the result set if the condition is met.
The following code provides an example of a nested loop join:
> EXPLAIN SELECT * FROM partsupp, supplier WHERE ps_suppkey < s_suppkey;
NlJoin(condition="ps_suppkey < s_suppkey", type="inner")
Gather(concurrent=true)
LogicalView(tables="partsupp_[0-7]", shardCount=8, sql="SELECT * FROM `partsupp` AS `partsupp`")
Gather(concurrent=true)
LogicalView(tables="supplier_[0-7]", shardCount=8, sql="SELECT * FROM `supplier` AS `supplier`")In most cases, nested loop join is the least efficient join algorithm. Nested loop joins can be used only in the following scenarios: The join is a non-equi join as shown in the preceding example or the inner table contains a small amount of data.
You can use the following hint to force PolarDB-X 1.0 to use nested loop joins and specify the join order:
/*+TDDL:NL_JOIN(outer_table, inner_table)*/ SELECT ...You can also use the result of joining multiple tables as the inner_table or outer_table, as shown in the following example:
/*+TDDL:NL_JOIN((outer_table_a, outer_table_b), (inner_table_c, inner_table_d))*/ SELECT ...The hints in other examples work in the same way.
Hash Join
Hash join is one of the most commonly used join algorithms for equi-joins. A hash join works in the following way:
Selects all rows from the inner table and writes rows into a hash table stored in memory. The inner table refers to the right table that contains less data in most cases.
Scans the entire outer table. For each row in the outer table:
Scans the hash table against the join key in the equality condition and selects 0 to N rows that have the same join key.
Creates a result set, checks whether the result set meets the join condition, and returns the result set if the condition is met.
The following code provides an example of a hash join:
EXPLAIN SELECT * FROM partsupp, supplier WHERE ps_suppkey = s_suppkey;
HashJoin(condition="ps_suppkey = s_suppkey", type="inner")
Gather(concurrent=true)
LogicalView(tables="partsupp_[0-7]", shardCount=8, sql="SELECT * FROM `partsupp` AS `partsupp`")
Gather(concurrent=true)
LogicalView(tables="supplier_[0-7]", shardCount=8, sql="SELECT * FROM `supplier` AS `supplier`")Hash joins are commonly used in complex queries that join large amounts of data but cannot be optimized by index lookup. In this case, hash join is the optimal algorithm. In the preceding example, the system must perform full table scans on the partsupp and supplier tables. This involves large amounts of data. Therefore, hash joins are suitable for this scenario.
The inner table of a hash join is used to create a hash table stored in memory. Ensure that the inner table contains less data than the outer table. In most cases, the optimizer can automatically choose the optimal join order. If manual control is required, you can use the following hint to force PolarDB-X 1.0 to use hash joins and specify the join order:
/*+TDDL:HASH_JOIN(table_outer, table_inner)*/ SELECT ...Lookup Join (BKAJoin)
Lookup join is another join algorithm for equi-joins and is commonly used in scenarios where a small amount of data is involved. A lookup join works in the following way:
Scans the entire outer table. The outer table refers to the left table that contains less data in most cases. For each batch (for example, every 1,000 rows) from the outer table:
Creates an
IN (...)condition that uses the join key of the rows in the batch, and then adds the condition to the inner table query.Executes the inner table query to select the rows that meet the join condition.
Maps each row in the outer table to a row in the inner table based on a hash table, merges the rows from the inner and outer tables, and then returns the result.
The following code provides an example of a lookup join (BKA join)
EXPLAIN SELECT * FROM partsupp, supplier WHERE ps_suppkey = s_suppkey AND ps_partkey = 123;
BKAJoin(condition="ps_suppkey = s_suppkey", type="inner")
LogicalView(tables="partsupp_3", sql="SELECT * FROM `partsupp` AS `partsupp` WHERE (`ps_partkey` = ?)")
Gather(concurrent=true)
LogicalView(tables="supplier_[0-7]", shardCount=8, sql="SELECT * FROM `supplier` AS `supplier` WHERE (`s_suppkey` IN ('?'))")Lookup joins are suitable for scenarios in which the outer table contains a small amount of data. In the preceding example, only a few rows are selected from the left table partsupp due to the filter condition ps_partkey = 123. In addition, the s_suppkey IN (...) condition matches the primary key index of the right table. This reduces the cost of the lookup join.
You can use the following hint to force PolarDB-X 1.0 to use lookup joins and specify the join order:
/*+TDDL:BKA_JOIN(table_outer, table_inner)*/ SELECT ...The inner table of a lookup join must be a single table but not the result of joining multiple tables.
Sort-Merge Join
Sort-merge join is another join algorithm for equi-joins. A sort-merge join is reliant on the orders of the input rows in the left and right tables. The input rows must be sorted based on the join key. A sort-merge join works in the following way:
Uses MergeSort or MemSort to sort the input rows.
Compares the input rows in the left and right tables by using the following methods:
Matches the current right row against the next left row If the join key of the current left row is smaller than that of the current right row.
Matches the current left row against the next right row If the join key of the current right row is smaller than that of the current left row.
Merges the left and right rows if the two rows have the same join key and the join condition is met, and then returns the result.
The following code provides an example of sort-merge joins:
EXPLAIN SELECT * FROM partsupp, supplier WHERE ps_suppkey = s_suppkey ORDER BY s_suppkey;
SortMergeJoin(condition="ps_suppkey = s_suppkey", type="inner")
MergeSort(sort="ps_suppkey ASC")
LogicalView(tables="QIMU_0000_GROUP,QIMU_0001_GROUP.partsupp_[0-7]", shardCount=8, sql="SELECT * FROM `partsupp` AS `partsupp` ORDER BY `ps_suppkey`")
MergeSort(sort="s_suppkey ASC")
LogicalView(tables="QIMU_0000_GROUP,QIMU_0001_GROUP.supplier_[0-7]", shardCount=8, sql="SELECT * FROM `supplier` AS `supplier` ORDER BY `s_suppkey`")The MergeSort operator in the preceding execution plan and the ORDER BY operator that is pushed down ensure that the input rows in the left and right tables of a sort-merge join are sorted based on the join key s_suppkey (ps_suppkey).
Sort-merge join is not the optimal join algorithm because it must sort input rows first. However, users may want to sort the query result based on the join key, as shown in the preceding example. In this case, sort-merge join is the optimal choice.
You can use the following hint to force PolarDB-X 1.0 to use sort-merge joins:
/*+TDDL:SORT_MERGE_JOIN(table_a, table_b)*/ SELECT ...Order of JOIN operations
In scenarios where multiple tables are joined, the optimizer must decide the order in which the tables are joined. This is because the join order affects the size of the intermediate result set and the cost of the execution plan.
For example, a JOIN operation is performed on four tables and is not pushed down. In this case, the following join trees are applicable. In addition, the four tables can be sorted in up to 24 (the result of 4!) ways. As a result, up to 72 different join orders are available.
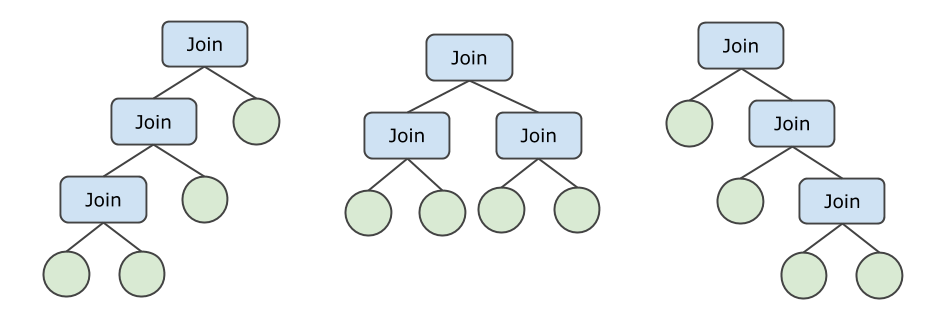
PolarDB-X 1.0 uses an adaptive strategy to create the optimal execution plan for a given JOIN operation that is performed on N tables.
If the JOIN operation is not pushed down and the value of N is small, the bushy tree is used to create the optimal execution plan.
If the JOIN operation is not pushed down and the value of N is large, the zig-zag or left-deep tree is used to create the optimal execution plan. This reduces the number of times of numerations and cost.
PolarDB-X 1.0 uses a cost-based optimizer to select the join order that incurs the lowest cost. For more information, see Introduction to the query optimizer.
In addition, different join algorithms have different preferences for the left and right tables. For example, the right table of a hash join is the inner table and is used to create a hash table. Therefore, specify the table that contains less data as the right table. The cost-based optimizer also has similar preferences.
Subqueries
A subquery is classified as a non-correlated subquery or a correlated subquery based on whether it uses values from the outer query. A non-correlated subquery is executed independent of the variables of the outer query. In most cases, non-correlated subqueries are executed only once. A correlated subquery uses variables from the outer query. A correlated subquery is executed on each input row because the subquery must use the values of the variables from the outer query.
/* An example of non-correlated subqueries. */
SELECT * FROM lineitem WHERE l_partkey IN (SELECT p_partkey FROM part);
/* An example of correlated subqueries. l_suppkey is the column referenced from the outer query. */
SELECT * FROM lineitem WHERE l_partkey IN (SELECT ps_partkey FROM partsupp WHERE ps_suppkey = l_suppkey);PolarDB-X 1.0 supports most SQL subqueries. For more information, see SQL limits.
PolarDB-X 1.0 can convert common subqueries to SEMIJOIN statements or JOIN statements to improve execution efficiency. This way, the system no longer needs to iterate a group of nested parameters if a large amount of data is involved. This significantly reduces the execution cost. This subquery conversion method is known as unnesting.
The following example shows how PolarDB-X unnests a subquery by replacing it with JOIN statements in the execution plan.
EXPLAIN SELECT p_partkey, (
SELECT COUNT(ps_partkey) FROM partsupp WHERE ps_suppkey = p_partkey
) supplier_count FROM part;
Project(p_partkey="p_partkey", supplier_count="CASE(IS NULL($10), 0, $9)", cor=[$cor0])
HashJoin(condition="p_partkey = ps_suppkey", type="left")
Gather(concurrent=true)
LogicalView(tables="part_[0-7]", shardCount=8, sql="SELECT * FROM `part` AS `part`")
Project(count(ps_partkey)="count(ps_partkey)", ps_suppkey="ps_suppkey", count(ps_partkey)2="count(ps_partkey)")
HashAgg(group="ps_suppkey", count(ps_partkey)="SUM(count(ps_partkey))")
Gather(concurrent=true)
LogicalView(tables="partsupp_[0-7]", shardCount=8, sql="SELECT `ps_suppkey`, COUNT(`ps_partkey`) AS `count(ps_partkey)` FROM `partsupp` AS `partsupp` GROUP BY `ps_suppkey`")However, PolarDB-X 1.0 cannot unnest subqueries in some scenarios. In these scenarios, a query can be executed only after the subqueries are executed. If the outer query involves a large amount of data, the iteration may be time-consuming.
In the following example, the subquery cannot be unnested because the value of l_partkey is less than 50 in specific rows. Therefore, PolarDB-X performs a nested iteration.
EXPLAIN SELECT * FROM lineitem WHERE l_partkey IN (SELECT ps_partkey FROM partsupp WHERE ps_suppkey = l_suppkey) OR l_partkey IS NOT
Filter(condition="IS(in,[$1])[29612489] OR l_partkey < ?0")
Gather(concurrent=true)
LogicalView(tables="QIMU_0000_GROUP,QIMU_0001_GROUP.lineitem_[0-7]", shardCount=8, sql="SELECT * FROM `lineitem` AS `lineitem`")
>> individual correlate subquery : 29612489
Gather(concurrent=true)
LogicalView(tables="QIMU_0000_GROUP,QIMU_0001_GROUP.partsupp_[0-7]", shardCount=8, sql="SELECT * FROM (SELECT `ps_partkey` FROM `partsupp` AS `partsupp` WHERE (`ps_suppkey` = `l_suppkey`)) AS `t0` WHERE (((`l_partkey` = `ps_partkey`) OR (`l_partkey` IS NULL)) OR (`ps_partkey` IS NULL))")To improve the execution efficiency, we recommend that you delete the OR condition and rewrite the SQL statement.