EMR Remote Shuffle Service (ESS) is an extension for E-MapReduce (EMR) that replaces the default shuffle mechanism with a dedicated remote service, reducing connection overhead, disk pressure, and memory usage for large-scale Apache Spark jobs.
Limitations
ESS applies only to the following EMR versions:
EMR V4.X.X
Versions earlier than EMR V3.39.1
Versions earlier than EMR V5.5.0
For EMR V3.39.1 and later, or EMR V5.5.0 and later, use RSS instead.
How it works
Traditional shuffle has several structural problems at scale:
| Problem | Impact |
|---|---|
| Large shuffle write tasks overflow to disk | Write amplification |
| Small network packets accumulate during shuffle read | Connection resets |
| Many small I/O requests with random reads | High disk and CPU load |
| M mappers x N reducers produce M x N connections | Jobs fail to run at scale |
| Spark shuffle service runs on NodeManager; extreme data volumes cause NodeManager restarts | YARN scheduling instability |
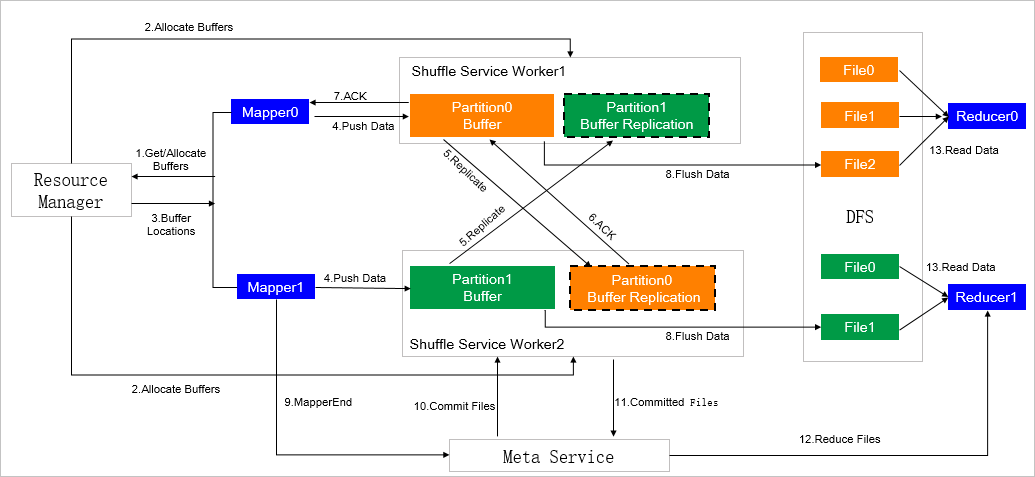
ESS addresses each of these:
| Solution | How it helps |
|---|---|
| Push-based shuffle (instead of pull-based) | Reduces mapper memory pressure |
| I/O aggregation | Cuts shuffle read connections from M x N to N; converts random reads to sequential reads |
| Two-replica mechanism | Reduces fetch failure probability |
| Compute-storage separation | Shuffle service runs on dedicated hardware, independent of compute nodes |
| No local disk dependency | Enables Spark on Kubernetes without local disk requirements |
The following figure shows the ESS architecture.
Create a cluster with ESS
The following steps use EMR V4.5.0 as an example. Create an EMR cluster with ESS using either of these cluster types:
EMR Shuffle Service cluster — a cluster type dedicated to shuffle offloading.
EMR Hadoop cluster — a general-purpose cluster that also supports ESS.
For cluster creation steps, see Create a cluster.
Submit a Spark job with ESS
When submitting a Spark job, add the required parameters below. For how to configure job parameters in EMR, see Edit jobs. For the full list of Spark configuration options, see Spark Configuration.
Required parameters
These parameters must be set for every Spark job that uses ESS.
| Parameter | Value | Notes |
|---|---|---|
spark.shuffle.manager | org.apache.spark.shuffle.ess.EssShuffleManager | Switches Spark to use the ESS shuffle manager |
spark.ess.master.address | <ess-master-ip>:9097 | Public IP address of the master node; port is always 9097 |
spark.shuffle.service.enabled | false | Disables the built-in external shuffle service, which conflicts with ESS |
Compatibility parameters
Set these parameters to ensure compatibility.
| Parameter | Value | Notes |
|---|---|---|
spark.shuffle.useOldFetchProtocol | true | ESS uses the original shuffle fetch protocol |
spark.sql.adaptive.enabled | false | ESS does not support Adaptive Query Execution (AQE) |
Disabling AQE (spark.sql.adaptive.enabled=false) also disables spark.sql.adaptive.skewJoin.enabled.
ESS service parameters
View and edit these parameters on the ESS service configuration page.
Memory parameters
| Parameter | Description | Default |
|---|---|---|
ess_master_memory | Heap memory of the master node | 4g |
ess_worker_memory | Heap memory of each core node | 4g |
ess_worker_offheap_memory | Off-heap memory of each core node | 4g |
Flush buffer parameters
| Parameter | Description | Default |
|---|---|---|
ess.worker.flush.buffer.size | Size of each flush buffer. Flushing triggers when this size is exceeded. Unit: KB | 256k |
ess.worker.flush.queue.capacity | Number of flush buffers per directory | 512 |
Heap memory estimation: Heap memory used per directory is calculated as:
heap memory per directory = ess.worker.flush.buffer.size x ess.worker.flush.queue.capacityExample with default values and 28 directories:
per directory: 256 KB x 512 = 128 MB
total memory: 128 MB x 28 = 3.5 GB
total slots: 512 x 28 / 2 = 7,168Each directory provides slots equal to half of ess.worker.flush.queue.capacity. To improve read/write throughput, configure a maximum of two directories per disk.
Timeout and reliability parameters
| Parameter | Description | Default |
|---|---|---|
ess.flush.timeout | Timeout for flushing data to the storage layer. Unit: seconds | 240s |
ess.application.timeout | Heartbeat timeout. After this period, application resources are released. Unit: seconds | 240s |
ess.push.data.replicate | Enables the two-replica mechanism (true/false). Enable in production to reduce fetch failures. | true |
Monitoring parameters
| Parameter | Description | Default |
|---|---|---|
ess.metrics.system.enable | Enables monitoring (true/false) | false |
What's next
RSS — the Remote Shuffle Service available for EMR V3.39.1 and later, or EMR V5.5.0 and later
Edit jobs — configure Spark job parameters in EMR
Spark Configuration — full reference for Spark configuration options