This topic describes the features of MongoDB 4.4. Alibaba Cloud is an official strategic partner of MongoDB and the first cloud provider to introduce MongoDB 4.4 in its service. It released ApsaraDB for MongoDB V4.4 in November 2020. MongoDB 4.4 was officially released on July 30, 2020. Compared with previous major versions, MongoDB 4.4 is a fully enhanced version that addresses main issues of previous versions that attract user attention.
Hidden indexes
Although a large number of indexes degrade write performance, complex data makes it difficult for O&M engineers to delete potentially ineffective indexes. If effective indexes are deleted by accident, jitter may occur. Furthermore, the cost to recreate the accidentally deleted indexes is high.
To solve these problems, Alibaba Cloud and MongoDB jointly developed the hidden index feature as strategic partners. For more information, see the ApsaraDB for MongoDB product page. This feature allows you to use the collMod command to hide indexes. Hidden indexes are not used in subsequent queries. If hidden indexes do not cause errors, the indexes can be deleted.
Syntax:
db.runCommand( {
collMod: 'testcoll',
index: {
keyPattern: 'key_1',
hidden: false
}
} )Hidden indexes are invisible only to the query planner of MongoDB. The indexes retain some index features such as unique index constraint and time to live (TTL) expiration.
Hidden indexes become active immediately after you unhide them because indexes continue to be updated when they are hidden.
Refinable shard keys
A shard key assumes a vital role in a sharded cluster. The shard key can make the sharded cluster more scalable under a specified workload. However, in actual use of MongoDB, workload changes may lead to jumbo chunks or query hotspots on a single shard even if you carefully select the shard key. Jumbo chunks are the chunks that grow beyond a specified chunk size.
In MongoDB 4.0 and earlier, the shard key for a collection and the shard key value are immutable. In MongoDB 4.2 and later, you can change the shard key value. However, to change the shard key value, you must migrate data across shards based on distributed transactions. This mechanism has high performance overheads and is unable to prevent jumbo chunks and query hotpots. For example, if you use the {customer_id:1} shard key to shard an order collection, the shard key is sufficient in the early stage of an enterprise because the number of orders placed by each customer is small. However, as the enterprise develops, if a major customer places more and more orders, frequent queries are made to the order collection and single-shard query hotspots may occur. An order has close relationships with the customer_id field, uneven queries cannot be solved by changing the customer_id field.
In this case, you can use the refineCollectionShardKey command that is provided by MongoDB 4.4 to add one or more suffix fields to the existing shard key. This way, a more fine-grained data distribution is used for documents and jumbo chunks are prevented. For example, you can use the refineCollectionShardKey command to change the shard key to {customer_id:1, order_id:1}. This way, single-shard query hotspots can be prevented.
The refineCollectionShardKey command has low performance overheads because this command modifies only the metadata on the config server node and does not migrate data. Data is gradually distributed when chunks are split or migrated to other shards. A shard key must be supported by an index. You must create an index that supports the new shard key before you run the refineCollectionShardKey command.
The suffix fields are not stored in all documents. To solve this problem, MongoDB 4.4 provides the missing shard key feature. Documents in sharded collections can miss specific shard key fields. The downside of the missing shard key feature is that it may lead to jumbo chunks. We recommend that you do not use this feature unless necessary.
Compound hashed shard keys
Versions earlier than MongoDB 4.4 do not support compound hashed indexes. You can specify only the hash key with a single field. This may lead to uneven data distribution in collections across data shards.
MongoDB 4.4 supports compound hashed indexes. You can specify a single hashed field in compound indexes as the prefix or suffix field.
Syntax:
sh.shardCollection(
"examples.compoundHashedCollection",
{ "region_id" : 1, "city_id": 1, field1" : "hashed" }
)
sh.shardCollection(
"examples.compoundHashedCollection",
{ "_id" : "hashed", "fieldA" : 1}
)You can take full advantage of compound hashed indexes in the following scenarios:
To abide by relevant laws and regulations, you must use the zone sharding feature that is provided by MongoDB to evenly distribute data across shards that reside in a zone.
A collection uses a monotonically increasing value as the shard key. In this case, the value of the
customer_idfield is a monotonically increasing number in the{customer_id:1, order_id:1}shard key. Data from the latest customers is also written to the same shard, which results in a large shard and uneven distribution of data across shards.
If compound hashed indexes are not supported, you must compute the hash value of a single field, store the hash value in a special field of a document as the index value, and then use the ranged sharding feature to specify the index value as your shard key.
In MongoDB 4.4, you need only to specify the field as hashed. In the preceding second scenario, you need only to set the shard key to {customer_id:'hashed', order_id:1}. This simplifies the business logic.
Hedged reads
Network latencies may cause economic loss. A report from Google suggests that if a page takes more than 3 seconds to load, over half of visitors leave the page. For more information about the report, visit 7 Page Speed Stats Every Marketer Should Know. To minimize network latencies, MongoDB 4.4 provides the hedged read feature. In sharded clusters, the mongos nodes route a read operation to two replica set members per queried shard and return results from the first respondent per shard to the client. This way, P95 and P99 latencies are reduced. P95 and P99 latencies indicate that average latencies for the slowest 5% and 1% of requests over the last 10 seconds are within the limits.
Hedged reads are specified per operation as part of the Read Preference parameter. Hedged reads are supported for specific operations. If you set the Read Preference parameter to nearest, the system enables the hedged read feature. If you set the Read Preference parameter to primary, the hedged read feature is not supported. If you set the Read Preference parameter to a value other than nearest or primary, you must set the hedgeOptions parameter to true to enable the hedged read feature. Syntax:
db.collection.find({ }).readPref(
"secondary", // mode
[ { "datacenter": "B" }, { } ], // tag set
{ enabled: true } // hedge options
)The support of mongos nodes for the hedged read feature must also be enabled. To enable the support, you must set the readHedgingMode parameter to on.
Syntax:
db.adminCommand( { setParameter: 1, readHedgingMode: "on" } )Reduced replication latency
MongoDB 4.4 reduces the latency of primary/secondary replication. The latency of primary/secondary replication affects read/write operations in MongoDB. In some scenarios, secondary databases must replicate and apply the incremental updates of primary databases in a short period of time. Otherwise, the secondary databases cannot continue to perform read and write operations. Lower latencies provide better primary/secondary consistency.
Streaming replication
In versions earlier than MongoDB 4.4, secondary databases must poll upstream data to obtain incremental updates. To poll upstream data, a secondary database sends a getMore command to a primary database to scan the oplog collection. If the oplog collection has entries, the secondary database fetches a batch of oplog entries. The batch can be a maximum of 16 MB in size. If the scan reaches the end of the oplog collection, the secondary database uses the awaitData parameter to block the getMore command. When new data is inserted into the oplog collection, the secondary database fetches the next batch of oplog entries. The fetch operation uses the OplogFetcher thread that requires a round trip time (RTT) between the source and destination machines. If the replica set is under poor network conditions, network latency degrades replication performance.
In MongoDB 4.4, a primary database sends a continuous stream of oplog entries to a secondary database instead of waiting for secondary databases to poll upstream data. Compared with the method in which a secondary database polls upstream data, at least half of the RTT is saved for each batch of oplog entries. You can take full advantage of streaming replication in the following scenarios:
If you set the writeConcern parameter to
"majority"for write operations, "majority" write operations must wait for replication multiple times. Even under high-latency network conditions, streaming replication can improve average performance by 50% for"majority"write operations.If you use causal consistent sessions, you can read your own write operations in secondary databases. This feature requires secondary databases to immediately replicate the oplog collection of primary databases.
Simultaneous indexing
Versions earlier than MongoDB 4.4 require you to create indexes in primary databases before you can replicate the indexes to secondary databases. The method to create indexes in secondary databases varies based on different versions. The impacts on the oplog collection in secondary databases vary based on different methods to create indexes in secondary databases.
In MongoDB 4.2, foreground and background indexes are created in the same way. A collection holds the exclusive lock only at the beginning and end of index creation processes. Despite this fine-grained locking method, CPU and I/O overheads of index creation processes cause replication latency. Some special operations may also affect the oplog collection in secondary databases. For example, if you use the collMod command to modify the metadata of a collection, the oplog collection may be blocked. The oplog collection may also enter the Recovering state because the history oplog collection in the primary databases is overridden.
In MongoDB 4.4, indexes are simultaneously created in the primary and secondary databases. This way, the primary/secondary latency is reduced. Secondary databases can read the latest data even during the index creation process.
The indexes can be used only when a majority of voting nodes finish creating the indexes. This can reduce performance differences that are caused by different indexes in read/write splitting scenarios.
Mirrored reads
One common phenomenon in ApsaraDB for MongoDB is that most users who purchase three-node replica set instances perform read and write operations only on the primary node, while the secondary node does not process read traffic. In this case, occasional failover causes noticeable access latency and access speed can be restored to normal only after a period of time. The access latency happens because the elected primary node is processing read traffic for the first time. The elected primary node does not acknowledge the characteristics of the frequently accessed data and has no correspondent cache. After the elected primary node processes read traffic, read operations encounter a large number of cache misses and data must be reloaded from disks. This results in increased access latency. This problem is obvious to instances that have large memory capacities.
MongoDB 4.4 provides the mirrored read feature. The primary node can use mirrored reads to mirror a subset of read operations that it receives and send them to a subset of electable secondary databases. This helps the secondary database pre-warm the cache. Mirrored reads are fire-and-forget operations. Fire-and-forget operations are non-blocking operations that have no impact on the performance of primary databases. However, workloads increase in secondary databases.
You can specify the mirrored read rate by using the mirrorReads parameter. The default rate is 1%.
Syntax:
db.adminCommand( { setParameter: 1, mirrorReads: { samplingRate: 0.10 } } )You can also use the db.serverStatus( { mirroredReads: 1 } ) command to collect statistics of mirrored reads. Syntax:
SECONDARY> db.serverStatus( { mirroredReads: 1 } ).mirroredReads
{ "seen" : NumberLong(2), "sent" : NumberLong(0) }Resumable initial sync
In versions earlier than MongoDB 4.4, a secondary database must restart the entire initial full synchronization process if network interruptions occur. This significantly affects workloads if you have a large volume of data.
In MongoDB 4.4, a secondary database can attempt to resume the synchronization process. If the secondary database cannot resume the initial full synchronization process during a specified period, the system selects a new source and restarts the full synchronization process from the beginning. By default, the secondary database attempts to resume initial synchronization for 24 hours. You can use the replication.initialSyncTransientErrorRetryPeriodSeconds parameter to change the synchronization source when the secondary database attempts to resume the synchronization process.
If the network encounters a non-transient connection error, a secondary database must restart the entire initial full synchronization process.
Time-based oplog retention
In MongoDB, the oplog collection records all operations that modify the data in your database. The oplog collection is a vital infrastructure that can be used for replication, incremental backup, data migration, and data subscription.
The oplog collection is a capped collection. Since MongoDB 3.6, you can use the replSetResizeOplog command to modify the size of the oplog collection. However, you cannot obtain the accurate incremental oplog entries. In the following scenarios, you can use the time-based oplog retention feature:
A secondary node is scheduled to be shut down for maintenance from 02:00:00 to 04:00:00. During this period, the upstream databases may trigger full synchronization due to the missing oplog collection. The full synchronization needs to be prevented.
If exceptions occur, the data subscription components in the downstream databases may fail to provide services. The services are restored within 3 hours at most and incremental data is pulled again. In this case, the lack of incremental data in upstream databases needs to be prevented.
In most scenarios, you need to retain the oplog entries that were generated in the last period. However, the number of oplog entries that were generated in the last period is difficult to determine.
In MongoDB 4.4, you can use the storage.oplogMinRetentionHours parameter to specify the minimum number of hours to preserve an oplog entry. You can use the replSetResizeOplog command to modify the minimum number of hours. Syntax:
// First, show current configured value
db.getSiblingDB("admin").serverStatus().oplogTruncation.oplogMinRetentionHours
// Modify
db.adminCommand({
"replSetResizeOplog" : 1,
"minRetentionHours" : 2
})Union
Versions earlier than MongoDB 4.4 provide the $lookup stage that is similar to the LEFT OUTER JOIN feature in SQL for union query. In MongoDB 4.4, the $unionWith stage provides a similar feature as the UNION ALL operator in SQL. You can use the $lookup stage to combine pipeline results from multiple collections into a single result set, and then query and filter data based on specified conditions. The $unionWith stage differs from the $lookup stage in the support of queries on sharded collections. You can use multiple $unionWith stages to blend multiple collections and aggregate pipelines. Syntax:
{ $unionWith: { coll: "<collection>", pipeline: [ <stage1>, ... ] } }You can also specify different stages in the pipeline parameter to filter data based on specified collections before aggregation. This method is flexible to use. For example, assume that you need to store order data of a business in different collections by table. Syntax:
db.orders_april.insertMany([
{ _id:1, item: "A", quantity: 100 },
{ _id:2, item: "B", quantity: 30 },
]);
db.orders_may.insertMany([
{ _id:1, item: "C", quantity: 20 },
{ _id:2, item: "A", quantity: 50 },
]);
db.orders_june.insertMany([
{ _id:1, item: "C", quantity: 100 },
{ _id:2, item: "D", quantity: 10 },
]);In versions earlier than MongoDB 4.4, if you need a sales report of different products in the second quarter, you must read all the data by yourself and aggregate the data at the application layer. Alternatively, you must use a data warehouse to analyze the data. In MongoDB 4.4, you need only to use a single aggregate statement to aggregate the data. Syntax:
db.orders_april.aggregate( [
{ $unionWith: "orders_may" },
{ $unionWith: "orders_june" },
{ $group: { _id: "$item", total: { $sum: "$quantity" } } },
{ $sort: { total: -1 }}
] )Custom aggregation expressions
To execute complex queries in versions earlier than MongoDB 4.4, you can use the $where operator in the find command. Alternatively, you can run a JavaScript file on the server by using the MapReduce command. However, these methods cannot use the aggregation pipeline.
In MongoDB 4.4, you can use the $accumulator and $function aggregation pipeline operators in place of the $where operator and the MapReduce command. You can define your own custom expressions in JavaScript and execute the expressions on the database server as part of an aggregation pipeline. This way, the aggregation pipeline framework makes it convenient to aggregate complex queries, which enhances user experience.
The $accumulator operator works in a similar way as the MapReduce command. The init function is used to initialize the states for input documents. Then, the accumulate function is used to update the state for each input document and determine whether to execute the merge function.
For example, if you use the $accumulator operator on sharded collections, the merge function is required to merge multiple states. If you also specify the finalize function, the merge function returns the combined result of the merged states based on the result of the finalize function after all documents are processed.
The $function operator works in a similar way as the $where operator. The additional benefit is that the $function operator can work with other aggregation pipeline operators. You can also use the $function operator together with the $expr operator in the find command. This operator combination is equivalent to the $where operator. The MongoDB official manual also suggests to use the $function operator.
New aggregation pipeline operators
In addition to the $accumulator and $function operators, MongoDB 4.4 provides new aggregation pipeline operators for multiple purposes. For example, you can manipulate strings and obtain the last element in an array. You can also obtain the size of a document or binary string. The following table describes the new aggregation pipeline operators.
Operator | Description |
$accumulator | Returns the result of a user-defined accumulator operator. |
$binarySize | Returns the size of a specified string or binary object. Unit: bytes. |
$bsonSize | Returns the size of a specified Binary Javascript Object Notation (BSON)-encoded document. Unit: bytes. |
$first | Returns the first element in an array. |
$function | Defines a custom aggregation expression. |
$last | Returns the last element in an array. |
$isNumber | Returns the Boolean value |
$replaceOne | Replaces the first instance that is matched by a specified string. |
$replaceAll | Replaces all instances that are matched by a specified string. |
Connection monitoring and pooling
In MongoDB 4.4, you can use drivers to configure and monitor connection pooling behaviors. Standard API is required to subscribe to events that are associated with a connection pool. Events include establishing and closing connections in the connection pool, and clearing the connection pool. You can also use APIs to configure connection pool options, such as the maximum or minimum number of connections allowed for a pool, the maximum amount of time that a connection can remain, and the maximum amount of time that a thread can wait for a connection to become available. For more information, visit Connection Monitoring and Pooling.
Global read and write concerns
In versions earlier than MongoDB 4.4, if you do not specify the readConcern or writeConcern parameter for an operation, the default value is used. The default value of readConcern is local, whereas the default value of writeConcern is {w: 1}. These default values cannot be modified. For example, if you want to use "majority" write concerns for all insert operations, you must set the writeConcern parameter to {w: majority} in all MongoDB access code.
In MongoDB 4.4, you can use the setDefaultRWConcern command to specify the global default readConcern and writeConcern settings. Syntax:
db.adminCommand({
"setDefaultRWConcern" : 1,
"defaultWriteConcern" : {
"w" : "majority"
},
"defaultReadConcern" : { "level" : "majority" }
})You can also use the getDefaultRWConcern command to obtain the current global default settings for the readConcern and writeConcern parameters.
When slow query logs or diagnostics logs are also stored in MongoDB 4.4, the provenance of the read or write concern specified by readConcern or writeConcern is logged. The following table describes the possible provenance of a read or write concern.
Provenance | Description |
clientSupplied | The read or write concern is specified in the application. |
customDefault | The read or write concern is specified in the |
implicitDefault | The read or write concern originates from the server in absence of all other read or write concern specifications. |
Another possible provenance is available for write concerns.
Provenance | Description |
getLastErrorDefaults | The write concern originates from the |
New MongoDB Shell (beta)
MongoDB Shell is one of the most common DevOps tools in MongoDB. In MongoDB 4.4, a new version of MongoDB Shell provides enhanced usability features, such as syntax highlighting, command autocomplete, and easy-to-read error messages. The new version is available in beta. More commands are being developed. We recommend that you use the new MongoDB Shell only for trial purposes. 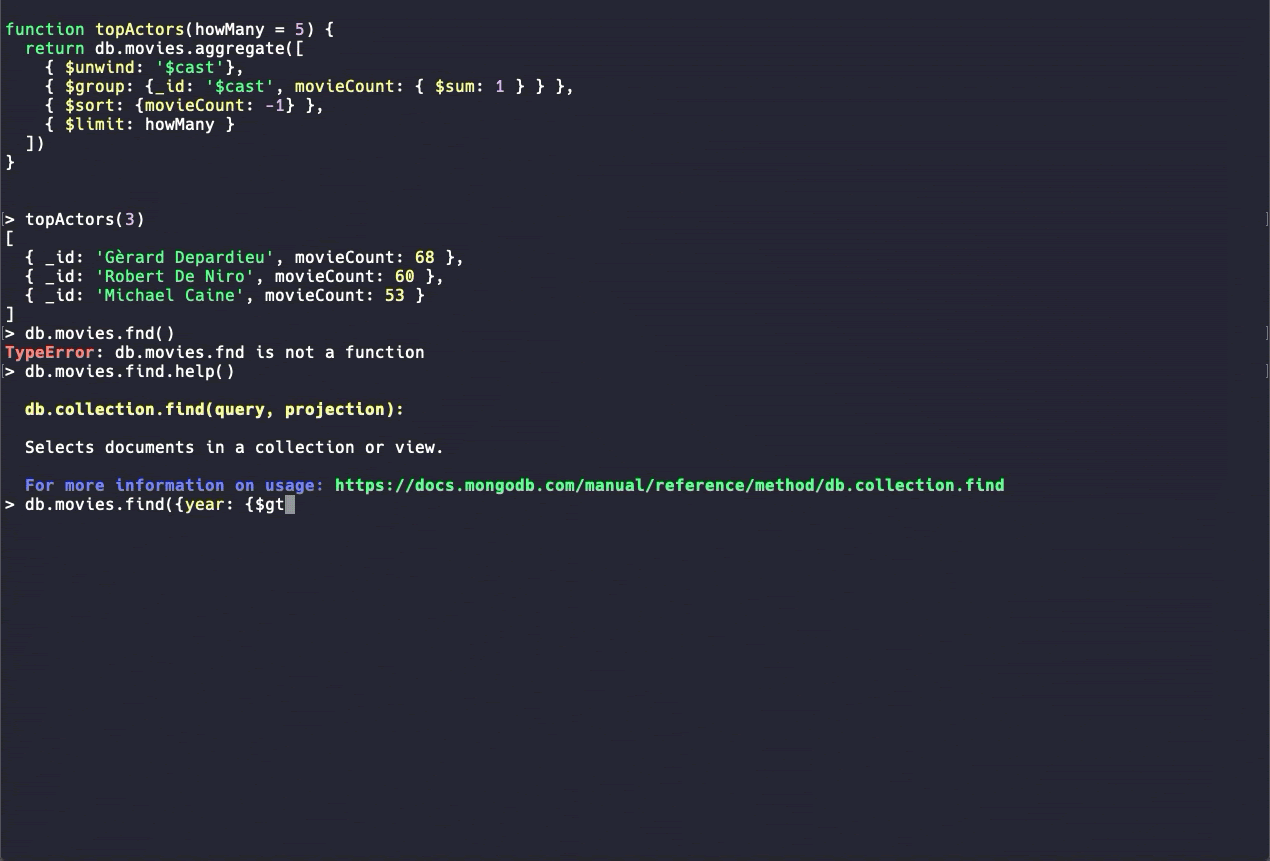
Summary
MongoDB 4.4 is a maintenance release. In addition to the preceding main features, general improvements are provided, such as the optimization of the $indexStats aggregation operator, support for TCP Fast Open (TFO) connections, and optimization of index deletion. Some large enhancements are also available, such as structured logs (logv2) and new authentication mechanism for security.
For more information, visit Release Notes for MongoDB 4.4.