Jindo DistCp supports a wide range of data migration scenarios between Hadoop Distributed File System (HDFS) and Object Storage Service (OSS). This reference covers 13 common scenarios with the exact parameters and commands for each.
Prerequisites
Before you begin, make sure that you have:
An E-MapReduce (EMR) cluster of a supported version. See Create a cluster.
Java Development Kit (JDK) 1.8 installed.
The Jindo DistCp JAR package downloaded for your Hadoop version:
Hadoop 2.7 and later 2.x versions: jindo-distcp-3.0.0.jar
Hadoop 3.x: jindo-distcp-3.0.0.jar
If you are not using EMR, you also need:
Read access to HDFS.
An OSS AccessKey ID, AccessKey secret, and endpoint, with write access to the destination bucket.
An OSS bucket with a storage class other than Archive.
Permission to submit MapReduce tasks.
Use cases
Parameter reference
All scenarios extend the following base command with additional parameters. For full parameter documentation, see Use Jindo DistCp.
hadoop jar jindo-distcp-<version>.jar --src <source> --dest <destination>| Parameter | Description | Constraint |
|---|---|---|
--ossKey | OSS AccessKey ID | — |
--ossSecret | OSS AccessKey secret | — |
--ossEndPoint | OSS endpoint | — |
--parallelism | Number of concurrent copy tasks | — |
--enableBatch | Optimizes performance for large file counts | — |
--diff | Compares source and destination by filename and size; writes missing files to a manifest | — |
--copyFromManifest | Copies only files listed in the manifest | Use with --previousManifest |
--previousManifest | Path to a previously generated manifest file | — |
--outputManifest | Filename for the generated manifest (must end in .gz) | — |
--requirePreviousManifest | Whether a previous manifest is required | — |
--queue | YARN queue name | — |
--bandwidth | Per-mapper bandwidth limit, in MB | — |
--archive | Writes data to OSS Archive storage | — |
--ia | Writes data to OSS Infrequent Access (IA) storage | — |
--enableDynamicPlan | Optimizes job allocation for mixed small and large files | Cannot be used with --enableBalancePlan |
--enableBalancePlan | Optimizes job allocation when file sizes are similar | Cannot be used with --enableDynamicPlan |
--s3Key | AccessKey ID for Amazon S3 | — |
--s3Secret | AccessKey secret for Amazon S3 | — |
--s3EndPoint | Endpoint for Amazon S3 | — |
--outputCodec | Compression codec for copied files. Valid values: gzip, gz, lzo, lzop, snappy, none, keep. Default: keep | — |
--srcPattern | Regular expression to filter which files are copied | — |
--srcPrefixesFile | Path to a file listing source sub-directory paths to copy | — |
--targetSize | Maximum size of merged output files, in MB | Use with --groupBy |
--groupBy | Regular expression defining the merge rule | Use with --targetSize |
--deleteOnSuccess | Deletes source files after a successful copy | — |
Scenario 1: Import large amounts of HDFS data or millions of files to OSS
The base command for copying HDFS data to OSS is:
hadoop jar jindo-distcp-<version>.jar \
--src /data/incoming/hourly_table \
--dest oss://yang-hhht/hourly_table \
--ossKey yourkey \
--ossSecret yoursecret \
--ossEndPoint oss-cn-hangzhou.aliyuncs.com \
--parallelism 10When copying millions or tens of millions of files, increase --parallelism to raise concurrency and add --enableBatch for additional optimization:
hadoop jar jindo-distcp-<version>.jar \
--src /data/incoming/hourly_table \
--dest oss://yang-hhht/hourly_table \
--ossKey yourkey \
--ossSecret yoursecret \
--ossEndPoint oss-cn-hangzhou.aliyuncs.com \
--parallelism 500 \
--enableBatchScenario 2: Verify data integrity after import
Two methods are available to verify a completed copy.
Check DistCp counters
After the MapReduce job finishes, check the Distcp Counters section in the job output:
Distcp Counters
Bytes Destination Copied=11010048000
Bytes Source Read=11010048000
Files Copied=1001
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0Bytes Destination Copied: total bytes written to the destination.Bytes Source Read: total bytes read from the source.Files Copied: number of files successfully copied.
A matching Bytes Destination Copied and Bytes Source Read value confirms the copy completed without data loss.
Run a diff check
Add --diff to compare source and destination by filename and size. Files that are missing or failed to copy are recorded in a manifest file in the directory where you run the command.
hadoop jar jindo-distcp-<version>.jar \
--src /data/incoming/hourly_table \
--dest oss://yang-hhht/hourly_table \
--ossKey yourkey \
--ossSecret yoursecret \
--ossEndPoint oss-cn-hangzhou.aliyuncs.com \
--diffIf all files are present in the destination, the output includes:
INFO distcp.JindoDistCp: distcp has been done completelyOtherwise, a manifest file is generated listing the files that need to be copied.
Scenario 3: Resume a failed DistCp task
If a DistCp job fails partway through, use the manifest file to copy only the files that were not completed.
Run
--diffto check which files are missing and generate a manifest:hadoop jar jindo-distcp-<version>.jar \ --src /data/incoming/hourly_table \ --dest oss://yang-hhht/hourly_table \ --ossKey yourkey \ --ossSecret yoursecret \ --ossEndPoint oss-cn-hangzhou.aliyuncs.com \ --diffIf the output shows
INFO distcp.JindoDistCp: distcp has been done completely, all files are already present and no further action is needed. Otherwise, a manifest file is generated in the current directory.Copy only the files listed in the manifest using
--copyFromManifestand--previousManifest:hadoop jar jindo-distcp-<version>.jar \ --src /data/incoming/hourly_table \ --dest oss://yang-hhht/hourly_table \ --previousManifest=file:///opt/manifest-2020-04-17.gz \ --copyFromManifest \ --parallelism 20Replace
file:///opt/manifest-2020-04-17.gzwith the actual path to the manifest file generated in step 1.
Scenario 4: Copy newly generated files incrementally
To handle files that are added to the source directory between runs, use --outputManifest and --previousManifest to track which files have already been copied.
On the first run, generate a manifest of the copied files. Set
--requirePreviousManifest=falsebecause no previous manifest exists yet:--outputManifest: the filename for the generated manifest. The filename must end with.gz. The file is saved to the destination specified by--dest.--requirePreviousManifest: set tofalseto skip the check for a prior manifest.
hadoop jar jindo-distcp-<version>.jar \ --src /data/incoming/hourly_table \ --dest oss://yang-hhht/hourly_table \ --ossKey yourkey \ --ossSecret yoursecret \ --ossEndPoint oss-cn-hangzhou.aliyuncs.com \ --outputManifest=manifest-2020-04-17.gz \ --requirePreviousManifest=false \ --parallelism 20On subsequent runs, pass the previous manifest as
--previousManifestso that Jindo DistCp copies only files added since the last run:hadoop jar jindo-distcp-2.7.3.jar \ --src /data/incoming/hourly_table \ --dest oss://yang-hhht/hourly_table \ --ossKey yourkey \ --ossSecret yoursecret \ --ossEndPoint oss-cn-hangzhou.aliyuncs.com \ --outputManifest=manifest-2020-04-18.gz \ --previousManifest=oss://yang-hhht/hourly_table/manifest-2020-04-17.gz \ --parallelism 10Repeat step 2 for each subsequent run, updating
--outputManifestand--previousManifestto the latest manifest filename.
Scenario 5: Control YARN queue and bandwidth
Add --queue and --bandwidth to assign the job to a specific YARN queue and cap its per-mapper bandwidth. These parameters can be used together or independently.
--queue: the name of the YARN queue.--bandwidth: bandwidth limit per mapper, in MB.
hadoop jar jindo-distcp-<version>.jar \
--src /data/incoming/hourly_table \
--dest oss://yang-hhht/hourly_table \
--ossKey yourkey \
--ossSecret yoursecret \
--ossEndPoint oss-cn-hangzhou.aliyuncs.com \
--queue yarnqueue \
--bandwidth 6 \
--parallelism 10Scenario 6: Write to OSS IA or Archive storage
To target a different storage class, add the corresponding flag.
Write to OSS Archive storage:
hadoop jar jindo-distcp-<version>.jar \
--src /data/incoming/hourly_table \
--dest oss://yang-hhht/hourly_table \
--ossKey yourkey \
--ossSecret yoursecret \
--ossEndPoint oss-cn-hangzhou.aliyuncs.com \
--archive \
--parallelism 20Write to OSS Infrequent Access (IA) storage:
hadoop jar jindo-distcp-<version>.jar \
--src /data/incoming/hourly_table \
--dest oss://yang-hhht/hourly_table \
--ossKey yourkey \
--ossSecret yoursecret \
--ossEndPoint oss-cn-hangzhou.aliyuncs.com \
--ia \
--parallelism 20Scenario 7: Optimize transfer for mixed or uniform file sizes
Jindo DistCp provides two job allocation strategies to improve copy performance depending on your file size distribution. The two flags are mutually exclusive.
| Strategy | Flag | When to use |
|---|---|---|
| Dynamic plan | --enableDynamicPlan | Many small files mixed with a few large files |
| Balance plan | --enableBalancePlan | Files are similar in size |
--enableDynamicPlanand--enableBalancePlancannot be used together.
Use `--enableDynamicPlan` for a mixed workload:
When most files are small but a few are large, default job allocation may assign too many small files and too few large files to the same mapper. --enableDynamicPlan rebalances the allocation to improve overall throughput.
hadoop jar jindo-distcp-<version>.jar \
--src /data/incoming/hourly_table \
--dest oss://yang-hhht/hourly_table \
--ossKey yourkey \
--ossSecret yoursecret \
--ossEndPoint oss-cn-hangzhou.aliyuncs.com \
--enableDynamicPlan \
--parallelism 10The following figure shows the job allocation before and after optimization. 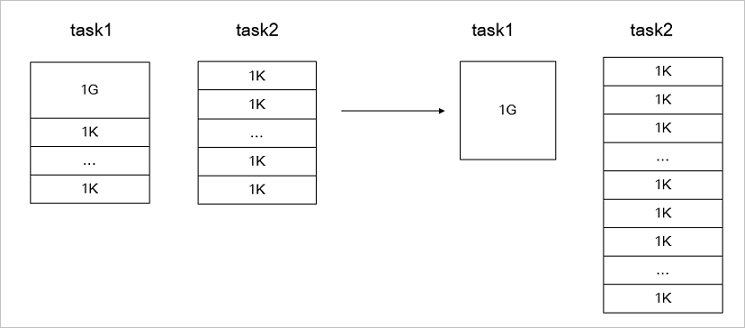
Use `--enableBalancePlan` for uniform file sizes:
When file sizes are similar, --enableBalancePlan distributes files more evenly across mappers.
hadoop jar jindo-distcp-<version>.jar \
--src /data/incoming/hourly_table \
--dest oss://yang-hhht/hourly_table \
--ossKey yourkey \
--ossSecret yoursecret \
--ossEndPoint oss-cn-hangzhou.aliyuncs.com \
--enableBalancePlan \
--parallelism 10The following figure shows the job allocation before and after optimization. 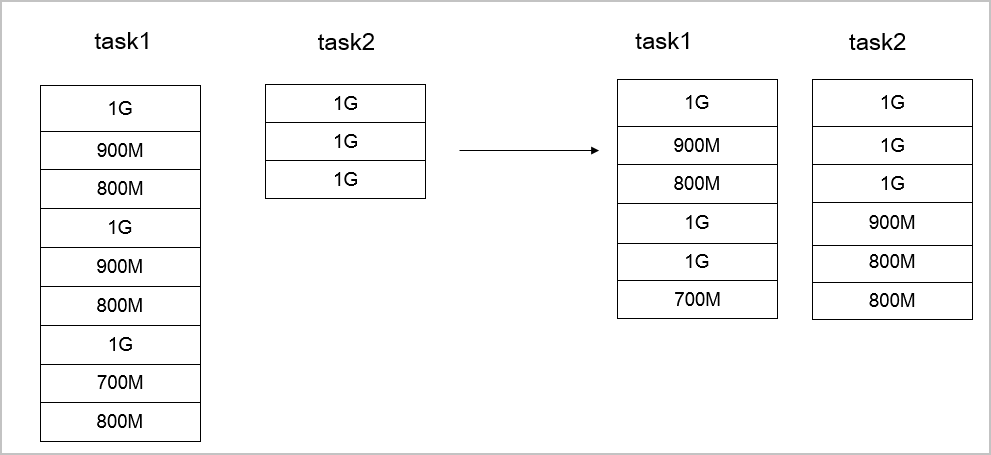
Scenario 8: Copy from Amazon S3 to OSS
Replace the OSS credential parameters with the Amazon S3 equivalents and set --src to the S3 path.
--s3Key: AccessKey ID for Amazon S3.--s3Secret: AccessKey secret for Amazon S3.--s3EndPoint: endpoint for Amazon S3.
hadoop jar jindo-distcp-<version>.jar \
--src s3a://yourbucket/ \
--dest oss://yang-hhht/hourly_table \
--s3Key yourkey \
--s3Secret yoursecret \
--s3EndPoint s3-us-west-1.amazonaws.com \
--parallelism 10Scenario 9: Compress copied files in LZO or GZ format
Use --outputCodec to compress files during the copy operation, reducing storage space in the destination.
hadoop jar jindo-distcp-<version>.jar \
--src /data/incoming/hourly_table \
--dest oss://yang-hhht/hourly_table \
--ossKey yourkey \
--ossSecret yoursecret \
--ossEndPoint oss-cn-hangzhou.aliyuncs.com \
--outputCodec=gz \
--parallelism 10Valid values for --outputCodec: gzip, gz, lzo, lzop, snappy, none, keep. Default: keep.
none: copies files without compression; if the source files are compressed, decompresses them.keep: copies files without changing their compression state.
To use the LZO codec in an open-source Hadoop cluster, install the native gplcompression library and the hadoop-lzo package.
Scenario 10: Filter files by pattern or sub-directory
Copy files matching a regular expression:
Add --srcPattern with a regular expression to copy only files whose paths match.
hadoop jar jindo-distcp-<version>.jar \
--src /data/incoming/hourly_table \
--dest oss://yang-hhht/hourly_table \
--ossKey yourkey \
--ossSecret yoursecret \
--ossEndPoint oss-cn-hangzhou.aliyuncs.com \
--srcPattern .*\.log \
--parallelism 10Copy files from specific sub-directories under the same parent:
Add --srcPrefixesFile with a path to a text file that lists the sub-directories to include (one path per line).
hadoop jar jindo-distcp-<version>.jar \
--src /data/incoming/hourly_table \
--dest oss://yang-hhht/hourly_table \
--ossKey yourkey \
--ossSecret yoursecret \
--ossEndPoint oss-cn-hangzhou.aliyuncs.com \
--srcPrefixesFile file:///opt/folders.txt \
--parallelism 20Example folders.txt:
hdfs://emr-header-1.cluster-50466:9000/data/incoming/hourly_table/2017-02-01
hdfs://emr-header-1.cluster-50466:9000/data/incoming/hourly_table/2017-02-02Scenario 11: Merge small files during copy
To reduce the total number of output files, add --targetSize and --groupBy to merge files that match a pattern into larger combined files.
--targetSize: maximum size of each merged output file, in MB.--groupBy: regular expression that defines which files to merge together.
hadoop jar jindo-distcp-<version>.jar \
--src /data/incoming/hourly_table \
--dest oss://yang-hhht/hourly_table \
--ossKey yourkey \
--ossSecret yoursecret \
--ossEndPoint oss-cn-hangzhou.aliyuncs.com \
--targetSize=10 \
--groupBy='.*/([a-z]+).*.txt' \
--parallelism 20Scenario 12: Delete source files after a successful copy
Add --deleteOnSuccess to remove source files once the copy completes successfully.
hadoop jar jindo-distcp-<version>.jar \
--src /data/incoming/hourly_table \
--dest oss://yang-hhht/hourly_table \
--ossKey yourkey \
--ossSecret yoursecret \
--ossEndPoint oss-cn-hangzhou.aliyuncs.com \
--deleteOnSuccess \
--parallelism 10Scenario 13: Store OSS or S3 credentials in configuration instead of CLI flags
To avoid specifying your AccessKey ID, AccessKey secret, and endpoint in every command, store them in core-site.xml. Jindo DistCp reads credentials from this file automatically.
For OSS:
<configuration>
<property>
<name>fs.jfs.cache.oss-accessKeyId</name>
<value>xxx</value>
</property>
<property>
<name>fs.jfs.cache.oss-accessKeySecret</name>
<value>xxx</value>
</property>
<property>
<name>fs.jfs.cache.oss-endpoint</name>
<value>oss-cn-xxx.aliyuncs.com</value>
</property>
</configuration>For Amazon S3:
<configuration>
<property>
<name>fs.s3a.access.key</name>
<value>xxx</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>xxx</value>
</property>
<property>
<name>fs.s3.endpoint</name>
<value>s3-us-west-1.amazonaws.com</value>
</property>
</configuration>