Data Transmission Service (DTS) supports three transmission modes — data migration, data synchronization, and change tracking — each suited to different use cases.
| Scenario | Transmission mode |
|---|---|
| Data migration with minimized downtime | Data migration |
| Geo-disaster recovery | Data synchronization |
| Active geo-redundancy | Data synchronization |
| Custom BI system built with ease | Data synchronization |
| Real-time data analysis | Change tracking |
| Lightweight cache update policies | Change tracking |
| Business decoupling | Change tracking |
| Scalable read capability | Data synchronization |
| Task scheduling for a data warehouse | Data migration |
Data migration with minimized downtime
Transmission mode: data migration
Traditional data migrations require stopping all writes to the source database to maintain consistency, which can take hours or even days depending on data volume and network conditions.
DTS keeps your application running throughout the migration. Downtime is limited to the final switchover — when you redirect your application to the destination database — which takes only minutes.
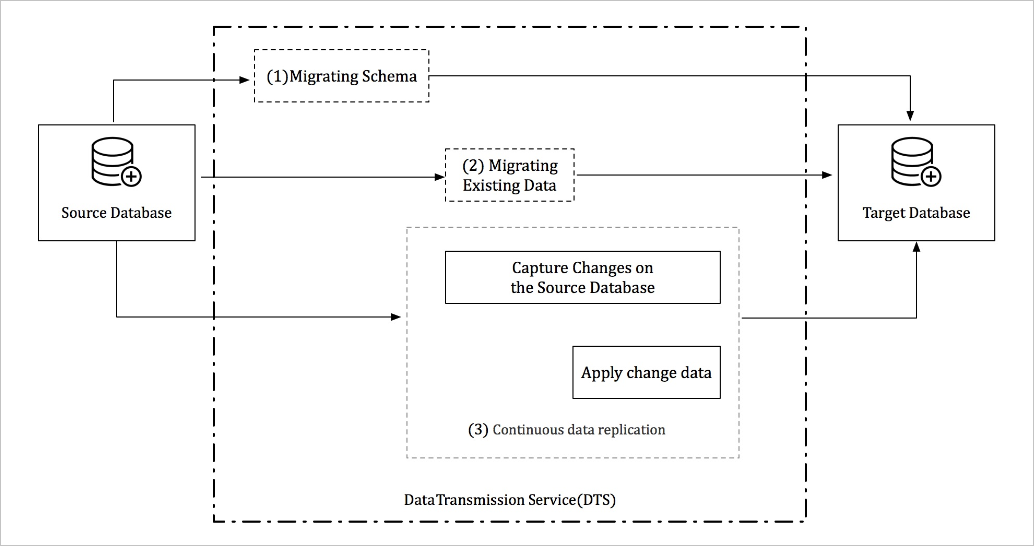
A complete migration runs in three phases:
Schema migration — replicates the database schema to the destination.
Full data migration — copies all existing data.
Incremental data migration — syncs ongoing changes from the source in real time while the full migration runs.
After migration completes, verify that the data and schema are fully compatible with your application. If verification passes, switch your application to the destination database without service interruption.
Geo-disaster recovery
Transmission mode: data synchronization
A single-region deployment is vulnerable to outages caused by power outages and network failures.
Set up a disaster recovery center in a second region. DTS continuously syncs data and replicas between the two regions. If the primary region fails, traffic shifts to the disaster recovery region to keep user requests processing.
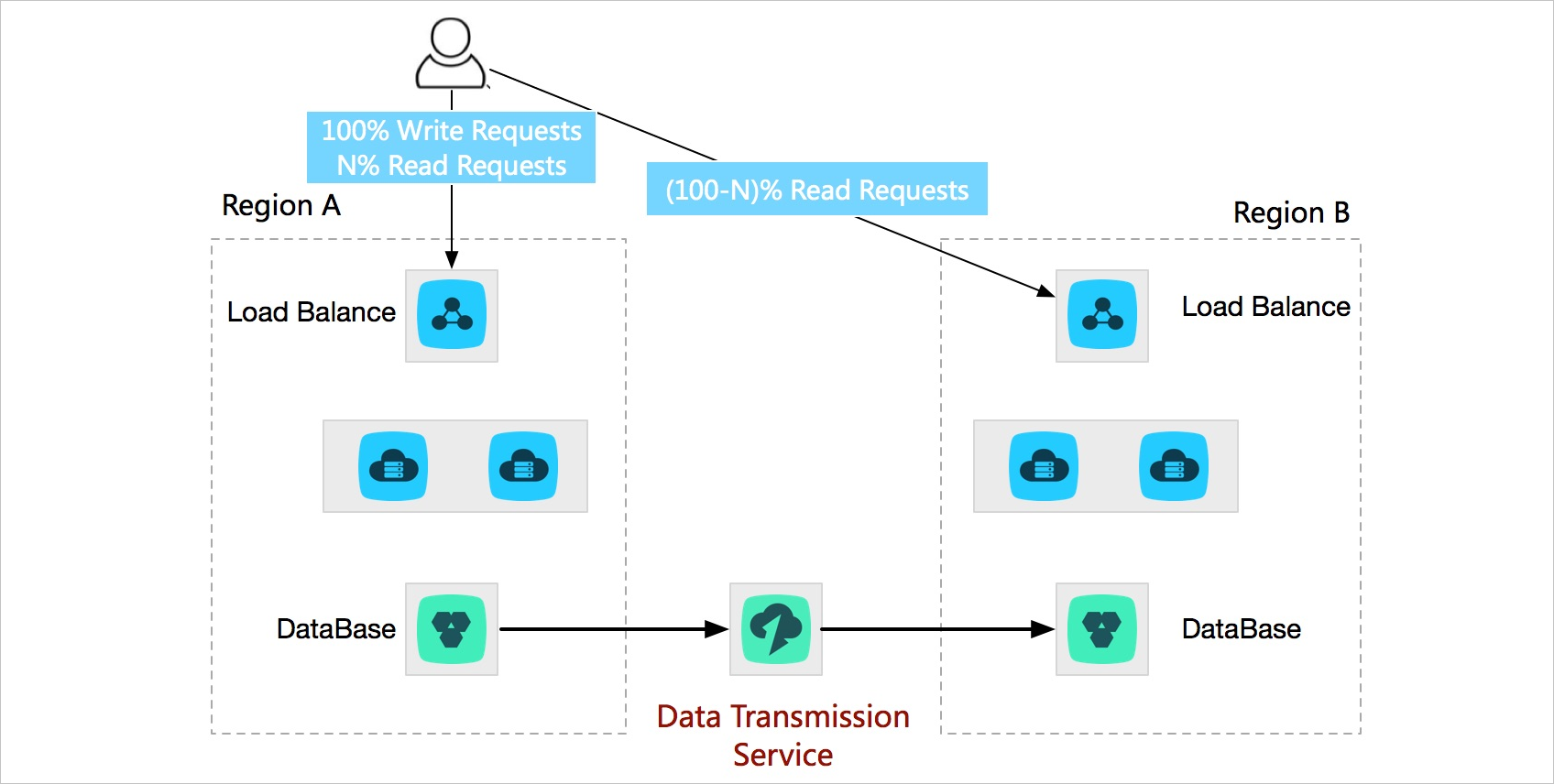
Active geo-redundancy
Single-region deployments create two problems as your business scales:
Users in distant regions experience high access latency.
Infrastructure capacity in one region — power, bandwidth — limits how far you can scale.
Deploy multiple business units in the same city or different cities and use DTS to run two-way real-time data synchronization between them. This keeps data globally consistent and lets you route each user to the nearest node, reducing latency. You can also distribute traffic across business units based on a specific dimension. If one business unit fails, others take over and service recovers within seconds.
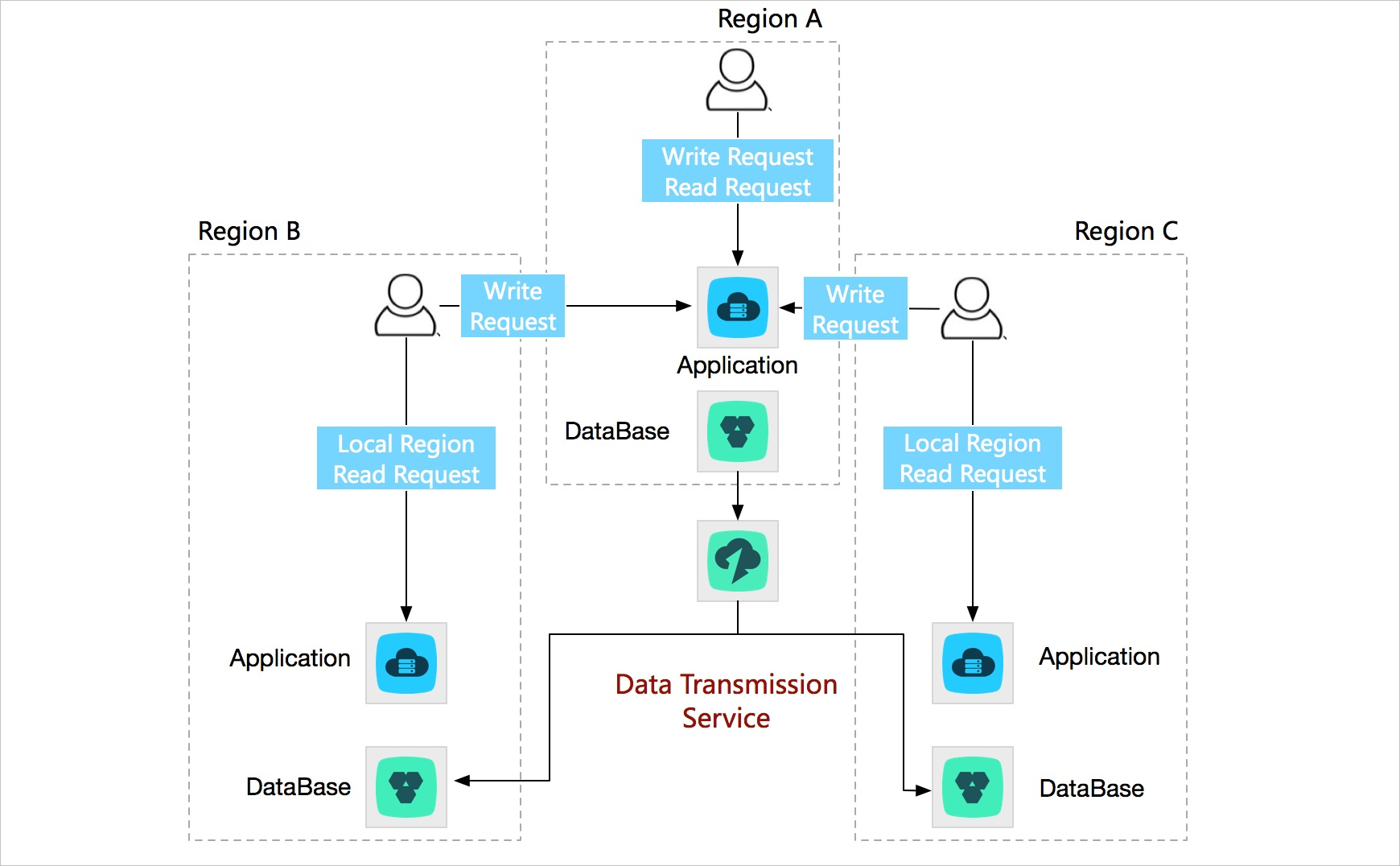
Custom BI system built with ease
Transmission mode: data synchronization
Self-managed business intelligence (BI) systems often struggle to meet real-time data requirements. Alibaba Cloud provides comprehensive BI systems. DTS syncs data from a self-managed database to an Alibaba Cloud storage system that supports BI analysis — such as MaxCompute — so you can quickly build a custom BI system that meets your business requirements on Alibaba Cloud.
Real-time data analysis
Transmission mode: change tracking
Real-time analysis lets you respond to market trends and customer behavior as they happen, not hours later.
DTS tracks incremental data changes from your database without affecting online workloads. Use DTS SDKs to subscribe to those changes and stream them into your analysis system for immediate processing.
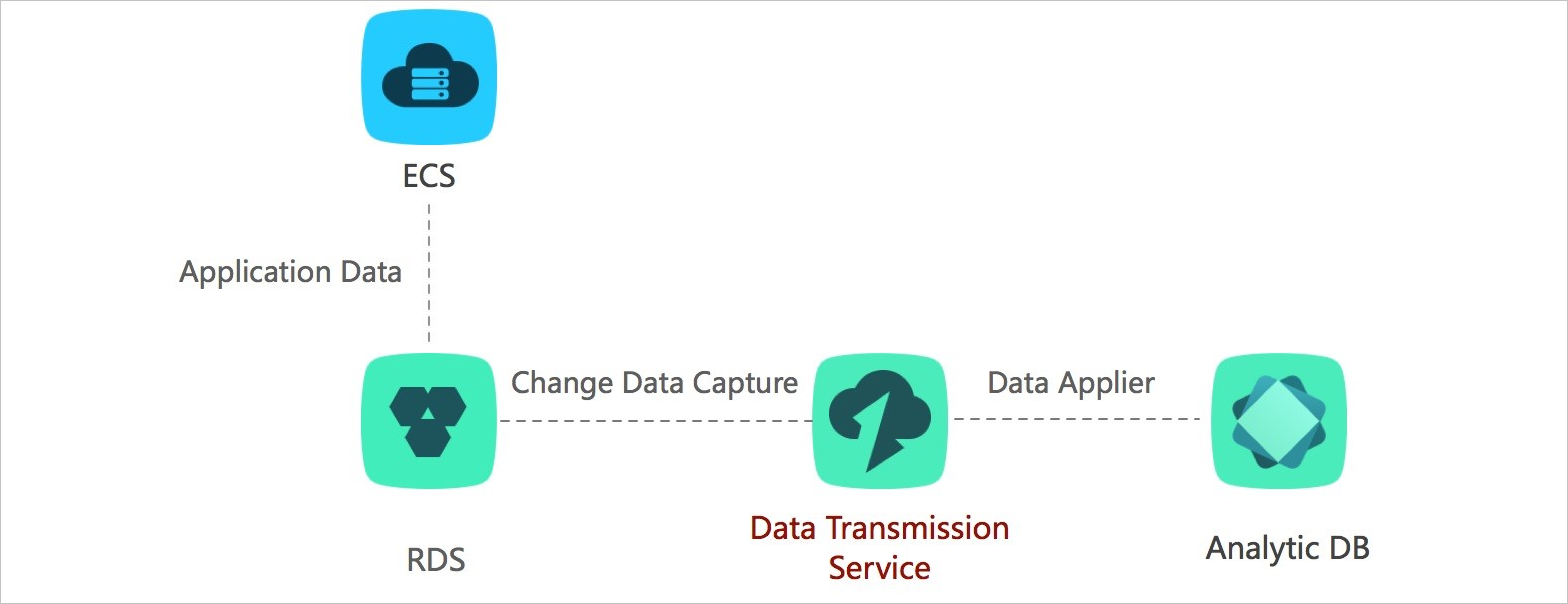
Lightweight cache update policies
Transmission mode: change tracking
Cache layers improve read performance by serving data from memory, but keeping the cache in sync with the database is complex. DTS tracks database changes asynchronously and updates cached data automatically, so you don't need custom synchronization logic.
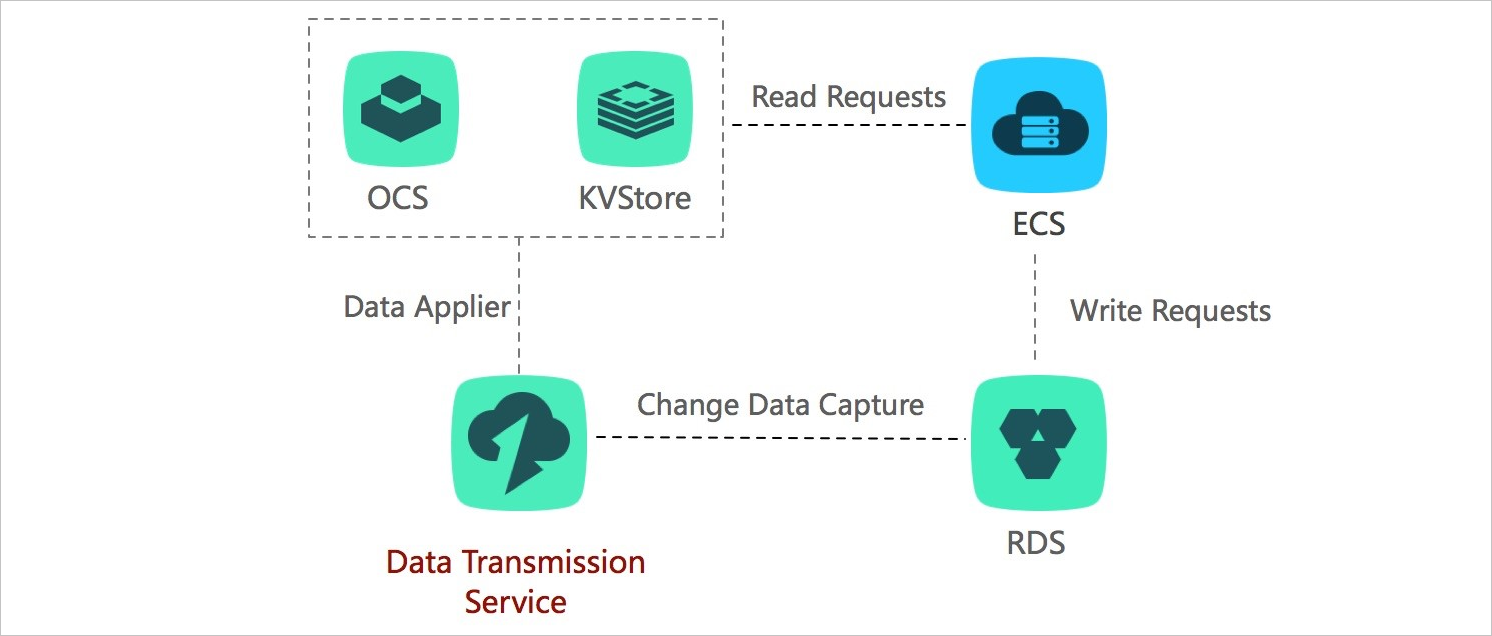
This approach has three advantages:
Low latency updates — updated data is returned immediately after a write, with no cache invalidation logic required.
Simple implementation — no doublewrite logic needed; start asynchronous threads to track changes and update the cache.
No performance impact — DTS reads incremental logs directly from the database, leaving your application and database unaffected.
Business decoupling
Transmission mode: change tracking
In e-commerce, a single order triggers multiple downstream processes — inventory updates, logistics, notifications, and more. If the ordering system waits for all of them to complete before returning a result, latency spikes and any downstream fault can bring down the entire flow.
Use DTS change tracking to decouple these processes. The ordering system returns a result as soon as the buyer places an order. DTS captures the resulting data changes in real time, and downstream systems — inventory, logistics, and others — subscribe to those changes through DTS SDKs and process them independently and asynchronously.
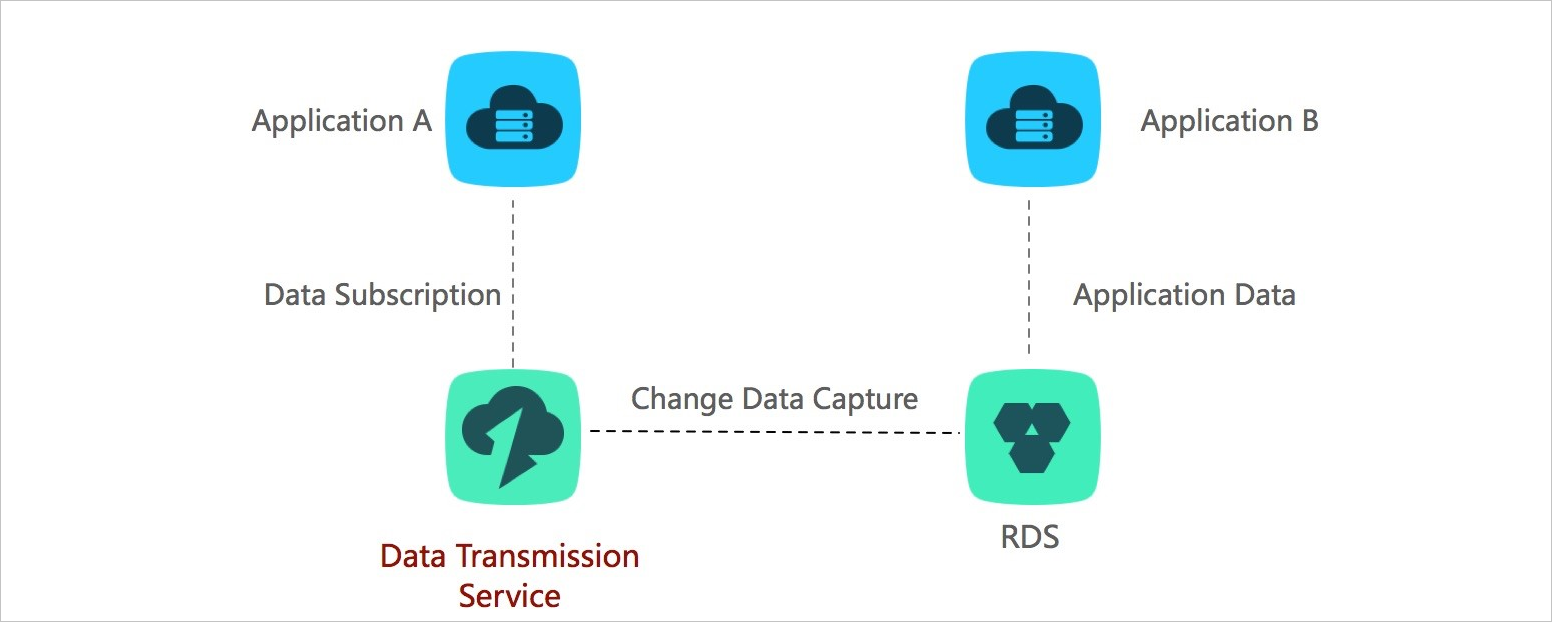
This pattern is in production at scale: the Taobao ordering system uses DTS change tracking to trigger tens of thousands of downstream business processes in real time. This scenario has been applied to a wide range of businesses in Alibaba Group.
Scalable read capability
Transmission mode: data synchronization
A single database instance may not handle a high volume of read requests. Use DTS to create read-only instances and distribute read traffic across them. This scales out read capacity without adding load to the primary database instance.
Task scheduling for a data warehouse
Transmission mode: data migration
Large applications generate significant transactional data every day. Use DTS data migration to move that data into your data warehouse on a schedule — for example, migrating the previous day's transactions during off-peak hours to minimize impact on production workloads.