As the big data market grows, traditional relational database management systems (RDBMSs) cannot meet the needs of online analytical processing (OLAP) scenarios. This topic shows you how to synchronize data from an Oracle database to DataHub, which is a big data processing platform of Alibaba Cloud, in real time. Then, you can use the DataHub plug-in for Oracle GoldenGate (OGG) to analyze your data.
OGG
1. Background information
As the big data market grows, traditional RDBMSs cannot meet the needs of OLAP scenarios. This topic shows you how to synchronize data from an Oracle database to DataHub, which is a big data processing platform of Alibaba Cloud, in real time. Then, you can use the DataHub plug-in for OGG to analyze your data.
OGG is a tool for log-based structured data replication across heterogeneous environments. It is used for data backup between primary and secondary Oracle databases. It is also used to synchronize data from Oracle databases to other databases such as IBM Db2 and MySQL databases. The following figure shows the logical architecture of OGG. OGG is deployed on the source and destination databases and involves Data Pump, Manager, Extract, Collector, and Replicat processes.
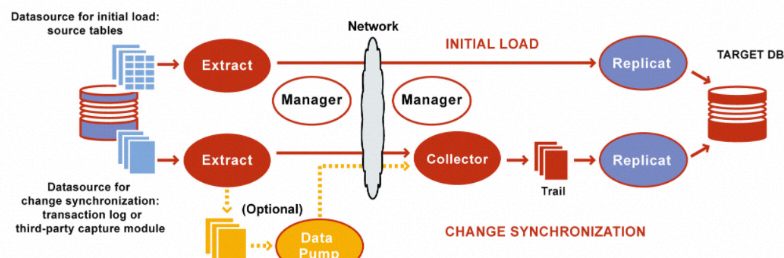
Manager process: the control process of OGG. Both the source and destination databases have one and only one Manager process. The Manager process is used to start, stop, and monitor other processes.
Extract process: a process that extracts data from the source database tables or transaction logs. You can configure the Extract process for initial data loads and incremental data synchronization. For initial data loads, the Extract process directly synchronizes data from the source tables to the target database. To keep source data synchronized to the destination database, the Extract process captures incremental data manipulation language (DML) and data definition language (DDL) operations after the initial data load. This topic describes incremental data synchronization.
Data Pump process: The Extract process writes all the captured operations to a trail file on the source database. The Data Pump process reads the trail file on the source database and sends the data operations over the network to the remote trail file on the destination database.
Collector process: a process on the destination database. It receives data from the source database and generates trail files.
Replicat process: a process that reads the trail file on the destination database, reconstructs the DML or DDL operations, and then applies them to the destination database.
The plug-in described in this topic serves as a Replicat process. OGG offers the Replicat feature that applies the updated data to DataHub by analyzing trail files. The data in DataHub can be processed in real time by using Realtime Compute and can be stored in MaxCompute for offline data processing. The current version of the DataHub plug-in for OGG is 2.0.5. You can download the package for the latest version at the end of this topic, or download the source code from GitHub.
2. Supported database versions
Database | Supported version | Plug-in version |
Oracle | 11g to 19c | 2.0.2 to 2.0.8 |
MySQL | Enterprise Edition and Community Edition | 2.0.3 to 2.0.8 |
3. Scenarios
The following example describes how to use the DataHub plug-in for OGG. A source Oracle table stores information about sales orders. The table contains three fields. The field names are oid, pid, and num, which indicate the order ID, commodity ID, and commodity quantity. The data types of these fields are all INT. Before you perform incremental data synchronization, synchronize existing data from the source table to MaxCompute by using DataX. To synchronize incremental data, perform the following steps: (1) Create a topic in DataHub and set the schema of the topic to (string record_id, string optype, string readtime, bigint oid_before, bigint oid_after, bigint pid_before, bigint pid_after, bigint num_before, bigint num_after). (2) Install and configure the DataHub plug-in for OGG and specify the following parameters to configure the field mappings:
<ctypeColumn>optype</ctypeColumn>
<ctimeColumn>readtime</ctimeColumn>
<cidColumn>record_id</cidColumn>
<columnMapping>
<column src="oid" dest="oid_after" destOld="oid_before" isShardColumn="true"/>
<column src="pid" dest="pid_after" destOld="pid_before"/>
<column src="num" dest="num_after" destOld="num_before"/>
</columnMapping>The optype parameter indicates the type of the data update. Valid values of the optype parameter are I, D, and U, which represent the insert, delete, and update operations. The readtime parameter indicates the time of the data update. (3) When the plug-in can properly run, data updates are synchronized from the source table to DataHub. For example, after you insert a record (1,2,1) into the source table, DataHub receives the following record:
+--------+------------+------------+------------+------------+------------+------------+------------+------------+
| record_id | optype | readtime | oid_before | oid_after | pid_before | pid_after | num_before | num_after |
+-------+------------+------------+------------+------------+------------+------------+------------+------------+
| 14810373343020000 | I | 2016-12-06 15:15:28.000141 | NULL | 1 | NULL | 2 | NULL | 1 |If you change a value in the record, for example, change the value of the num field to 20, DataHub receives the following updated record that shows both the original values and the updated values:
+-------+------------+------------+------------+------------+------------+------------+------------+------------+
| record_id | optype | readtime | oid_before | oid_after | pid_before | pid_after | num_before | num_after |
+--------+------------+------------+------------+------------+------------+------------+------------+------------+
| 14810373343080000 | U | 2016-12-06 15:15:58.000253 | 1 | 1 | 2 | 2 | 1 | 20 |(4) Start Oracle GoldenGate Software Command Interface (GGSCI) on the source database. In GGSCI, run the stats dhext command to query the operation statistics of each table. You can also run the command on the destination database to check whether the operation statistics are the same on the source database and the destination database.
Real-time analysis
You can use Realtime Compute to summarize in real time the data of the previous day generated by offline analysis. For example, you can obtain information about the total number of sales orders and the sales volume of each commodity in real time. For each piece of inbound data change, you can identify the changed values and update the statistics in real time.
Offline analysis
To facilitate offline analysis, you can store DataHub data in MaxCompute. Run the following command to create a table with the specified schema in MaxCompute:
create table orders_log(record_id string, optype string, readtime string, oid_before bigint, oid_after bigint, pid_before bigint, pid_after bigint, num_before bigint, num_after bigint);Create a DataConnector to synchronize data to MaxCompute. For more information, see Synchronize data to MaxCompute. The data that flows into DataHub is automatically synchronized to MaxCompute. We recommend that you store the data synchronized to MaxCompute in different partitions based on the time when the data is synchronized. For example, the incremental data of each day is stored in an independent partition. This way, after the data synchronization on a day is complete, data stored in the corresponding partition can be processed on the same day. You can merge the incremental data of that day with the latest full data. Then, the final full data is obtained. For ease of illustration, partitions are not considered in the following example. The incremental data generated on December 6, 2016 is used in this example. The full data of the previous day is stored in the orders_base table, and the incremental data synchronized from DataHub is stored in the orders_log table. If you merge the two tables, the final full data is written into the orders_result table. Execute the following SQL statements in MaxCompute to perform the preceding operations:
INSERT OVERWRITE TABLE orders_result
SELECT t.oid, t.pid, t.num
FROM
(
SELECT oid, pid, num, '0' x_record_id, 1 AS x_optype
FROM
orders_base
UNION ALL
SELECT decode(optype,'D',oid_before,oid_after) AS oid
, decode(optype,'D', pid_before,pid_after) AS pid
, num_after AS num
, record_id x_record_id
, decode(optype, 'D', 0, 1) AS x_optype
FROM
orders_log
) t
JOIN
(
SELECT
oid
, pid
, max(record_id) x_max_modified
FROM
(
SELECT
oid
, pid
, '0' record_id
FROM
orders_base UNION ALL SELECT
decode(optype,'D',oid_before,oid_after) AS oid
, decode(optype,'D', pid_before,pid_after) AS pid
, record_id
FROM
orders_log ) g
GROUP BY oid , pid
) s
ON
t.oid = s.oid AND t.pid = s.pid AND t.x_record_id = s.x_max_modified AND t.x_optype <> 0;4. Parameters
configure
Parameter | Default value | Required | Description |
batchSize | 1000 | No | The maximum number of records that can be written to DataHub at a time. |
batchTimeoutMs | 5000 | No | The maximum time to wait after which a new flush is triggered. Minimum value: 1000. Unit: milliseconds. |
dirtyDataContinue | false | No | Specifies whether to ignore dirty records. |
dirtyDataFile | datahub_ogg_plugin.dirty | No | The name of the file that stores dirty records. |
dirtyDataFileMaxSize | 500 | No | The maximum size of the file that stores dirty records. Unit: MB. |
retryTimes | -1 | No | The maximum number of retries allowed. -1 indicates unlimited retries. 0 indicates no retries. A value greater than 0 indicates the specified number of retries. |
retryInterval | 3000 | No | The interval between two consecutive retries. Unit: milliseconds. |
disableCheckPointFile | false | No | Specifies whether to prevent the creation of checkpoint files. |
checkPointFileName | datahub_ogg_plugin.chk | No | The checkpoint file name of the Adapter process. |
storageCtimeColumnAsTimestamp(Deprecated) | false | No | This parameter is deprecated. Time values are converted to the corresponding field type in DataHub. If the original time value is of the TIMESTAMP type, the value is converted to a timestamp in microseconds. If the original time value is of the STRING type, the value is converted to a string in the format of yyyy-MM-dd HH:mm:ss.SSSSSS. |
charset | UTF-8 | No | The database character set in Oracle. In most cases, you do not need to set this parameter unless garbled characters occur. |
commitFlush | true | No | Specifies whether to write uncommitted transactions to storage. If you set this parameter to true, data loss can be prevented, but the overall execution performance is affected. Set this parameter to true unless you encounter performance bottlenecks. |
reportMetric | false | No | Specifies whether to report metrics. |
reportMetricIntervalMs | 5 60 1000 | No | The intervals at which metrics are reported. The time is recounted after each reporting. Unit: milliseconds. |
buildCorePollSize | Number of configured tables | No | The minimum number of threads in the thread pool for parsing data. |
buildMaximumPoolSize | Twice the value of the buildCorePollSize parameter | No | The maximum number of threads in the thread pool for parsing data. |
writeCorePollSize | Number of configured tables | No | The minimum number of threads in the thread pool for writing data to DataHub. |
writeMaximumPoolSize | Number of configured tables | No | The maximum number of threads in the thread pool for writing data to DataHub. |
defaultOracleConfigure
Parameter | Default value | Required | Description |
sid | - | Yes | The system identifier (SID) of the Oracle database. |
schema | - | Yes | The schema of the Oracle database. |
dateFormat(Deprecated) | yyyy-MM-dd HH:mm:ss | No | The format to which timestamps are converted. |
defaultDatahubConfigure
Parameter | Default value | Required | Description |
endPoint | - | Yes | The endpoint of DataHub. |
project | - | Yes | The name of the DataHub project. |
accessId | - | Yes | The AccessKey ID used to access DataHub. |
accessKey | - | Yes | The AccessKey secret used to access DataHub. |
compressType | - | No | The data compression format. Valid values: DEFLATE and LZ4. By default, the data is not compressed. |
enablePb | false | No | Specifies whether to enable Protocol Buffers (Protobuf) for data transfer. |
ctypeColumn | - | No | The field in DataHub that indicates the data update type. The configuration can be overwritten by the ctypeColumn parameter in the mappings. The value must be of the STRING type. |
ctimeColumn | - | No | The field in DataHub that indicates the time when the data insert, update, or delete operation is performed. The configuration can be overwritten by the ctimeColumn parameter in the mappings. The value must be of the STRING or TIMESTAMP type. |
cidColumn | - | No | The field in DataHub that indicates the sequence number of the updated record. The configuration can be overwritten by the cidColumn parameter in the mappings. The sequence number increases as more records are updated. Multiple sequence numbers may not be consecutive. The value must be of the STRING type. |
constColumnMap | - | No | The added field that contains a single constant value specified for each record. The values specified for different records in this field are separated with commas (,) in the format similar to c1=xxx,c2=xxx. The configuration can be overwritten by the constColumnMap parameter in the mappings. The field indicates the data update time on the source database. The following table describes the parameters that can be used in this field. |
constColumnMap
Value | Description |
%t | The UNIX timestamp that indicates the number of milliseconds that have elapsed since 00:00:00 Thursday, January 1, 1970. |
%a | The abbreviation for the weekday name. Example: Mon. |
%A | The full weekday name. Example: Monday. |
%b | The abbreviation of the month name. Example: Jan. |
%B | The full month name. Example: January. |
%c | The date and time. Example: Thu Mar 3 23:05:25 2005. |
%d | The day of the month. Example: 01. |
%D | The date. Example: 05/09/20. |
%H | The hour in the 24-hour clock. Valid values: 00 to 23. |
%I | The hour in the 12-hour clock. Valid values: 01 to 12. |
%j | The day of the year. Valid values: 001 to 366. |
%k | The hour in the 24-hour clock. Valid values: 0 to 23. |
%m | The month. Valid values: 01 to 12. |
%M | The minute. Valid values: 00 to 59. |
%p | The period of the current day. Valid values: am and pm. |
%s | The UNIX timestamp that indicates the number of seconds that have elapsed since 00:00:00 Thursday, January 1, 1970. |
%S | The second. Valid values: 00 to 59. |
%y | The last two digits of the year: Valid values: 00 to 99. |
%Y | The year. Example: 2010. |
%z | The time zone. Example: UTC+8. |
To use the date when the data is synchronized to MaxCompute as the value of the partition field, you can add the <constColumnMap>ds=%Y%m%d</constColumnMap> parameter configuration. The parameter value, such as 20200509, is written to the ds field in DataHub.
mapping
Parameter | Default value | Required | Description |
oracleSchema | - | No | If you do not set this parameter, the schema specified by the defaultOracleConfigure parameter is used. |
oracleTable | - | Yes | The name of the Oracle table. |
datahubProject | - | No | If you do not set this parameter, the project specified by the defaultDatahubConfigure parameter is used. |
datahubAccessId(Deprecated) | - | No | This parameter is deprecated. By default, the AccessKey ID specified by the defaultDatahubConfigure parameter is used. |
datahubAccessKey(Deprecated) | - | No | This parameter is deprecated. By default, the AccessKey secret specified by the defaultDatahubConfigure parameter is used. |
datahubTopic | - | Yes | The name of the DataHub topic. |
shardId(Deprecated) | - | No | The IDs of the shards. If you set this parameter, the shard IDs are not automatically updated. Example: 0,1,2. |
rowIdColumn | - | No | The field in DataHub that indicates the IDs of the records. The value must be of the STRING type. This parameter is used if the source Oracle table does not have a primary key. |
ctypeColumn | - | No | This parameter is the same as the ctypeColumn parameter in defaultDatahubConfigure. |
ctimeColumn | - | No | This parameter is the same as the ctimeColumn parameter in defaultDatahubConfigure. |
cidColumn | - | No | This parameter is the same as the cidColumn parameter in defaultDatahubConfigure. |
constColumnMap | - | No | This parameter is the same as the constColumnMap parameter in defaultDatahubConfigure. |
Parameters in columnMapping
Parameter | Default value | Required | Description |
src | - | Yes | The field name in the Oracle table. |
dest | - | Yes | The field name in the DataHub topic. |
destOld | - | No | The name of the field that records the data before the data is transmitted to the DataHub topic. |
isShardColumn | false | No | Specifies whether to generate shard IDs based on the hash key values. |
isKeyColumn | false | No | Specifies whether to write the value of this parameter before the change to the DataHub field that corresponds to the dest parameter if the value is NULL after the change, but is not NULL before the change. |
isDateFormat | true | No | Specifies whether to convert time values to the format specified by the dateFormat parameter. This parameter takes effect only when the corresponding DataHub field is of the TIMESTAMP type. If the data type of the field is DATE or TIMESTAMP in Oracle, you do not need to set this parameter. If you set this parameter to false, the source data must be of the LONG type. |
dateFormat | yyyy-MM-dd HH:mm:ss[.fffffffff] | No | The date format to which time values are converted. In most cases, you do not need to set this parameter unless the values do not conform to the default format. |
isDefaultCharset | true | No | Specifies whether to use the default character set in Oracle. In most cases, you do not need to set this parameter unless garbled characters occur. You must first configure the character set, and then set this parameter to false for the field that contains garbled characters. |
5. FAQ
Files for troubleshooting:
datahub-ogg-plugin.log: the logs of the DataHub plug-in. Most of the issues can be resolved by checking the errors reported in such logs. Logs of this type are stored in the log subdirectory of the plug-in directory.
ggserr.log: the monitoring logs. In most cases, you can view user operations and the startup status in the monitoring logs in the ogg/adapter directory. Reported errors such as the invalid configuration of the Extract process or the missing of specific dynamic-link libraries (DDLs) are recorded in the monitoring logs.
dirrpt: the process report files. Run the VIEW REPORT command to view the error information in a process report file. If data is transmitted to the destination database without error reported in both the ggserr.log and the plug-in log files, you may find the error information recorded in this file.
dirchk: the log file that stores the checkpoint information of a process in OGG.
datahub_ogg_plugin.chk: the log file that stores the checkpoint information of the DataHub plug-in.
Q: What can I do if I cannot write data to DataHub?
A: Check the whole process.
Check whether the dirdat file stores the data read from the source database. If not, the cause lies in the Extract process on the source database.
Check whether the dirdat file stores replicated data on the destination database. If not, the cause lies in the Data Pump process on the source database.
View the log files of the plug-in to check whether the data is skipped by the checkpoints, or an error occurs with the plug-in. These are the most common causes.
If the data is transmitted to the destination database and no errors are recorded in the log files of the plug-in, check the log files in the dirrpt subdirectory. The data may be skipped by the checkpoints created on the destination database.
Check whether the Oracle schema is correctly configured. Data may be skipped because the Oracle schema does not match the schema of the source database.
Q: What can I do if I cannot query the record ID but other fields are returned?
A: In most cases, this issue may be caused by configuration errors. You must check the configurations carefully.
Check the version of the plug-in. Only version 2.0.3 or later allows you to query the record ID.
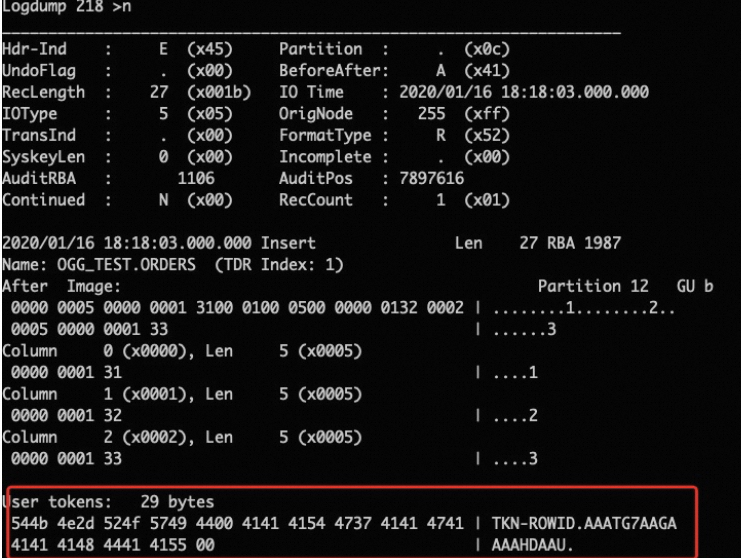
Check whether the token of the Extract process on the source database is correctly configured in the following syntax:
TABLE OGG_TEST.*,tokens (TKN-ROWID=@GETENV('RECORD','rowid'));. For example, if you mistakenly enter TKN-ROWID as TKN_ROWID, the query request fails.Check whether
<rowIdColumn></rowIdColumn>is configured in the configure.xml file on the destination database.Run the Logdump command to check whether the record ID can be obtained, as shown in the following figure.
Q: What can I do if an error occurs in the token clause for TKN-ROWID?
Error messages:
2020-01-17 16:17:17 INFO OGG-06509 Oracle GoldenGate Capture for Oracle, dhext.prm: Using the following key columns for source table OGG_TEST.ORDERS: OID.
2020-01-17 16:17:17 INFO OGG-01298 Oracle GoldenGate Capture for Oracle, dhext.prm: Column function diagnostic message: could not find column "RECORD".
2020-01-17 16:17:17 ERROR OGG-00369 Oracle GoldenGate Capture for Oracle, dhext.prm: Error in token clause for TKN-ROWID.
2020-01-17 16:17:17 ERROR OGG-01668 Oracle GoldenGate Capture for Oracle, dhext.prm: PROCESS ABENDING.A: If the row ID still cannot be retrieved after you use the token syntax TABLE OGG_TEST.*,tokens (TKN-ROWID=@GETENV('RECORD','rowid'));, use the following methods to troubleshoot the issue:
Check the version of the plug-in. Only version 2.0.3 or later allows you to query row IDs.
Check your token syntax with the official sample provided by OGG.
If the syntax is consistent, change the single quotation marks (') to double quotation marks (") in the
@GETENV('RECORD','rowid'))part.Restart the Manager process.
Q: What can I do if the error "dsOperation.getPosition():xxxxxxx old sendPosition is xxxxx, Skip this Operation, it maybe duplicated." is returned?
A: In most cases, this issue is caused because processes restart on the source database. This error indicates that checkpoints of the DataHub plug-in are duplicate. The system often mistakenly identifies duplication. In addition, checkpoints of OGG are enough for normal running of the application. You can set disableCheckPointFile to true to prevent the creation of checkpoint files in the DataHub plug-in. In later versions, we will no longer use checkpoints of the DataHub plug-in.
Q: Why do I receive the log error "Unable to create operation: com.goldengate.atg.datasource.ConcurrentTransactionException: Multiple "Begin-Transaction" operations received for the same source transaction. Current transaction begin position: xxx(xxx); current trail position: xxx"?
A: Transactions on the source database conflict. Check whether an issue exists on the source Oracle database.
Q: What can I do if an 8-hour delay occurs after the data is transmitted to DataHub?
A: Set the goldengate.userexit.timestamp parameter to UTC+8 in the javaue.properties file and then restart DataHub Writer.
Q: What can I do if specific fields are left empty after the DataHub plug-in parses the data?
A: Run the SET DEBUG command to enable the debugging mode in OGG. Check whether the reported full data matches the data on the source database.
If the reported data matches the source data, the issue may be caused by incorrect configurations of the columnMapping parameter.
If the reported data does not match the source data, check the result data from the Extract process. For more information, see Using the Logdump Utility. You can query a specific redo block address (RBA) in the log file.
Q: What can I do if a parsing error occurs with the trail files on the source database when OGG 12.3 is used?
A: We recommend that you install OGG 12.2, or change RMTTRAIL ./dirdat/st to RMTTRAIL ./dirdat/st format RELEASE 12.2in the configurations of the Extract process on the destination database.
Q: What can I do if the error "java.lang.NumberFormatException: for input string : xxxx" is returned?
A: Check the mappings between Oracle and DataHub. For more information, see Mappings between data types in Oracle and DataHub. For example, the mapping is invalid if you convert the values of the destOld parameter of the STRING type in Oracle to values of the BIGINT type in DataHub.
Q: What can I do if the error "String index out of range: 10" is returned?
Error messages:
2020-01-14 10:03:24 [main] ERROR OperationHandler - dirty data : INSERT on WF_YN_07.CJ_GLQX202001 [B] [columns: 27] [pos: 00000007260404799638 (seqno=726, rba=404799638)] [time: 2020-01-14 08:49:43.883741]
java.lang.StringIndexOutOfBoundsException: String index out of range: 10
at java.lang.AbstractStringBuilder.setCharAt(AbstractStringBuilder.java:407)
at java.lang.StringBuilder.setCharAt(StringBuilder.java:76)
at com.aliyun.odps.ogg.handler.datahub.RecordBuilder.convertStrToMicroseconds(RecordBuilder.java:272)
at com.aliyun.odps.ogg.handler.datahub.RecordBuilder.setTupleData(RecordBuilder.java:242)
at com.aliyun.odps.ogg.handler.datahub.RecordBuilder.buildTupleRecord(RecordBuilder.java:172)
at com.aliyun.odps.ogg.handler.datahub.RecordBuilder.buildRecord(RecordBuilder.java:82)
at com.aliyun.odps.ogg.handler.datahub.operations.OperationHandler.processOperation(OperationHandler.java:50)
at com.aliyun.odps.ogg.handler.datahub.operations.InsertOperationHandler.process(InsertOperationHandler.java:31)
at com.aliyun.odps.ogg.handler.datahub.DatahubHandler.operationAdded(DatahubHandler.java:108)
at oracle.goldengate.datasource.DsEventManager$3.send(DsEventManager.java:439)
at oracle.goldengate.datasource.DsEventManager$EventDispatcher.distributeEvent(DsEventManager.java:231)
at oracle.goldengate.datasource.DsEventManager.fireOperationAdded(DsEventManager.java:447)
at oracle.goldengate.datasource.AbstractDataSource.fireOperationAdded(AbstractDataSource.java:464)
at oracle.goldengate.datasource.UserExitDataSource.addOperationToTransactionAndFireEvent(UserExitDataSource.java:1337)
at oracle.goldengate.datasource.UserExitDataSource.createOperation(UserExitDataSource.java:1305)
at oracle.goldengate.datasource.UserExitDataSource.createOperation(UserExitDataSource.java:1046)A: By default, the time values mapped from Oracle are of the DATE or TIMESTAMP type. A value is converted as a date and time string, such as 2020-01-10:10:00:00 in DataHub. Therefore, if you pass a time value not in the default format, the error occurs. To resolve this issue, you can set the isDateFormat parameter to false in columnMapping.
Q: What can I do if I cannot retrieve the values before the update?
A: Check whether the GETUPDATEBEFORES parameter is set on the source database.
Q: Why is the updated value left empty when the source table has a primary key?
A: The following scenarios describe the different operations to retrieve the update operations when the source table has or does not have a primary key:
For tables that do not have a primary key, if the value of a field is updated from A to B, the update operation is
"B" [before="A"]. If a field is not updated, and the value is C, the update operation is"C" [before="C"].For tables that have a primary key, if the value of a field is updated from A to B, the updated operation is
"B" [before="A"]. If a field is not updated, and the value is C, the update operation is"" [before="C"].Solution 1: For example, a table has three fields A, B, and C. Field A is set as the primary key. If Field B is not updated, the updated value of Field B is left empty. If you want to set Field B to the same value as the original value, specify
TABLE OGG_TEST.*,keycols(a,b);in the Extract process on the source database.Solution 2: Specify the isKeyColumn parameter in columnMap. Example:
<column src="b" dest="b" destOld="b_old" isKeyColumn="true"/>.
Q: What can I do if the error "Unsupported major.minor version 52.0" is returned?
Error messages:
2019-12-23 18:03:58 [main] ERROR UserExitMain - java.lang.UnsupportedClassVersionError: com/aliyun/datahub/client/model/RecordSchema : Unsupported major.minor version 52.0
java.lang.UnsupportedClassVersionError: com/aliyun/datahub/client/model/RecordSchema : Unsupported major.minor version 52.0
at oracle.goldengate.datasource.DataSourceLauncher.<init>(DataSourceLauncher.java:161)
at oracle.goldengate.datasource.UserExitMain.main(UserExitMain.java:108)
Caused by: org.springframework.beans.factory.BeanDefinitionStoreException: Factory method [public final oracle.goldengate.datasource.GGDataSource oracle.goldengate.datasource.factory.DataSourceFactory.getDataSource()] threw exception; nested exception is java.lang.UnsupportedClassVersionError: com/aliyun/datahub/client/model/RecordSchema : Unsupported major.minor version 52.0
at org.springframework.beans.factory.support.SimpleInstantiationStrategy.instantiate(SimpleInstantiationStrategy.java:169)
at org.springframework.beans.factory.support.ConstructorResolver.instantiateUsingFactoryMethod(ConstructorResolver.java:570)
... 11 more
Caused by: java.lang.UnsupportedClassVersionError: com/aliyun/datahub/client/model/RecordSchema : Unsupported major.minor version 52.0A: The error occurs because the Java Development Kit (JDK) version that you installed does not meet the environment requirement. We recommend that you download and install the JDK version 1.8, or you can download the source code from GitHub and compile a JAR package.
Q: What can I do if the "Error opening module ./libggjava_ue.so - libjsig.so:cannot open shared object file:no such file or directory" error is returned?
A: Check the OGG version, the file to query, and the environment variables. Try to restart the Manager process or your machine. The issue may be resolved by restarting the machine, but this solution is not recommended.
Q: What can I do if the error "OGG-00425 No DB login established to retrieve a definition for table xxx.xxx" is returned?
A: Regenerate the source-definitions file and replicate the file to the destination database.
Q: Why is the error "defaultDatahubConfigure is null" returned?
Error messages:
2020-01-17 17:28:32 [main] ERROR DatahubHandler - Init error
java.lang.RuntimeException: defaultDatahubConfigure is null
at com.aliyun.odps.ogg.handler.datahub.ConfigureReader.reader(ConfigureReader.java:117)A: A spelling mistake was corrected in the plug-in V2.0.3. If you stick to the plug-in V2.0.2, change the parameter name from defalutDatahubConfigure to defaultDatahubConfigure in the configuration file.
Q: What can I do if the error "OGG-06551 Oracle GoldenGate Collector: Could not translate host name localhost into an Internet address." is returned on the destination database?
A: Reset the IP address that is mapped for the host name localhost in the /etc/hosts file on the destination database.
Q: What can I do if the JVM cannot load a shared library (.so)?
A: Restart the Manager process after you add the path of the shared library to the LD_LIBRARY_PATH environment variable. Example: export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:$JAVA_HOME/lib/amd64:$JAVA_HOME/lib/amd64/server.
Q: What can I do in the following scenario: The error "2015-06-11 14:01:10 ERROR OGG-01161 Bad column index (5) specified for table OGG_TEST.T_PERSON, max columns = 5" is returned. The Adapter for writing flat files and the JMS Adapter fail to work when I add a field in the table. No issues are found in OGG on the source database.
A: The schema of the table is not consistent on the source and the destination databases. You must create a DEFGEN configuration file and copy the file to the dirdef directory on the destination database. Then, restart the Replicat process.
Q: Why is the "Error (4) retrieving column value" error reported in the OGG report file?
A: In most cases, this is because OGG fails to parse trail files. You can view the debugging logs to identify the RBA that reported the error, and adjust the checkpoint to skip the RBA to resolve the issue.
6. Release notes
2.0.2
2.0.3
Record IDs can be retrieved from the source Oracle tables.
Data types such as DECIMAL and TIMESTAMP in DataHub are supported.
A spelling mistake is corrected in the plug-in V2.0.3. If you stick to the plug-in V2.0.2, change the parameter name from defalutDatahubConfigure to defaultDatahubConfigure in the configuration file.
Data compression and data transfer by using Protobuf are supported.
2.0.4
Database character sets can be configured. This feature can prevent garbled characters for databases whose data is not encoded in UTF-8.
2.0.5
The performance is optimized with transactions per second (TPS) increased by 70% at most.
Metrics can be reported for logs.
The following issue is fixed: The time when the constColumnMap parameter is retrieved is different from the actual time.
2.0.6
The following issue is fixed: Excessive thread data exists.
The following issue is fixed: The updated value is empty and cannot be hashed.
Data types including TINYINT, SMALLINT, INTEGER, and FLOAT in DataHub are supported.
2.0.7
The plug-in is adapted to OGG for Big Data 12.3.2.1, and no longer supports OGG Application Adapters.
2.0.8
The plug-in is adapted to OGG for Big Data 19.1.0.0, and no longer supports OGG Application Adapters.