This topic describes the syntax and parameters of resource functions. This topic also provides examples on how to use the functions.
Functions
When you call the following resource functions, you must configure the Advanced preview mode to pull the data that you require. For more information about how to configure the Advanced preview mode, see Advanced preview.
Function | Description |
Pulls the values of advanced parameters from the current data transformation job. This function can be used together with other functions. For more information, see Use Simple Log Service to connect to an ApsaraDB RDS for MySQL instance for data enrichment. | |
Pulls data from a specified table in a database that is created on an ApsaraDB RDS for MySQL instance or obtains the execution result of an SQL statement. The data and result can be updated at regular intervals. This function can be used together with other functions. For more information, see Use Simple Log Service to connect to an ApsaraDB RDS for MySQL instance for data enrichment. | |
Pulls data from another Logstore when you transform data in a Logstore. You can pull data in a continuous manner. This function can be used together with other functions. For more information, see Pull data from one logstore to enrich log data in another logstore. | |
Pulls data from an object in a specified Object Storage Service (OSS) bucket. The data can be updated at regular intervals. This function can be used together with other functions. For more information, see Pull a CSV file from OSS to enrich data. |
res_local
The res_local function pulls the values of advanced parameters from the current data transformation job.
Syntax
res_local(param, default=None, type="auto")Parameters
Parameter
Type
Required
Description
param
String
Yes
The key that is specified in Advanced Parameter Settings for the current data transformation job.
default
String
No
The value that is returned if the key specified for the param parameter does not exist. Default value: None.
type
String
No
The format of the output data. Valid values:
auto: Raw data is converted to a JSON string. If the conversion fails, the raw data is returned. This is the default value.
JSON: Raw data is converted to a JSON string. If the conversion fails, the value of the default parameter is returned.
raw: Raw data is returned.
Response
A JSON string or raw data is returned based on the parameter settings.
Successful conversions
Raw data
Return value
Data type of the return value
1
1
Integer
1.2
1.2
Float
true
True
Boolean
false
False
Boolean
"123"
123
String
null
None
None
["v1", "v2", "v3"]
["v1", "v2", "v3"]
List
["v1", 3, 4.0]
["v1", 3, 4.0]
List
{"v1": 100, "v2": "good"}
{"v1": 100, "v2": "good"}
List
{"v1": {"v11": 100, "v2": 200}, "v3": "good"}
{"v1": {"v11": 100, "v2": 200}, "v3": "good"}
List
Failed conversions
The following table provides some examples of failed conversions. The following raw data fails to be converted to JSON strings, and the raw data is returned as strings.
Raw data
Return value
Description
(1,2,3)
"(1,2,3)"
Tuples are not supported. Lists must be used.
True
"True"
A value of the Boolean data type can only be true or false. The values must be in lowercase.
{1: 2, 3: 4}
"{1: 2, 3: 4}"
A dictionary key can only be a string.
Examples
Obtain the key specified in Advanced Parameter Settings and assign the value of the obtained key to the local parameter.
In Advanced Parameter Settings, the key is endpoint, and the value is hangzhou.
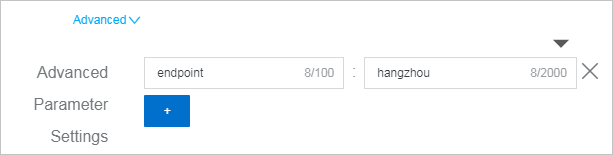
Raw log
content: 1Transformation rule
e_set("local", res_local('endpoint'))Result
content: 1 local: hangzhou
References
This function can be used together with other functions. For more information, see Use Simple Log Service to connect to an ApsaraDB RDS for MySQL instance for data enrichment.
res_rds_mysql
The res_rds_mysql function pulls data from a specified table in a database that is created on an ApsaraDB RDS for MySQL instance or obtains the execution result of an SQL statement. Log Service allows you to pull data by using the following methods:
If you use the res_rds_mysql function to pull data from a database that is created on an ApsaraDB RDS for MySQL instance, you must create a whitelist on the instance and add
0.0.0.0to the whitelist. This allows access to the database from all IP addresses. However, this may create risks for the database. If you want to add the IP address of Log Service to the whitelist, you must submit aticket.Log Service can access a database that is created on an ApsaraDB RDS for MySQL instance by using either a public or internal endpoint of the instance. If an internal endpoint is used, you must configure the advanced parameters. For more information, see Use Simple Log Service to connect to an ApsaraDB RDS for MySQL instance for data enrichment.
Pull all data only once
When you run a data transformation job for the first time, Log Service pulls all data from a specified table and then no longer pulls data. If your database is not updated, we recommend that you use this method.
Pull all data at regular intervals
When you run a data transformation job, Log Service pulls all data from a specified table at regular intervals. This way, Log Service can synchronize data with your database in a timely manner. However, this method requires a long period of time. If the data volume of your database is less than or equal to 2 GB and the value of the refresh_interval parameter is greater than or equal to 300 seconds, we recommend that you use this method.
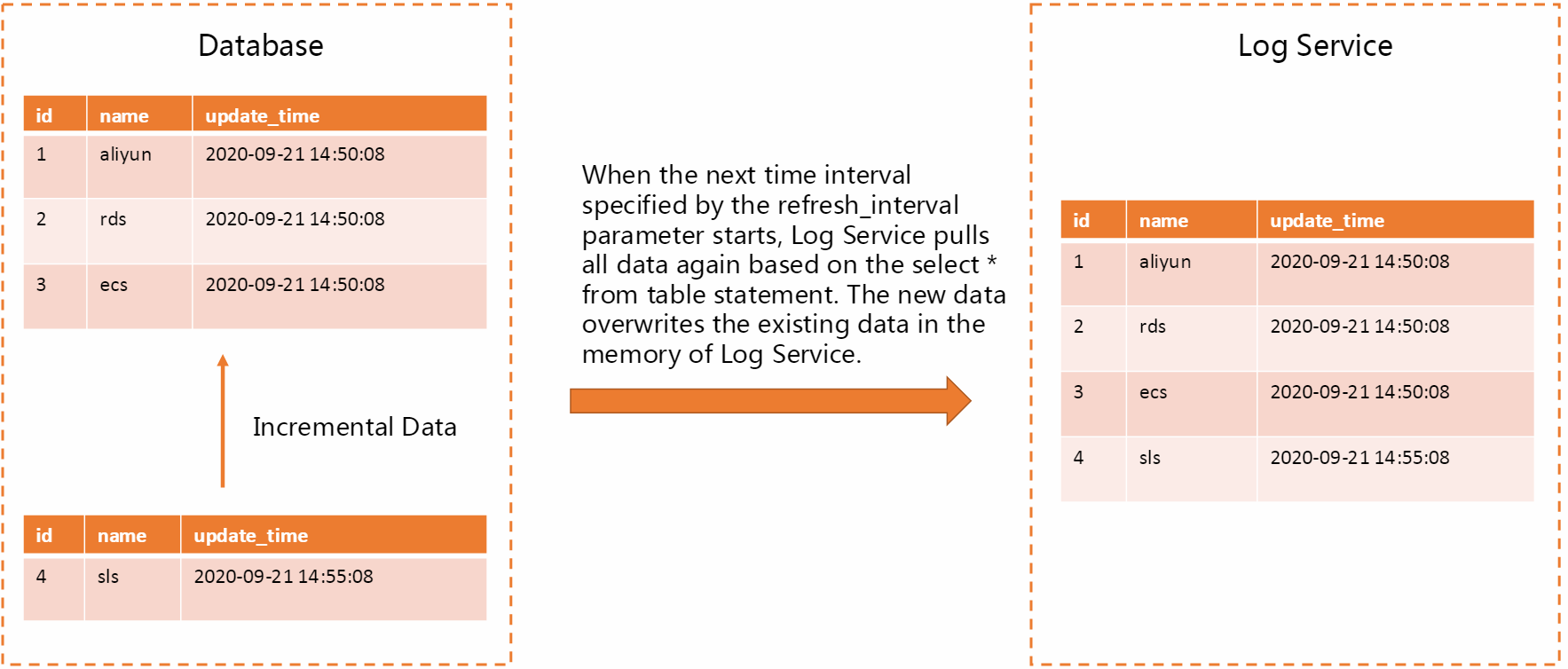
Pull incremental data at regular intervals
When you run a data transformation job, Log Service pulls only incremental data based on the timestamp field of a specified database. If you use this method, Log Service pulls only the newly added data. This method is efficient. You can set the refresh_interval parameter to 1 second to synchronize data within seconds. If the data volume of your database is large, your data is frequently updated, or you require data to be pulled in a timely manner, we recommend that you use this method.
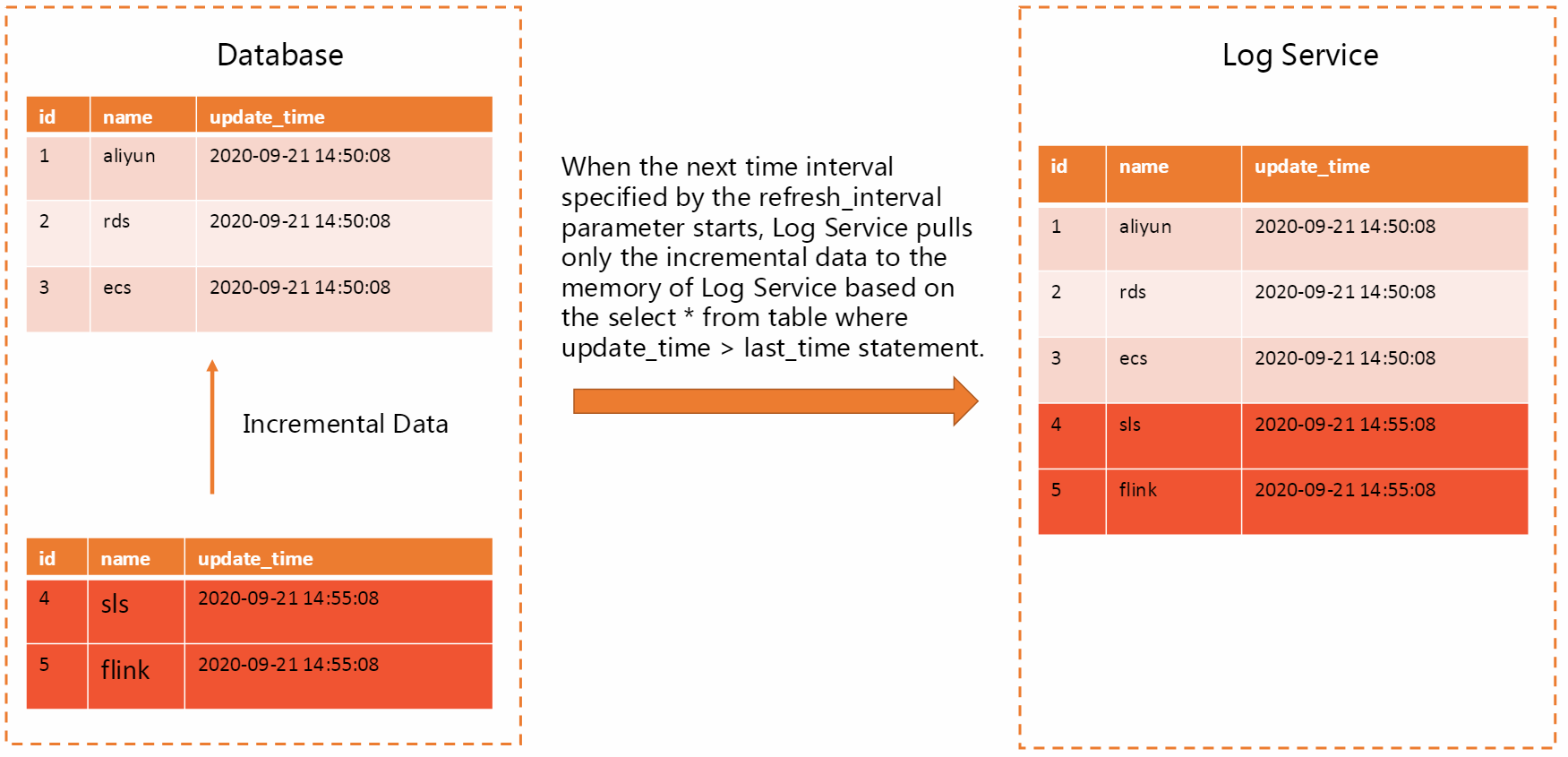
Syntax
res_rds_mysql(address="The address of the database from which data is pulled", username="The username used to connect to the database", password="The password used to connect to the database", database="The name of the database", table=None, sql=None, fields=None, fetch_include_data=None, fetch_exclude_data=None, refresh_interval=0, base_retry_back_off=1, max_retry_back_off=60, primary_keys=None, use_ssl=false, update_time_key=None, deleted_flag_key=None)NoteYou can also use the res_rds_mysql function to pull data from a database that is created in an AnalyticDB for MySQL or PolarDB for MySQL cluster. In these scenarios, you need to only replace the address, username, password, and name of the database in the transformation rule with the actual values.
Parameters
Parameter
Type
Required
Description
address
String
Yes
The endpoint or IP address of the database to which you want to connect. If the port number is not 3306, specify a value in the
IP address:Portformat. For more information, see View and change the endpoints and port numbers.username
String
Yes
The username that is used to connect to the database.
password
String
Yes
The password that is used to connect to the database.
database
String
Yes
The name of the database to which you want to connect.
table
String
Yes
The name of the table from which you want to pull data. If the sql parameter is configured, this parameter is not required.
sql
String
Yes
Use a SQL SELECT statement to retrieve all relevant data from the database and load it into processing memory. SQL can optimize memory usage by filtering fields and rows, reducing the space occupied by the processing memory table. If the table parameter is configured, this parameter is not required.
fields
String list
No
The string list or string alias list. If you do not configure this parameter, all columns returned for the sql or table parameter are used. For example, if you want to rename the name column in the ["user_id", "province", "city", "name", "age"] list to user_name, you must set the fields parameter to ["user_id", "province", "city", ("name", "user_name"), ("nickname", "nick_name"), "age"].
NoteIf you configure the sql, table, and fields parameters together, the SQL statement in the sql parameter is executed. The table and fields parameters do not take effect.
fetch_include_data
String
No
The field whitelist. Logs whose fields match the fetch_include_data parameter are retained. Logs whose fields do not match this parameter are discarded.
If you do not configure this parameter or set this parameter to None, the field whitelist feature is disabled.
If you set this parameter to a specific field and field value, the logs that contain the field and field value are retained.
fetch_exclude_data
String
No
The field blacklist. Logs whose fields match the fetch_exclude_data parameter are discarded. Logs whose fields do not match this parameter are retained.
If you do not configure this parameter or set this parameter to None, the field blacklist feature is disabled.
If you set this parameter to a specific field and field value, the logs that contain the field and field value are discarded.
NoteIf you configure both the fetch_include_data and fetch_exclude_data parameters, data is pulled first based on the setting of the fetch_include_data parameter and then based on the setting of the fetch_exclude_data parameter.
refresh_interval
Numeric string or number
No
The interval at which data is pulled from ApsaraDB RDS for MySQL. Unit: seconds. Default value: 0. This value indicates that all data is pulled only once.
base_retry_back_off
Number
No
The interval at which the system attempts to pull data again after a pulling failure. Default value: 1. Unit: seconds.
max_retry_back_off
Int
No
The maximum interval between two consecutive retries after a pulling failure. Default value: 60. Unit: seconds. We recommend that you use the default value.
primary_keys
String/List
No
The primary key in the key-value store of the in-memory dimension table. If you configure this parameter, data in the table is saved to memory as a dictionary in the Key:Value format. A key in the dictionary is the value of the primary_keys parameter. A value in the dictionary is an entire row of data in the table.
NoteThe primary_keys parameter must be set. Otherwise, performance will be significantly impacted and task delays may be caused.
The value of the primary_keys parameter must exist in the fields that are pulled from the table.
The value of the primary_keys parameter is case-sensitive.
use_ssl
Boolean
No
Specifies whether to use the SSL protocol to connect to the ApsaraDB RDS for MySQL instance. Default value: false.
NoteIf SSL encryption is enabled on the ApsaraDB RDS for MySQL instance, Log Service connects to the instance over SSL. However, the server certificate is not verified. The server certificate cannot be used to establish connections.
update_time_key
String
No
The time field that is used to pull incremental data. If you do not configure this parameter, all data is pulled. For example, update_time in update_time_key="update_time" indicates the time field of data update in the database. The time field supports the following data types: datetime, timestamp, integer, float, and decimal. Make sure that the values of the time field increase in chronological order.
NoteLog Service pulls incremental data based on the time field. Make sure that an index is configured for this field in the table. If the index is not configured, a full table scan is performed. In addition, an error is reported, which indicates a failure to pull incremental data.
deleted_flag_key
String
No
The data that does not need to be transformed and is discarded when incremental data is pulled. For example, if the value of key in update_time_key="key" meets the following condition, the value is parsed as deleted data:
Boolean: true
Datetime and timestamp: not empty
Char and varchar: 1, true, t, yes, and y
Integer: non-zero
NoteYou must configure the deleted_flag_key parameter together with the update_time_key parameter.
If you configure the update_time_key parameter but do not configure the deleted_flag_key parameter, no data is discarded when incremental data is pulled.
connector
String
No
The connector that is used to remotely connect to the database. Valid values: mysql and pgsql. Default value: mysql.
Response
A table that contains multiple columns is returned. The columns are defined by the fields parameter.
Error handling
If an error occurs when data is pulled, the error is reported, but the data transformation job continues to run. Retries are performed based on the value of the base_retry_back_off parameter. For example, the first retry interval is 1 second, and the first retry fails. The second retry interval is twice the length of the first one. The process continues until the interval reaches the value of the max_retry_back_off parameter. If the error persists, retries are performed based on the value of the max_retry_back_off parameter. If a retry succeeds, the retry interval resets to the initial value, which is 1 second.
Examples
Pull all data
Example 1: Pull data from the test_table table in the test_db database at 300-second intervals.
res_rds_mysql( address="rm-uf6wjk5****mo.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", refresh_interval=300, )Example 2: Pull data from the test_table table, excluding the data records whose status value is delete.
res_rds_mysql( address="rm-uf6wjk5****mo.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", refresh_interval=300, fetch_exclude_data="'status':'delete'", )Example 3: Pull the data records whose status value is exit from the test_table table.
res_rds_mysql( address="rm-uf6wjk5***mo.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", refresh_interval=300, fetch_include_data="'status':'exit'", )Example 4: Pull the data records whose status value is exit from the test_table table, excluding the data records whose name value is aliyun.
res_rds_mysql( address="rm-uf6wjk5***mo.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", refresh_interval=300, fetch_include_data="'status':'exit'", fetch_exclude_data="'name':'aliyun'", )Example 5: Use the pgsql connector to connect to a Hologres database and pull data from the test_table table.
res_rds_mysql( address="hgpostcn-cn-****-cn-hangzhou.hologres.aliyuncs.com:80", username="test_username", password="****", database="aliyun", table="test_table", connector="pgsql", )Example 6: Pull data by using the primary_keys parameter.
If you configure the primary_keys parameter, its value is extracted as a key. The data pulled from the table is saved to memory in the {"10001":{"userid":"10001","city_name":"beijing","city_number":"12345"}} format. In this case, data is pulled at a high speed. If you want to pull a large volume of data, we recommend that you use this method. If you do not configure the primary_keys parameter, the function traverses the table by row. Then, the function pulls data and saves the data to memory in the [{"userid":"10001","city_name":"beijing","city_number":"12345"}] format. In this case, data is pulled at a low speed, but only a small portion of memory is occupied. If you want to pull a small volume of data, we recommend that you use this method.
Table
userid
city_name
city_number
10001
beijing
12345
Raw log
# Data Record 1 userid:10001 gdp:1000 # Data Record 2 userid:10002 gdp:800Transformation rule
e_table_map( res_rds_mysql( address="rm-uf6wjk5***mo.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", primary_keys="userid", ), "userid", ["city_name", "city_number"], )Result
# Data Record 1 userid:10001 gdp:1000 city_name: beijing city_number:12345 # Data Record 2 userid:10002 gdp:800
Pull incremental data
Example 1: Pull incremental data.
NoteYou can pull incremental data from a table only if the following conditions are met:
The table has a unique primary key and a time field, such as the item_id and update_time fields.
The primary_keys, refresh_interval, and update_time_key parameters are configured.
Table
item_id
item_name
price
1001
Orange
10
1002
Apple
12
1003
Mango
16
Raw log
# Data Record 1 item_id: 1001 total: 100 # Data Record 2 item_id: 1002 total: 200 # Data Record 3 item_id: 1003 total: 300Transformation rule
e_table_map( res_rds_mysql( address="rm-uf6wjk5***mo.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", primary_key="item_id", refresh_interval=1, update_time_key="update_time", ), "item_id", ["item_name", "price"], )Result
# Data Record 1 item_id: 1001 total: 100 item_name: Orange price:10 # Data Record 2 item_id: 1002 total: 200 item_name: Apple price:12 # Data Record 3 item_id: 1003 total: 300 item_name: Mango price:16
Example 2: Configure the deleted_flag_key parameter to discard specified data when incremental data is pulled.
Table
item_id
item_name
price
update_time
Is_deleted
1001
Orange
10
1603856138
False
1002
Apple
12
1603856140
False
1003
Mango
16
1603856150
False
Raw log
# Data Record 1 item_id: 1001 total: 100 # Data Record 2 item_id: 1002 total: 200 # Data Record 3 item_id: 1003 total: 300Transformation rule
e_table_map( res_rds_mysql( address="rm-uf6wjk5***mo.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", primary_key="item_id", refresh_interval=1, update_time_key="update_time", deleted_flag_key="is_deleted", ), "item_id", ["item_name", "price"], )Result
The res_rds_mysq function pulls three data records from the table to the memory of the server on which Log Service runs. These data records are compared with the existing data records in the source Logstore to check whether the records match. If you want to discard the data record whose item_id is 1001, find the data record whose item_id is 1001 in the table and change the value of the Is_deleted field to true. This way, the data record 1001 is discarded the next time that the in-memory dimension table is updated.
# Data Record 2 item_id: 1002 total: 200 item_name: Apple price:12 # Data Record 3 item_id: 1003 total: 300 item_name: Mango price:1
References
This function can be used together with other functions. For more information, see Use Simple Log Service to connect to an ApsaraDB RDS for MySQL instance for data enrichment.
res_log_logstore_pull
The res_log_logstore_pull function pulls data from another Logstore when you transform data in a Logstore.
Syntax
res_log_logstore_pull(endpoint, ak_id, ak_secret, project, logstore, fields, from_time="begin", to_time=None, fetch_include_data=None, fetch_exclude_data=None, primary_keys=None, fetch_interval=2, delete_data=None, base_retry_back_off=1, max_retry_back_off=60, ttl=None, role_arn=None)Parameters
Parameter
Type
Required
Description
endpoint
String
Yes
The endpoint. For more information, see Endpoints. By default, an HTTPS endpoint is used. You can also use an HTTP endpoint. In special cases, you may need to use a port other than port 80 or 443.
ak_id
String
Yes
The AccessKey ID of your Alibaba Cloud account. To ensure data security, we recommend that you configure this parameter in Advanced Parameter Settings. For more information about how to configure the advanced parameters, see Create a data transformation job.
ak_secret
String
Yes
The AccessKey secret of your Alibaba Cloud account. To ensure data security, we recommend that you configure this parameter in Advanced Parameter Settings. For more information about how to configure the advanced parameters, see Create a data transformation job.
project
String
Yes
The name of the project from which you want to pull data.
logstore
String
Yes
The name of the Logstore from which you want to pull data.
fields
String list
Yes
The string list or string alias list. If a log does not contain a specified field, the value of this field is an empty string. For example, if you want to rename the name column in the ["user_id", "province", "city", "name", "age"] list to user_name, you must set this parameter to ["user_id", "province", "city", ("name", "user_name"), ("nickname", "nick_name"), "age"].
from_time
String
No
The server time when the first data pulling from the Logstore starts. Default value: begin. This value indicates that Log Service starts to pull data from the first log. The following time formats are supported:
UNIX timestamp.
Time string.
Custom string, such as begin or end.
Expression: the time that is returned by the dt_ function. For example, the function dt_totimestamp(dt_truncate(dt_today(tz="Asia/Shanghai"), day=op_neg(-1))) returns the start time of data pulling, which is one day before the current time. If the current time is 2019-5-5 10:10:10 (UTC+8), the returned time is 2019-5-4 10:10:10 (UTC+8).
to_time
String
No
The server time when the first data pulling from the Logstore ends. Default value: None. This value indicates that Log Service stops pulling data at the last log. The following time formats are supported:
UNIX timestamp.
Time string.
Custom string, such as begin or end.
Expression: the time that is returned by the dt_ function.
If you do not configure this parameter or set this parameter to None, data is pulled from the latest logs in a continuous manner.
NoteIf you set this parameter to a point in time that is later than the current time, only the existing data in the Logstore is pulled. New data is not pulled.
fetch_include_data
String
No
The field whitelist. Logs whose fields match the fetch_include_data parameter are retained. Logs whose fields do not match this parameter are discarded.
If you do not configure this parameter or set this parameter to None, the field whitelist feature is disabled.
If you set this parameter to a specific field and field value, the logs that contain the field and field value are retained.
fetch_exclude_data
String
No
The field blacklist. Logs whose fields match the fetch_exclude_data parameter are discarded. Logs whose fields do not match this parameter are retained.
If you do not configure this parameter or set this parameter to None, the field blacklist feature is disabled.
If you set this parameter to a specific field and field value, the logs that contain the field and field value are discarded.
NoteIf you configure both the blacklist and whitelist parameters, the logs whose fields match the blacklist parameter are discarded first, and then the remaining logs whose fields match the whitelist parameter are retained.
primary_keys
String list
No
The list of primary key fields that are used to maintain a table. If you change the name of a primary key field by using the fields parameter, you must use the new name to specify the primary key field for this parameter.
NoteThe value of the primary_keys parameter can contain only the single-value strings that are specified in the value of the fields parameter.
This parameter is valid when only one shard exists in the Logstore from which data is pulled.
The primary_keys parameter must be set. Otherwise, performance will be significantly impacted and task delays may be caused.
The value of the primary_keys parameter is case-sensitive.
fetch_interval
Int
No
The interval between two consecutive data pulling requests when data is pulled in a continuous manner. Default value: 2. Unit: seconds. The value must be greater than or equal to 1 second.
delete_data
String
No
The operation to delete data from the table. Data records that meet specified conditions and contain the value of
primary_keysare deleted. For more information, see Query string syntax.base_retry_back_off
Number
No
The interval at which the system attempts to pull data again after a pulling failure. Default value: 1. Unit: seconds.
max_retry_back_off
Int
No
The maximum interval between two consecutive retries after a pulling failure. Default value: 60. Unit: seconds. We recommend that you use the default value.
ttl
Int
No
The number of seconds that is used to determine the range for data pulling in a continuous manner. Data pulling starts when log data is generated and ends ttl seconds after the time that the log data is generated. Unit: seconds. Default value: None. This value indicates that all log data is pulled.
role_arn
String
No
The Alibaba Cloud Resource Name (ARN) of the RAM role that is used. The RAM role must have the read permissions on the Logstore from which data is pulled. In the RAM console, you can view the ARN of a RAM role in the Basic Information section on the details page of the role. Example:
acs:ram::1379******44:role/role-a. For more information about how to obtain the ARN of a RAM role, see View the information about a RAM role.Response
A table that contains multiple columns is returned.
Error handling
If an error occurs when data is pulled, the error is reported, but the data transformation job continues to run. Retries are performed based on the value of the base_retry_back_off parameter. For example, the first retry interval is 1 second and the first retry fails. The second retry interval is twice the length of the first one. The process continues until the interval reaches the value of the max_retry_back_off parameter. If the error persists, retries are performed based on the value of the max_retry_back_off parameter. If a retry succeeds, the retry interval resets to the initial value, which is 1 second.
Examples
In this example, the data of fields key1 and key2 is pulled from the test_logstore Logstore of the test_project project. Data pulling starts when log data is written to the Logstore. Data pulling ends when the data write operation is complete. The data is pulled only once.
res_log_logstore_pull( "cn-hangzhou.log.aliyuncs.com", "LT****Gw", "ab****uu", "test_project", "test_logstore", ["key1", "key2"], from_time="begin", to_time="end", )In this example, the data of fields key1 and key2 is pulled from the test_logstore Logstore of the test_project project. Data pulling starts when log data is written to the Logstore. Data pulling ends when the data write operation is complete. The data is pulled at 30-second intervals in a continuous manner.
res_log_logstore_pull( "cn-hangzhou.log.aliyuncs.com", "LT****Gw", "ab****uu", "test_project", "test_logstore", ["key1", "key2"], from_time="begin", to_time=None, fetch_interval=30, )In this example, a blacklist is configured to skip the data records that contain key1:value1 when data is pulled from a Logstore.
res_log_logstore_pull( "cn-hangzhou.log.aliyuncs.com", "LT****Gw", "ab****uu", "test_project", "test_logstore", ["key1", "key2"], from_time="begin", to_time=None, fetch_interval=30, fetch_exclude_data="key1:value1", )In this example, a whitelist is configured to pull the data records that contain key1:value1 from a Logstore.
res_log_logstore_pull( "cn-hangzhou.log.aliyuncs.com", "LT****Gw", "ab****uu", "test_project", "test_logstore", ["key1", "key2"], from_time="begin", to_time=None, fetch_interval=30, fetch_include_data="key1:value1", )In this example, the data of fields key1 and key2 is pulled from the test_logstore Logstore of the test_project project. Data pulling starts when log data is generated and ends 40,000,000 seconds after the time that the log data is generated.
res_log_logstore_pull( "cn-hangzhou.log.aliyuncs.com", "LTAI*****Cajvr", "qO0Tp*****jJ9", "test_project", "test_logstore", fields=["key1","key2"], ttl="40000000" )In this example, the data of fields key1 and key2 is pulled from the test-logstore Logstore of the project-test1 project. The service-linked role of Log Service is used for authorization. Data pulling starts when log data is written to the Logstore. Data pulling ends when the data write operation is complete. The data is pulled only once.
res_log_logstore_pull( "pub-cn-hangzhou-staging-intranet.log.aliyuncs.com", "", "", "project-test1", "test-logstore", ["key1", "key2"], from_time="2022-7-27 10:10:10 8:00", to_time="2022-7-27 14:30:10 8:00", role_arn="acs:ram::***:role/aliyunserviceroleforslsaudit", )In this example, the data of fields key1 and key2 is pulled from the test-logstore Logstore of the project-test1 project. A default role is used for authorization. Data pulling starts when log data is written to the Logstore. Data pulling ends when the data write operation is complete. The data is pulled only once.
res_log_logstore_pull( "cn-chengdu.log.aliyuncs.com", "", "", "project-test1", "test-logstore", ["key1", "key2"], from_time="2022-7-21 10:10:10 8:00", to_time="2022-7-21 10:30:10 8:00", role_arn="acs:ram::***:role/aliyunlogetlrole", )
References
This function can be used together with other functions. For more information, see Pull data from one logstore to enrich log data in another logstore.
res_oss_file
The res_oss_file function pulls data from an object in a specified OSS bucket. The data can be updated at regular intervals.
We recommend that you use a Log Service project that resides in the same region as the OSS bucket. This way, the object data in the bucket can be pulled over an internal network of Alibaba Cloud. An internal network is stable and fast.
Syntax
res_oss_file(endpoint, ak_id, ak_key, bucket, file, format='text', change_detect_interval=0, base_retry_back_off=1, max_retry_back_off=60, encoding='utf8', error='ignore')Parameters
Parameter
Type
Required
Description
endpoint
String
Yes
The endpoint of the OSS bucket. For more information, see Regions and endpoints. By default, an HTTPS endpoint is used. You can also use an HTTP endpoint. In special cases, you may need to use a port other than port 80 or 443.
ak_id
String
Yes
The AccessKey ID of your Alibaba Cloud account. To ensure data security, we recommend that you configure this parameter in Advanced Parameter Settings. For more information about how to configure the advanced parameters, see Create a data transformation job.
ak_key
String
Yes
The AccessKey secret of your Alibaba Cloud account. To ensure data security, we recommend that you configure this parameter in Advanced Parameter Settings. For more information about how to configure the advanced parameters, see Create a data transformation job.
bucket
String
Yes
The name of the OSS bucket from which you want to pull data.
file
String
Yes
The path to the object from which you want to pull data. Example: test/data.txt. Do not enter a forward slash (/) at the start of the path.
format
String
Yes
The format of the output file. Valid values:
Text: text format
Binary: byte stream format
change_detect_interval
String
No
The interval at which Log Service pulls the object data from OSS. Unit: seconds. The system checks whether the object is updated when data is pulled. If the object is updated, the incremental data is pulled. Default value: 0. This value indicates that no incremental data is pulled. All data is pulled only once when the function is called.
base_retry_back_off
Number
No
The interval at which the system attempts to pull data again after a pulling failure. Default value: 1. Unit: seconds.
max_retry_back_off
Int
No
The maximum interval between two consecutive retries after a pulling failure. Default value: 60. Unit: seconds. We recommend that you use the default value.
encoding
String
No
The encoding format. If you set the format parameter to Text, this parameter is automatically set to utf8.
error
String
No
The method that is used to handle errors. This parameter is valid only when the UnicodeError message is reported. Valid values:
ignore: The system skips the data of an invalid format and continues to encode data.
xmlcharrefreplace: The system uses appropriate XML character references to replace the characters that cannot be encoded.
For more information, see Error Handlers.
decompress
String
No
Specifies whether to decompress the object. Valid values:
None: The object is not decompressed. This is the default value.
gzip: The object is decompressed by using gzip.
Response
Object data is returned in the byte stream or text format.
Error handling
If an error occurs when data is pulled, the error is reported, but the data transformation job continues to run. Retries are performed based on the value of the base_retry_back_off parameter. For example, the first retry interval is 1 second and the first retry fails. The second retry interval is twice the length of the first one. The process continues until the interval reaches the value of the max_retry_back_off parameter. If the error persists, retries are performed based on the value of the max_retry_back_off parameter. If a retry succeeds, the retry interval resets to the initial value, which is 1 second.
Examples
Example 1: Pull JSON data from OSS.
JSON data
{ "users": [ { "name": "user1", "login_historys": [ { "date": "2019-10-10 0:0:0", "login_ip": "203.0.113.10" }, { "date": "2019-10-10 1:0:0", "login_ip": "203.0.113.10" } ] }, { "name": "user2", "login_historys": [ { "date": "2019-10-11 0:0:0", "login_ip": "203.0.113.20" }, { "date": "2019-10-11 1:0:0", "login_ip": "203.0.113.30" }, { "date": "2019-10-11 1:1:0", "login_ip": "203.0.113.50" } ] } ] }Raw log
content: 123Transformation rule
e_set( "json_parse", json_parse( res_oss_file( endpoint="http://oss-cn-hangzhou.aliyuncs.com", ak_id="LT****Gw", ak_key="ab****uu", bucket="log-etl-staging", file="testjson.json", ) ), )Result
content: 123 prjson_parse: '{ "users": [ { "name": "user1", "login_historys": [ { "date": "2019-10-10 0:0:0", "login_ip": "203.0.113.10" }, { "date": "2019-10-10 1:0:0", "login_ip": "203.0.113.10" } ] }, { "name": "user2", "login_historys": [ { "date": "2019-10-11 0:0:0", "login_ip": "203.0.113.20" }, { "date": "2019-10-11 1:0:0", "login_ip": "203.0.113.30" }, { "date": "2019-10-11 1:1:0", "login_ip": "203.0.113.50" } ] } ] }'
Example 2: Pull text content from OSS.
Text content
Test bytesRaw log
content: 123Transformation rule
e_set( "test_txt", res_oss_file( endpoint="http://oss-cn-hangzhou.aliyuncs.com", ak_id="LT****Gw", ak_key="ab****uu", bucket="log-etl-staging", file="test.txt", ), )Result
content: 123 test_txt: Test bytes
Example 3: Pull data from a compressed OSS object and decompress the object.
Content of the compressed object
Test bytes\nupdate\n123Raw log
content:123Transformation rule
e_set( "text", res_oss_file( endpoint="http://oss-cn-hangzhou.aliyuncs.com", ak_id="LT****Gw", ak_key="ab****uu", bucket="log-etl-staging", file="test.txt.gz", format="binary", change_detect_interval=30, decompress="gzip", ), )Result
content:123 text: Test bytes\nupdate\n123
Example 4: Access an object in an OSS bucket whose ACL is public-read-write. No AccessKey pairs are used.
Content of the compressed object
Test bytesRaw log
content:123Transformation rule
e_set( "test_txt", res_oss_file( endpoint="http://oss-cn-hangzhou.aliyuncs.com", bucket="log-etl-staging", file="test.txt", ), )Result
content: 123 test_txt: Test bytes
References
This function can be used together with other functions. For more information, see Pull a CSV file from OSS to enrich data.