PyODPS is the Python SDK for MaxCompute. When used inside DataWorks, PyODPS runs as a managed node — the platform handles scheduling, execution, and the MaxCompute connection. You write Python code; DataWorks runs it on demand or on a schedule.
This topic walks you through creating a PyODPS 3 node in DataWorks, writing table operations in Python, and verifying the output.
Prerequisites
Before you begin, ensure that you have:
-
Activated MaxCompute and DataWorks
-
Created a MaxCompute project
-
Created a DataWorks workspace and attached it to MaxCompute computing resources
Limits
Each PyODPS node has the following hard limits:
| Limit | Value | Behavior when exceeded |
|---|---|---|
| Python version | 3.7 | Fixed; cannot be changed |
| Data per run | 50 MB | DataWorks terminates the node |
| Memory per run | 1 GB | DataWorks terminates the node |
We recommend that you do not write Python code that will process a large amount of data in PyODPS nodes. To write and debug code efficiently, use IntelliJ IDEA locally rather than the DataWorks code editor.
How it works
Each PyODPS node in DataWorks has a pre-configured global variable o (also available as odps). This variable is the MaxCompute entry object — you use it to call the PyODPS SDK directly without writing any connection or authentication code.
This is the key difference from using PyODPS outside DataWorks. You skip theODPS()initialization step entirely. Theovariable is ready to use as soon as the node starts.
Create a PyODPS node
This topic uses a PyODPS 3 node as the example. For full details on node types and configuration options, see Develop a PyODPS 3 task.
-
Log on to the DataWorks console and go to the DataStudio page.
-
In the left panel, right-click Business Flow and select Create Workflow.
-
In the new workflow, right-click the workflow name and choose Create > MaxCompute > PyODPS 3.
-
In the Create Node dialog box, enter a value for Node Name and click Commit.
Write and run table operations
The following example covers the full cycle of table operations: create a table, write records, read records by iteration, read records with SQL, and drop the table.
Create a table
from odps import ODPS
# o is the pre-configured MaxCompute entry object — no initialization needed.
# Create a non-partitioned table with two columns: num (bigint) and id (string).
table = o.create_table('my_new_table', 'num bigint, id string', if_not_exists=True)Write data
records = [[111, 'aaa'],
[222, 'bbb'],
[333, 'ccc'],
[444, 'Chinese']]
o.write_table(table, records)Read data
# Read records using the read_table API.
for record in o.read_table(table):
print(record[0], record[1])Execute SQL and read results
# Run a SQL query against the table.
result = o.execute_sql('select * from my_new_table;', hints={'odps.sql.allow.fullscan': 'true'})
# Read the query results.
with result.open_reader() as reader:
for record in reader:
print(record[0], record[1])Drop the table
table.drop()Complete example
Paste the following code into the code editor of your PyODPS 3 node to run the full example in one go. For more information about table operations and SQL, see Tables and SQL.
from odps import ODPS
# Create a non-partitioned table named my_new_table. The non-partitioned table contains the fields that are of the specified data types and have the specified names.
# Variable o (or odps) is the pre-configured MaxCompute entry — no initialization needed.
table = o.create_table('my_new_table', 'num bigint, id string', if_not_exists=True)
# Write data to the my_new_table table.
records = [[111, 'aaa'],
[222, 'bbb'],
[333, 'ccc'],
[444, 'Chinese']]
o.write_table(table, records)
# Read data from the my_new_table table.
for record in o.read_table(table):
print(record[0],record[1])
# Read data from the my_new_table table by executing an SQL statement.
result = o.execute_sql('select * from my_new_table;',hints={'odps.sql.allow.fullscan': 'true'})
# Obtain the execution result of the SQL statement.
with result.open_reader() as reader:
for record in reader:
print(record[0],record[1])
# Delete the table.
table.drop()Verify the output
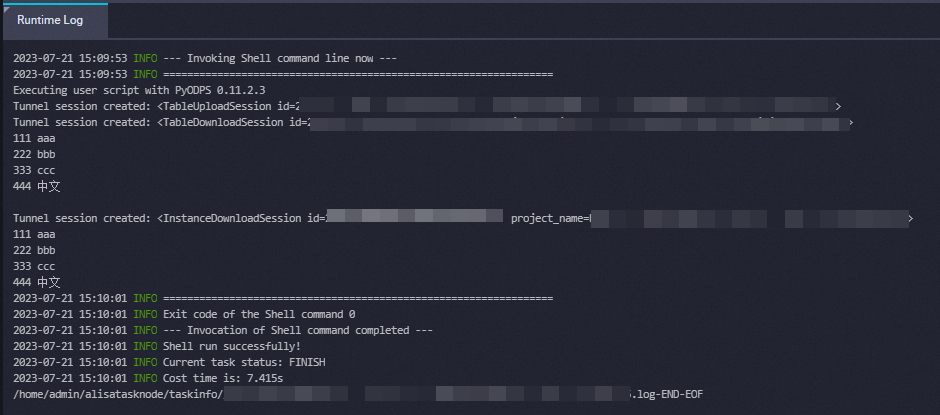
After writing the code, click the ![]() icon in the top toolbar to run the node. Open the Runtime Log tab to view the execution output.
icon in the top toolbar to run the node. Open the Runtime Log tab to view the execution output.
A successful run produces output similar to: