Use DataWorks Data Integration to batch-load messages from a Kafka cluster into a MaxCompute table for analytics.
Prerequisites
Before you begin, make sure you have:
-
A MaxCompute data source added to DataWorks. For details, see Associate a MaxCompute computing resource
-
A workflow created in your DataWorks workspace. This topic uses a basic-mode workspace as an example. For details, see Create a workflow
-
A Kafka cluster that is operational This topic uses Alibaba Cloud Elastic MapReduce (EMR) to deploy the Kafka cluster automatically. For setup steps, see Kafka Quick Start. The example cluster has the following configuration: The cluster runs in a virtual private cloud (VPC) in the China (Hangzhou) region. The primary instance group has both public and private IP addresses.
Component Version EMR EMR-3.12.1 Cluster type Kafka Kafka 2.11-1.0.1 ZooKeeper 3.4.12 Ganglia 3.7.2 Kafka-Manager 1.3.X.XX -
TCP ports 22 and 9092 open in the security group of the EMR cluster header host. These allow SSH access and Kafka broker communication for MaxCompute and DataWorks.
Background
Kafka is a distributed publish-subscribe messaging system designed for high throughput — capable of processing millions of messages per second. It is commonly used for log collection and user behavior tracking.
A Kafka cluster consists of producers, brokers, consumers, and a ZooKeeper cluster. ZooKeeper manages cluster configuration and coordinates services.
Messages are organized into topics. Each topic is stored across one or more partitions distributed across broker nodes. Multiple producers can write to a topic, and multiple consumers can read from it. Within each partition, every message is assigned a zero-based offset that uniquely identifies it.
Step 1: Prepare Kafka data
Create a test topic and write sample messages to it on the EMR cluster header host.
-
Log on to the EMR cluster header host.
-
Go to the EMR Hadoop console.
-
In the top navigation bar, click Cluster Management.
-
Find your cluster and go to its details page.
-
Click the host list, find the header host address, and connect using SSH.
-
-
Create a test topic named
testkafkawith 10 partitions and a replication factor of 3.kafka-topics.sh --zookeeper emr-header-1:2181/kafka-1.0.1 --partitions 10 --replication-factor 3 --topic testkafka --create -
Write test data. Run the following command to start a producer that writes to
testkafka. Write more than 10 records to ensure valid test results.kafka-console-producer.sh --broker-list emr-header-1:9092 --topic testkafka -
Verify that data is written. In a separate SSH session, run a consumer to read from the beginning of the topic. Data appears in the output if the write succeeded.
kafka-console-consumer.sh --bootstrap-server emr-header-1:9092 --topic testkafka --from-beginning
Step 2: Create a target table in DataWorks
Create a MaxCompute table to receive the Kafka data.
-
Go to the Data Development page.
-
Log on to the DataWorks console.
-
In the left navigation pane, click Data Development And O\&M > Data Studio.
-
Select your workspace from the drop-down list and click Go To Data Studio.
-
-
Right-click your workflow and choose Create Table > MaxCompute > Table.
-
In the Create Table dialog box, enter a table name and click Create.
Table names must start with a letter and cannot contain Chinese characters or special characters. If multiple MaxCompute data sources are attached to Data Studio, select the appropriate MaxCompute Engine Instance.
-
On the table editing page, click DDL Statement.
-
In the DDL dialog box, enter the following statement and click Generate Table Schema.
Table column Kafka Reader field Description key__key__Message key value__value__Complete message content partition1__partition__Partition where the message resides timestamp1__timestamp__Message timestamp offset__offset__Message offset within the partition t123'123'Constant value event_idevent_idCustom field from the message body tagtag.descNested field from the message body CREATE TABLE testkafka ( key string, value string, partition1 string, timestamp1 string, offset string, t123 string, event_id string, tag string );The table columns map to Kafka Reader fields as follows: Kafka Reader also provides a
__headers__built-in field for message headers. To use different column names or add more fields, see Kafka Reader. -
Click Deploy to Production Environment, then click OK.
Step 3: Synchronize data
3.1 Create an exclusive resource group
Kafka Reader cannot run on the shared resource group for Data Integration. Create an exclusive resource group before configuring the sync node. For details, see Use exclusive resource groups for Data Integration.
3.2 Create and configure a sync node
-
In Data Studio, right-click your workflow and choose Create Node > Data Integration > Offline Sync.
-
In the Create Node dialog box, enter a Name and click Confirm.
-
In the top navigation bar, click the
 icon to switch to script mode.
icon to switch to script mode. -
Click the
 icon to open the script template.
icon to open the script template. -
Replace the script content with the following configuration.
To load Kafka data on a recurring schedule (for example, every hour), use the
beginDateTimeandendDateTimeparameters to define the time range and schedule the task to run hourly. For details, see Kafka Reader.Parameter Description serverBootstrap server address of the Kafka cluster in <host>:<port>formatgroup.idConsumer group ID. Run kafka-consumer-groups.sh --listto view available groups (see below)valueTypeEncoding type for message values. Set to ByteArrayfor raw byte datakeyTypeEncoding type for message keys. Set to ByteArrayfor raw byte datatopicName of the Kafka topic to read from waitTimeSeconds to wait for new messages before the read task ends beginOffsetStarting offset in the partition (inclusive). Use 0to read from the beginningendOffsetEnding offset in the partition (exclusive) columnFields to read. Supports built-in fields ( __key__,__value__,__partition__,__timestamp__,__offset__,__headers__), constants (quoted strings like'123'), and nested message fields (liketag.desc)datasourceMaxCompute data source name configured in DataWorks { "type": "job", "steps": [ { "stepType": "kafka", "parameter": { "server": "47.xxx.xxx.xxx:9092", "kafkaConfig": { "group.id": "console-consumer-83505" }, "valueType": "ByteArray", "column": [ "__key__", "__value__", "__partition__", "__timestamp__", "__offset__", "'123'", "event_id", "tag.desc" ], "topic": "testkafka", "keyType": "ByteArray", "waitTime": "10", "beginOffset": "0", "endOffset": "3" }, "name": "Reader", "category": "reader" }, { "stepType": "odps", "parameter": { "partition": "", "truncate": true, "compress": false, "datasource": "odps_source", "column": [ "key", "value", "partition1", "timestamp1", "offset", "t123", "event_id", "tag" ], "emptyAsNull": false, "table": "testkafka" }, "name": "Writer", "category": "writer" } ], "version": "2.0", "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] }, "setting": { "errorLimit": { "record": "" }, "speed": { "throttle": false, "concurrent": 1 } } }Key parameters for the Kafka Reader: Find consumer group names and offset values Run the following command on the EMR cluster header host to list consumer groups:
kafka-consumer-groups.sh --bootstrap-server emr-header-1:9092 --listExample output:
_emr-client-metrics-handler-group console-consumer-69493 console-consumer-83505 console-consumer-21030 console-consumer-45322 console-consumer-14773To get the current offsets for a specific consumer group, run:
kafka-consumer-groups.sh --bootstrap-server emr-header-1:9092 --describe --group console-consumer-83505Example output:
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID testkafka 6 0 0 0 - - - testkafka 0 0 0 0 - - - testkafka 1 1 1 0 - - - testkafka 5 0 0 0 - - - test 6 3 3 0 - - -Use
CURRENT-OFFSETasbeginOffsetandLOG-END-OFFSETasendOffset. -
Assign the exclusive resource group to this node.
-
In the right-side panel, click Scheduling Configuration.
-
In the Resource Properties section, set Schedule Resource Group to the exclusive resource group you created.
-
-
Click the
 icon to run the node.
icon to run the node. -
View the results in Runtime Log.
What's next
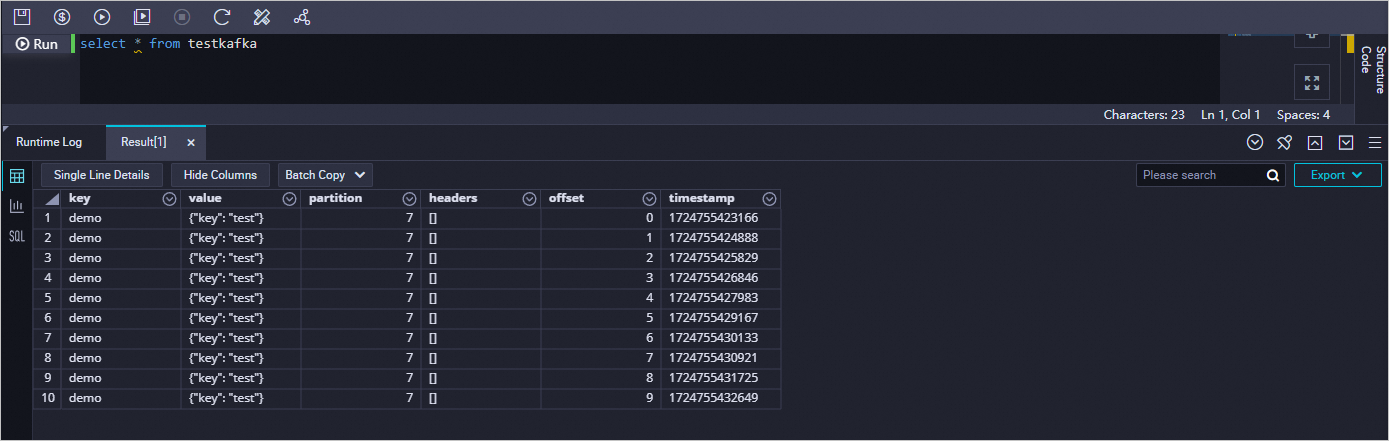
Run a query in Data Studio to confirm the data loaded into MaxCompute.
-
Log on to the DataWorks console.
-
In the left navigation pane, click Workspace to go to the Workspaces page.
-
In the top navigation bar, switch to the target region, locate your workspace, and in the Actions column, click Shortcuts > Data Development to open Data Studio.
-
In the left navigation pane, click the
 icon to open the Ad Hoc Query pane. Click the
icon to open the Ad Hoc Query pane. Click the  icon and choose Create > ODPS SQL.
icon and choose Create > ODPS SQL. -
In the Create Node dialog box, set the Path and Name parameters and click Confirm.
-
Enter the following query, click the
 icon to run it, and check the results in the operational log.
icon to run it, and check the results in the operational log.select * from testkafka