This post features a basic introduction to Machine Learning. This post on Machine Learning will not only help you to understand the latest trends in the Internet industry, but increase your understanding of the technology that plays a major role in many services that make our lives easier.

At first glance, the term machine learning may be confusing. In the computing field, machine refers to a computer. This term is anthropomorphic, indicating it is a technology that enables machines to "learn."
Traditionally, for a computer to perform a task, you give a command, the computer executes the command as per your input. However, this is not how ML works! In ML the computer does not receive an input command, it receives input data. That is to say, in Machine Learning, a computer is made to use data, not execute a task based on a command. Statistical thinking is an important concept that is of great use as you study more on the subject. It is the concept of correlation, rather than causation, an idea that lies in the root of Machine Learning making it practical.
Now, here's a story that illustrates Machine Learning perfectly:
You have probably made an appointment with someone, and then waited for the other person to show up. Not everyone is punctual. So, if you meet a person who is always late, you inevitably waste some time waiting for them. Let’s assume you were going to meet your friend, John.
John’s not very punctual. That time, you were supposed to meet up at the Tech exhibition at 3 p.m. Just as you were walking out of the door to leave, you thought to yourself: “Should I leave right now? If I don’t leave now, I will end up waiting for him for 30 minutes.” Consider a strategy that you can adopt to solve this problem.
There are many approaches to this problem:
In fact, there are other methods more suitable than the three mentioned.
Consider this option:
You think about all your experiences with John and try coming up with the percentage of times he has been late. You use this information to predict the likelihood of him arriving late this time. If this likelihood exceeds some limit you set in your mind, you wait a bit before leaving your house to go to the exhibition.
Assume you have met John five times, and he has been late once. This means that he has arrived on time 80 percent of the time. If your mental cut-off line is 70 percent, then you assume that John will not be late, and you leave the house on time. However, if he has shown up late four out of five times, this gives him a 20 percent likelihood of arriving on time. In this case, you wait a while before leaving your house. This approach is called the empirical method. You make use of all relevant data from the past. Therefore, you can say that your decision is based on data.
The idea of data-based decisions is consistent with the thinking behind Machine Learning. In this thought experiment, you have only considered the attribute of "frequency." However, ML models consider at least two factors, one is the dependent variable (result you want to predict); in the example, this is the decision on whether or not John will arrive late. The other factor is the independent variable, which is used to predict whether or not John will arrive late. If you make time the independent variable, it could be that all the times that John has been late had been on Fridays, while he has never been late on other days of the week.
Therefore, you could establish a model to simulate the probability that John will arrive late based on whether or not it is Friday. The following diagram provides a simple Machine Learning model called a decision tree.
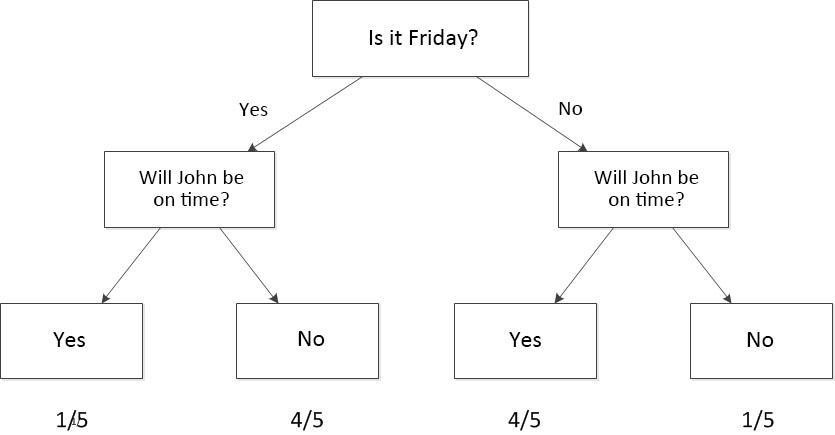
When you consider a single independent variable, the process is quite simple. But what if a second independent variable is added? Going back to the earlier story, let's say that some of the times when John is late, he is driving. Maybe he is a poor driver or there is a lot of traffic. Therefore, this new information can be added to the decision-making process. Now, you can establish a more complex model that includes two independent variables plus one dependent variable.
To make things even more complex, bad weather, such as rain, could play a role in John being late. Thus, you now have three independent variables to consider.
If you want to predict how much time John will be late, you can relate the number of minutes John was late to the amount of rain and other independent variables to create a unified model. The predictions produced by this model give you an idea of how late John will be on any given day. This will help you to plan the actual time to leave your house to meet him. In this situation, a simple decision tree will not be of much help because it can only predict discrete values. However, you can use the linear regression method, which will be discussed in the post Machine Learning Techniques.
At this point, you may decide to hand over the modeling work to a computer, for example, you could input all independent and dependent variables and have the computer generate a model. Then, each time you have an appointment with John, you can ask the computer to look at the current situation and determine if you should leave the house late, and if so, by how many minutes. When the computer executes this type of decision support process, it is implementing a Machine Learning process.
In the Machine Learning method, a computer uses existing data (experiences) to create a certain model (lateness rules). Then, this model predicts the future (whether or not John will arrive late).
Through the analyses, you can see that ML is very similar to normal human thinking. However, it can consider many more situations and execute more complex calculations. In fact, the main purpose of ML is to convert the process by which humans generalize their past experiences into a process where a computer can analyze data to create a model. These computer models approximate the way in which humans solve subtle and complex problems.
We now move on to the definition, scope, methods, and applications of ML.
Broadly speaking, Machine Learning is a method that gives machines learning capabilities, allowing them to implement functions that cannot be achieved through straightforward programming. However, in practice, Machine Learning is a method that uses data to train a model, and then uses the model to make predictions.
Let's look at a housing price example.
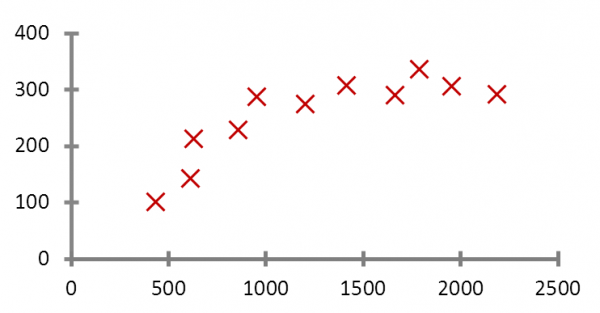
We use various housing prices. You own a house that you want to sell. At what price should you list it? The house’s an area is 100 square meters. So, is the right price $1 million? $1.2 million? Or $1.4 million?
Obviously, you need a rule that links the price to the house’s area. But how do you find such a rule? Do you use the average house price data from the newspaper or online providers? Or do you look at prices of similar sized houses?
What you need is a rational rule that reflects the relationship between area size and price to the greatest extent possible. Because you have investigated the prices of similar houses in the area, you already have a data set. This data set contains area size and price information for houses of all sizes. If you find a rule linking area size and price from this data, then you could find the appropriate price for your house.
In fact, it is quite easy to find such a rule. You just have to draw a straight line that best fits all the points on the graph, with the minimum distance possible from each point to the line.
By finding this straight line, you have the rule that best reflects the relationship between area size and price. This line is defined by the following function:
House price = area * a + b; where a and b are parameters of the line.
After finding these parameters, you can calculate the appropriate price for your house.
Assume that a = 0.75 and b = 50 (in $ millions). In this case, the house price is 100 * 0.75 + 50 = $1.25 million. This result differs from the three options previously listed: $1 million $1.2 million, & $1.4 million. Since this line takes the majority of cases into account, it is, statistically, the most reasonable prediction.
The following are observations made about this model.
You can use the process of finding the best-fit line to look at the entire Machine Learning process. First, you need to save historical data to your computer. Next, process this data using a Machine Learning algorithm. In Machine Learning language, this process is called "training." The result of this training can predict new data. This result is considered a model. The process used to forecast new data is called "prediction." Training and prediction are both processes in Machine Learning, while models are intermediate results. Training produces a model, which in turn guides prediction.
Using the following outline, you can compare the Machine Learning process with human experiential thinking.
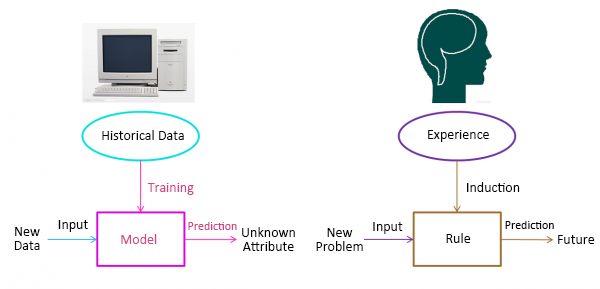
As you grow and live, you accumulate many experiences. You regularly generalize these experiences and come up with "rules" about life. When you encounter an unfamiliar problem or need to speculate about the future, you use those "rules." This way of thinking guides you in your daily life and work.
In Machine Learning, the training and prediction processes correspond with your mental processes of generalization and speculation. This correspondence shows that the concept of Machine Learning is not complex. It is simply a simulation of the learning and growth experienced by all humans. Because the results produced by Machine Learning are not the products of a program, the process does not resemble a cause and effect system. Rather, it uses generalization (or induction) to draw relevant conclusions.
This also brings back the reason for studying history. History can be thought of as the summary of past human experiences. Have you heard the saying, "History is often different, but always surprisingly similar." By studying history, you can find general rules about people and nations and use them to guide your behavior. This is the great value of history.
In the previous section, we discussed the definition of Machine Learning. Now, let's look at its scope.
The scope of ML is similar to pattern recognition, statistical learning, and data mining. At the same time, when combined with technology from other fields, it forms cross-disciplinary disciplines like speech recognition and natural language processing.
Let's discuss some of the fields related to ML as well as look at some of the application scenarios and research scope of ML. This will increase your understanding of subsequent discussions of algorithms and application levels.
The following image depicts some of the disciplines and research areas that involve ML.
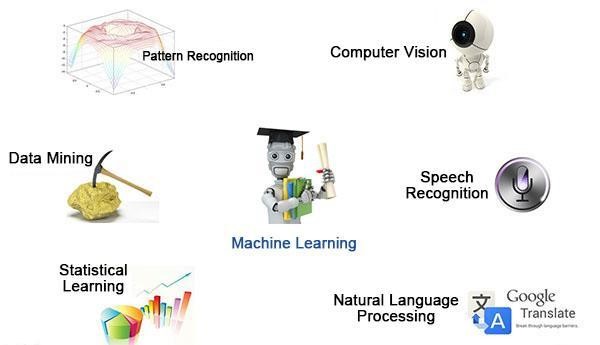
Pattern Recognition = Machine Learning
The main difference between pattern recognition and Machine Learning is that the former concept emerged along with the development of the industrial sector, while the latter stems from computer science. In his book, “Pattern Recognition and Machine Learning,” Christopher M. Bishop says, "Pattern recognition comes from the industrial sector, while machine learning is taken from computer science. However, in practice, they can be seen as two sides of the same field. Over the past decade, they have both developed considerably."
Data Mining = Machine Learning + Databases
Recently, the concept of data mining has become all too familiar. Whenever people talk about data mining, they always boast about its power. For example, it extracts gold from data, or it converts discarded data into value. However, it is not always certain that you would always find gold when you are mining for it. This also applies to data mining. Data mining is simply a way of thinking. You should attempt to mine data to discover knowledge. One must have a deep understanding of the data to find patterns in the data that guide business improvements. Most algorithms used in data mining are Machine Learning algorithms optimized in databases.
Statistical learning is almost synonymous with ML. These two disciplines have a high degree of overlap. Since the majority of Machine Learning methods come from statistics and can be considered statistical methods, the development of statistics promotes Machine Learning. For example, the famous SVM algorithm is derived from statistics. However, the two disciplines differ to a certain degree. Statistical learning practitioners focus on the development and optimization of statistical models and tend to lean toward mathematics. Machine Learning practitioners, however, are more concerned with the ability to solve problems and lean toward practical applications. Therefore, Machine Learning researchers focus on improving the efficiency and accuracy of algorithms running on computers.
Computer Vision = Image Processing + Machine Learning
Image processing technology processes images to convert them into suitable input for Machine Learning models. Machine Learning is responsible for recognizing patterns in the images. There are many applications of computer vision, such as Google Image Recognition, handwritten character recognition, and license plate recognition. The application prospects for this field are promising, and it is a popular avenue of research. As the new field of deep learninghas developed within Machine Learning, it has significantly improved the performance of computer image recognition applications. Thus, the future development prospects of the computer vision field are unlimited.
Speech Recognition = Voice Processing + Machine Learning
Speech recognition is the combination of audio processing technology and Machine Learning. It is rarely used independently. It is combined with natural language processing technology. An application includes Apple's voice assistant, Siri.
Natural Language Processing = Text Processing + Machine Learning
Natural language processing technology is primarily used to enable machines to understand natural human speech. It makes extensive use of compiler theory technologies, such as lexical and syntax analysis. Also, at the level of understanding, they use semantic understanding, ML, and other technology. As it deals with unique symbols created by humans, natural language processing has been a constant avenue of Machine Learning research. According to Baidu Machine Learning expert Yu Kai, "to be blunt, listening, watching, and making sounds are things that even dogs and cats can do, but language is unique to humans." The attempt to use Machine Learning technology to give computers a deep understanding of human language has been a constant focus in industry and academia.
Now, you understand how Machine Learning has extensions and applications in many fields. The development of Machine Learning has promoted the advancement of various intelligent fields to improve our daily life. For information on Machine Learning techniques, look our for the next in the 2nd in the 3 part series, Machine Learning Techniques.
Service Tracing Analysis on Spring Cloud Applications Using Zipkin
Optimizing Performance for Big-data-based Global E-Commerce Systems

2,593 posts | 795 followers
FollowAlibaba EMR - August 19, 2020
Alibaba Clouder - April 28, 2021
Alibaba Clouder - April 28, 2021
Alibaba Clouder - May 11, 2021
Alibaba Clouder - November 4, 2019
Alex - January 22, 2020
2,593 posts | 795 followers
Follow Platform For AI
Platform For AI
A platform that provides enterprise-level data modeling services based on machine learning algorithms to quickly meet your needs for data-driven operations.
Learn More Alibaba Cloud Model Studio
Alibaba Cloud Model Studio
A one-stop generative AI platform to build intelligent applications that understand your business, based on Qwen model series such as Qwen-Max and other popular models
Learn More Epidemic Prediction Solution
Epidemic Prediction Solution
This technology can be used to predict the spread of COVID-19 and help decision makers evaluate the impact of various prevention and control measures on the development of the epidemic.
Learn More Machine Translation
Machine Translation
Relying on Alibaba's leading natural language processing and deep learning technology.
Learn MoreMore Posts by Alibaba Clouder


Raja_KT February 11, 2019 at 9:27 am
Good one. Data prep for Training sets (of data) can be a challenge for cumputing side. Just small amount of data may not solve business cases.