表格存储支持多种方式实现数据表间的数据迁移或同步。可通过通道服务、DataWorks、DataX或命令行工具等方式完成数据表到数据表的同步操作。
前提条件
获取源数据表和目标数据表的实例名称、实例访问地址、地域ID等信息。
为阿里云账号或具有表格存储权限的RAM用户创建AccessKey。
使用SDK同步数据
基于通道服务实现数据表间的数据同步,支持同地域、跨地域以及跨账号的数据同步场景。通过通道服务获取数据变更记录,并将变更实时同步至目标表。以下以Java SDK为例演示同步实现。
运行代码前,请替换代码中源表和目标表的数据表名称、实例名称和实例访问地址,并将AccessKey ID和AccessKey Secret配置为环境变量。
import com.alicloud.openservices.tablestore.*;
import com.alicloud.openservices.tablestore.core.auth.DefaultCredentials;
import com.alicloud.openservices.tablestore.core.auth.ServiceCredentials;
import com.alicloud.openservices.tablestore.model.*;
import com.alicloud.openservices.tablestore.model.tunnel.*;
import com.alicloud.openservices.tablestore.tunnel.worker.IChannelProcessor;
import com.alicloud.openservices.tablestore.tunnel.worker.ProcessRecordsInput;
import com.alicloud.openservices.tablestore.tunnel.worker.TunnelWorker;
import com.alicloud.openservices.tablestore.tunnel.worker.TunnelWorkerConfig;
import com.alicloud.openservices.tablestore.writer.RowWriteResult;
import com.alicloud.openservices.tablestore.writer.WriterConfig;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.atomic.AtomicLong;
public class TableSynchronization {
// 源表配置项:表名称、实例名称、实例访问地址、AccessKey ID、AccessKey Secret
final static String sourceTableName = "sourceTableName";
final static String sourceInstanceName = "sourceInstanceName";
final static String sourceEndpoint = "sourceEndpoint";
final static String sourceAccessKeyId = System.getenv("SOURCE_TABLESTORE_ACCESS_KEY_ID");
final static String sourceKeySecret = System.getenv("SOURCE_TABLESTORE_ACCESS_KEY_SECRET");
// 目标表配置项:表名称、实例名称、实例访问地址、AccessKey ID、AccessKey Secret
final static String targetTableName = "targetTableName";
final static String targetInstanceName = "targetInstanceName";
final static String targetEndpoint = "targetEndpoint";
final static String targetAccessKeyId = System.getenv("TARGET_TABLESTORE_ACCESS_KEY_ID");
final static String targetKeySecret = System.getenv("TARGET_TABLESTORE_ACCESS_KEY_SECRET");
// 通道名称
static String tunnelName = "source_table_tunnel";
// TablestoreWriter:高并发数据写入工具
static TableStoreWriter tableStoreWriter;
// 成功和失败行数统计
static AtomicLong succeedRows = new AtomicLong();
static AtomicLong failedRows = new AtomicLong();
public static void main(String[] args) {
// 创建目标表
createTargetTable();
System.out.println("Create target table Done.");
// 初始化 TunnelClient
TunnelClient tunnelClient = new TunnelClient(sourceEndpoint, sourceAccessKeyId, sourceKeySecret, sourceInstanceName);
// 创建数据通道
String tunnelId = createTunnel(tunnelClient);
System.out.println("Create tunnel Done.");
// 初始化 TablestoreWriter
tableStoreWriter = createTablesStoreWriter();
// 通过数据通道同步数据
TunnelWorkerConfig config = new TunnelWorkerConfig(new SimpleProcessor());
TunnelWorker worker = new TunnelWorker(tunnelId, tunnelClient, config);
try {
System.out.println("Connect tunnel and working ...");
worker.connectAndWorking();
// 监听通道状态,通道状态从全量同步变成增量同步时,表示数据同步完成
while (true) {
if (tunnelClient.describeTunnel(new DescribeTunnelRequest(sourceTableName, tunnelName)).getTunnelInfo().getStage().equals(TunnelStage.ProcessStream)) {
break;
}
Thread.sleep(5000);
}
// 同步结果
System.out.println("Data Synchronization Completed.");
System.out.println("* Succeed Rows Count: " + succeedRows.get());
System.out.println("* Failed Rows Count: " + failedRows.get());
// 删除通道
tunnelClient.deleteTunnel(new DeleteTunnelRequest(sourceTableName, tunnelName));
// 关闭资源
worker.shutdown();
config.shutdown();
tunnelClient.shutdown();
tableStoreWriter.close();
}catch(Exception e){
e.printStackTrace();
worker.shutdown();
config.shutdown();
tunnelClient.shutdown();
tableStoreWriter.close();
}
}
private static void createTargetTable() throws ClientException {
// 查询源表信息
SyncClient sourceClient = new SyncClient(sourceEndpoint, sourceAccessKeyId, sourceKeySecret, sourceInstanceName);
DescribeTableResponse response = sourceClient.describeTable(new DescribeTableRequest(sourceTableName));
// 创建目标表
SyncClient targetClient = new SyncClient(targetEndpoint, targetAccessKeyId, targetKeySecret, targetInstanceName);
TableMeta tableMeta = new TableMeta(targetTableName);
response.getTableMeta().getPrimaryKeyList().forEach(
item -> tableMeta.addPrimaryKeyColumn(new PrimaryKeySchema(item.getName(), item.getType()))
);
TableOptions tableOptions = new TableOptions(-1, 1);
CreateTableRequest request = new CreateTableRequest(tableMeta, tableOptions);
targetClient.createTable(request);
// 关闭资源
sourceClient.shutdown();
targetClient.shutdown();
}
private static String createTunnel(TunnelClient client) {
// 创建数据通道,返回通道 ID
CreateTunnelRequest request = new CreateTunnelRequest(sourceTableName, tunnelName, TunnelType.BaseAndStream);
CreateTunnelResponse response = client.createTunnel(request);
return response.getTunnelId();
}
private static class SimpleProcessor implements IChannelProcessor {
@Override
public void process(ProcessRecordsInput input) {
if(input.getRecords().isEmpty())
return;
System.out.print("* Begin consume " + input.getRecords().size() + " records ... ");
for (StreamRecord record : input.getRecords()) {
switch (record.getRecordType()) {
// 写入行数据
case PUT:
RowPutChange putChange = new RowPutChange(targetTableName, record.getPrimaryKey());
putChange.addColumns(getColumnsFromRecord(record));
tableStoreWriter.addRowChange(putChange);
break;
// 更新行数据
case UPDATE:
RowUpdateChange updateChange = new RowUpdateChange(targetTableName, record.getPrimaryKey());
for (RecordColumn column : record.getColumns()) {
switch (column.getColumnType()) {
// 新增属性列
case PUT:
updateChange.put(column.getColumn().getName(), column.getColumn().getValue(), System.currentTimeMillis());
break;
// 删除属性列版本
case DELETE_ONE_VERSION:
updateChange.deleteColumn(column.getColumn().getName(),
column.getColumn().getTimestamp());
break;
// 删除属性列
case DELETE_ALL_VERSION:
updateChange.deleteColumns(column.getColumn().getName());
break;
default:
break;
}
}
tableStoreWriter.addRowChange(updateChange);
break;
// 删除行数据
case DELETE:
RowDeleteChange deleteChange = new RowDeleteChange(targetTableName, record.getPrimaryKey());
tableStoreWriter.addRowChange(deleteChange);
break;
}
}
// 发送缓冲区数据
tableStoreWriter.flush();
System.out.println("Done");
}
@Override
public void shutdown() {
}
}
public static List<Column> getColumnsFromRecord(StreamRecord record) {
List<Column> retColumns = new ArrayList<>();
for (RecordColumn recordColumn : record.getColumns()) {
// 将数据版本号替换为当前时间戳,防止超过最大版本偏差
Column column = new Column(recordColumn.getColumn().getName(), recordColumn.getColumn().getValue(), System.currentTimeMillis());
retColumns.add(column);
}
return retColumns;
}
private static TableStoreWriter createTablesStoreWriter() {
WriterConfig config = new WriterConfig();
// 行级别回调,统计成功和失败行数,打印同步失败的数据行
TableStoreCallback<RowChange, RowWriteResult> resultCallback = new TableStoreCallback<RowChange, RowWriteResult>() {
@Override
public void onCompleted(RowChange rowChange, RowWriteResult rowWriteResult) {
succeedRows.incrementAndGet();
}
@Override
public void onFailed(RowChange rowChange, Exception exception) {
failedRows.incrementAndGet();
System.out.println("* Failed Rows: " + rowChange.getTableName() + " | " + rowChange.getPrimaryKey() + " | " + exception.getMessage());
}
};
ServiceCredentials credentials = new DefaultCredentials(targetAccessKeyId, targetKeySecret);
return new DefaultTableStoreWriter(targetEndpoint, credentials, targetInstanceName,
targetTableName, config, resultCallback);
}
}使用DataWorks同步数据
DataWorks提供可视化的数据集成服务,支持通过图形界面配置表格存储数据表间的同步任务。除DataWorks外,还可使用DataX等工具实现表格存储数据表间的数据同步。
步骤一:准备工作
创建目标数据表,确保其主键结构(包括数据类型及顺序)与源表完全一致。
开通DataWorks服务,并在源表或目标表所在地域创建工作空间。
创建Serverless资源组并绑定到工作空间。有关计费信息,请参见Serverless资源组计费。
如果源表和目标表位于不同地域,需创建VPC对等连接以实现跨地域网络连通。
以下以DataWorks工作空间和源表实例均位于华东1(杭州)地域,目标表位于华东2(上海)地域的场景为例进行说明。
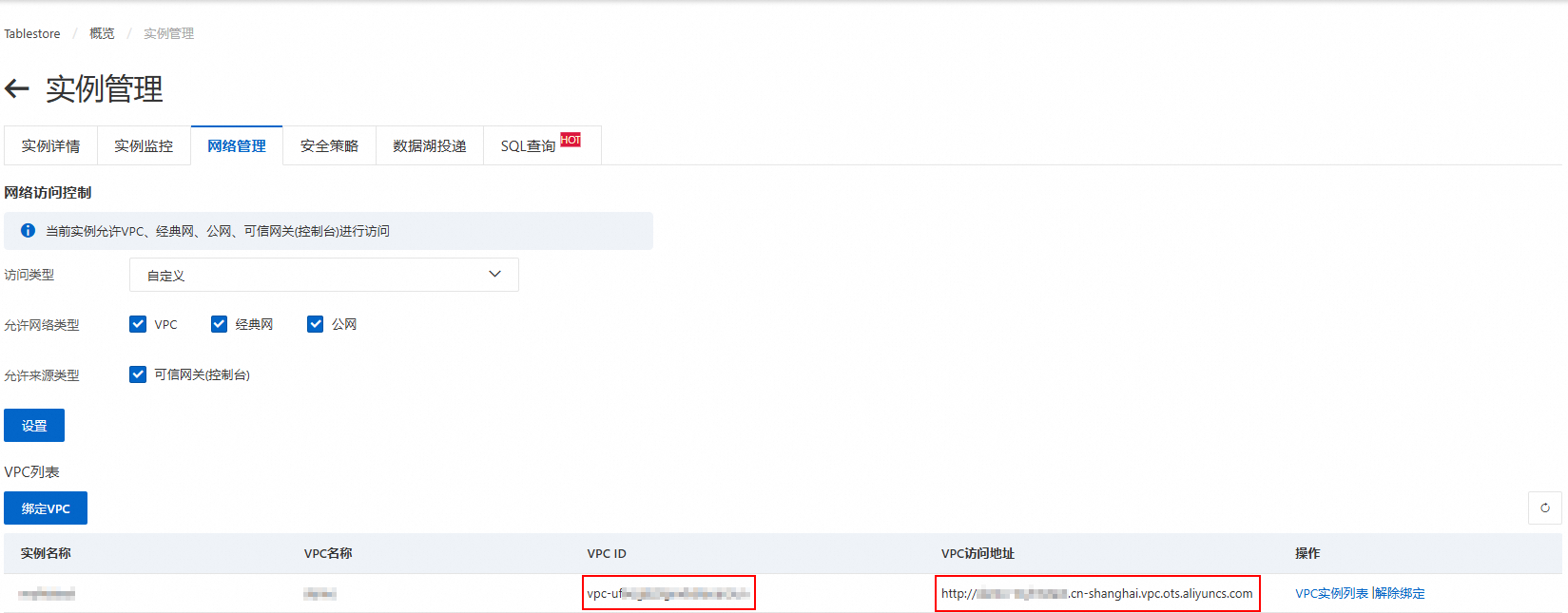
为Tablestore实例绑定VPC。
登录表格存储控制台,在页面上方选择目标表所在地域。
单击实例别名进入实例管理页面。
切换到网络管理页签,单击绑定VPC,选择VPC和交换机并填写VPC名称,然后单击确定。
等待VPC绑定完成,页面将自动刷新,可在VPC列表查看绑定的VPC ID和VPC访问地址。
说明在DataWorks控制台添加Tablestore数据源时,需使用该VPC访问地址。
获取DataWorks工作空间资源组的VPC信息。
登录DataWorks控制台,在页面上方选择工作空间所在地域,然后单击左侧工作空间菜单,进入工作空间列表页面。
单击工作空间名称进入空间详情页面,单击左侧资源组菜单,查看工作空间绑定的资源组列表。
在目标资源组右侧单击网络设置,在资源调度 & 数据集成区域查看绑定的专有网络,即VPC ID。
创建VPC对等连接并配置路由。
登录专有网络VPC控制台,在页面左侧单击VPC对等连接菜单,然后单击创建对等连接。
在创建对等连接页面,输入对等连接名称,选择发起端VPC实例、接收端账号类型、接收端地域和接收端VPC实例,单击确定。
在VPC对等连接页面,找到已创建的VPC对等连接,分别在发起端和接收端列单击配置路由条目。
目标网段需填写对端VPC的网段地址。即在发起端配置路由条目时,填写接收端的网段地址;在接收端配置路由条目时,填写发起端的网段地址。
步骤二:新增表格存储数据源
分别为源数据表和目标数据表所在的实例添加表格存储数据源。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据集成。
在左侧导航栏,单击数据源。
在数据源列表页面,单击新增数据源。
在新增数据源对话框,搜索并选择数据源类型为Tablestore。
在新增OTS数据源对话框,根据下表配置数据源参数。
参数
说明
数据源名称
数据源名称必须以字母、数字、下划线(_)组合,且不能以数字和下划线(_)开头。
数据源描述
对数据源进行简单描述,不得超过80个字符。
地域
选择Tablestore实例所属地域。
Table Store实例名称
Tablestore实例的名称。
Endpoint
Tablestore实例的服务地址,推荐使用VPC地址。
AccessKey ID
阿里云账号或者RAM用户的AccessKey ID和AccessKey Secret。
AccessKey Secret
测试资源组连通性。
创建数据源时,需要测试资源组的连通性,确保同步任务使用的资源组能够与数据源正常连通,否则将无法正常执行数据同步任务。
在连接配置区域,单击相应资源组连通状态列的测试连通性。
测试连通性通过后,连通状态显示可连通,单击完成。可在数据源列表中查看新建的数据源。
如果测试连通性结果为无法通过,可使用连通性诊断工具自助解决。
步骤三:配置和运行同步任务
新建任务节点
进入数据开发页面。
登录DataWorks控制台。
在页面上方,选择资源组和地域。
在左侧导航栏,单击。
选择对应工作空间后单击进入Data Studio。
在Data Studio控制台的数据开发页面,单击项目目录右侧的
 图标,然后选择。
图标,然后选择。在新建节点对话框,选择路径,数据来源和数据去向都选择Tablestore,填写名称,然后单击确认。
配置同步任务
在项目目录下,单击打开新建的离线同步任务节点,通过向导模式或脚本模式配置同步任务。
向导模式(默认)
配置以下内容:
数据源:选择来源数据源和去向数据源。
运行资源:选择资源组,选择后会自动检测数据源连通性。
数据来源:
表:下拉选择来源数据表。
主键区间分布(起始):数据读取的起始主键,格式为JSON数组,
inf_min表示无限小。当主键包含1个
int类型的主键列id和1个string类型的主键列name时,示例配置如下:指定主键范围
全量数据
[ { "type": "int", "value": "000" }, { "type": "string", "value": "aaa" } ][ { "type": "inf_min" }, { "type": "inf_min" } ]主键区间分布(结束):数据读取的结束主键,格式为JSON数组,
inf_max表示无限大。当主键包含1个
int类型的主键列id和1个string类型的主键列name时,示例配置如下:指定主键范围
全量数据
[ { "type": "int", "value": "999" }, { "type": "string", "value": "zzz" } ][ { "type": "inf_max" }, { "type": "inf_max" } ]切分配置信息:自定义切分配置信息,格式为JSON数组,普通情况下不建议配置(设置为
[])。当Tablestore数据存储发生热点,且使用Tablestore Reader自动切分的策略不能生效时,建议使用自定义的切分规则。切分指定的是在主键起始和结束区间内的切分点,仅配置切分键,无需指定全部的主键。
数据去向:
表:下拉选择去向数据表。
主键信息:去向数据表的主键信息,格式为JSON数组。
当主键包含1个
int类型的主键列id和1个string类型的主键列name时,示例配置如下:[ { "name": "id", "type": "int" }, { "name": "name", "type": "string" } ]写入模式:数据写入表格存储的模式,支持以下两种模式:
PutRow:写入行数据。如果目标行数据不存在,则新增一行。如果目标行数据已存在,则覆盖原有行。
UpdateRow:更新行数据。如果该行不存在,则新增一行。如果该行存在,则根据请求的内容在这一行中新增、修改或者删除指定列的值。
去向字段映射:配置来源数据表到去向数据表的字段映射,一行表示一个字段,格式为JSON。
来源字段:需包含来源数据表的主键信息。
当主键包含1个
int类型的主键列id和1个string类型的主键列name,属性列包含1个int类型的字段age时,示例配置如下:{"name":"id","type":"int"} {"name":"name","type":"string"} {"name":"age","type":"int"}目标字段:无需包含去向数据表的主键信息。
当主键包含1个
int类型的主键列id和1个string类型的主键列name,属性列包含1个int类型的字段age时,示例配置如下:{"name":"age","type":"int"}
配置完成后,单击页面上方的保存。
脚本模式
单击页面上方的脚本模式,在切换后的页面中编辑脚本。
以下以主键包含1个int类型的主键列id和1个string类型的主键列name,属性列包含1个int类型的字段age时的配置为例。配置时请替换示例脚本内的数据源datasource和表名称table。
全量数据
{
"type": "job",
"version": "2.0",
"steps": [
{
"stepType": "ots",
"parameter": {
"datasource": "source_data",
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
},
{
"name": "age",
"type": "int"
}
],
"range": {
"begin": [
{
"type": "inf_min"
},
{
"type": "inf_min"
}
],
"end": [
{
"type": "inf_max"
},
{
"type": "inf_max"
}
],
"split": []
},
"table": "source_table",
"newVersion": "true"
},
"name": "Reader",
"category": "reader"
},
{
"stepType": "ots",
"parameter": {
"datasource": "target_data",
"column": [
{
"name": "age",
"type": "int"
}
],
"writeMode": "UpdateRow",
"table": "target_table",
"newVersion": "true",
"primaryKey": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
]
},
"name": "Writer",
"category": "writer"
}
],
"setting": {
"errorLimit": {
"record": "0"
},
"speed": {
"concurrent": 2,
"throttle": false
}
},
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
}
}指定主键范围
{
"type": "job",
"version": "2.0",
"steps": [
{
"stepType": "ots",
"parameter": {
"datasource": "source_data",
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
},
{
"name": "age",
"type": "int"
}
],
"range": {
"begin": [
{
"type": "int",
"value": "000"
},
{
"type": "string",
"value": "aaa"
}
],
"end": [
{
"type": "int",
"value": "999"
},
{
"type": "string",
"value": "zzz"
}
],
"split": []
},
"table": "source_table",
"newVersion": "true"
},
"name": "Reader",
"category": "reader"
},
{
"stepType": "ots",
"parameter": {
"datasource": "target_data",
"column": [
{
"name": "age",
"type": "int"
}
],
"writeMode": "UpdateRow",
"table": "target_table",
"newVersion": "true",
"primaryKey": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
]
},
"name": "Writer",
"category": "writer"
}
],
"setting": {
"errorLimit": {
"record": "0"
},
"speed": {
"concurrent": 2,
"throttle": false
}
},
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
}
}脚本编辑完成后,单击页面上方的保存。
运行同步任务
单击页面上方的运行,开始同步任务,首次运行时需确认调试配置。
步骤四:查看同步结果
运行同步任务后,可通过日志查看任务的执行状态,并在表格存储控制台查看目标数据表的同步结果。
在页面下方查看任务运行状态和结果,出现以下信息时表示同步任务运行成功。
2025-11-18 11:16:23 INFO Shell run successfully! 2025-11-18 11:16:23 INFO Current task status: FINISH 2025-11-18 11:16:23 INFO Cost time is: 77.208s查看目标数据表的数据。
前往表格存储控制台,在页面上方,选择资源组和地域。
单击实例别名,在数据表列表单击目标数据表。
单击数据管理,查看目标数据表的数据。
使用命令行工具同步数据
使用命令行工具进行数据同步时,需要手动将源表的数据导出为本地JSON文件,随后再将其导入到目标表。此方法仅适用于少量数据的迁移场景,大规模数据迁移不建议采用此方法。
步骤一:准备工作
步骤二:导出源表数据
启动命令行工具,通过config命令配置源表所在实例的接入信息。更多信息,请参见启动并配置接入信息。
执行前请使用源表所在的实例访问地址、实例名称、AccessKey ID、AccessKey Secret替换命令中的endpoint、instance、id、key。
config --endpoint https://myinstance.cn-hangzhou.ots.aliyuncs.com --instance myinstance --id NTSVL******************** --key 7NR2****************************************导出数据。
执行
use命令以使用源表。以source_table为例。use --wc -t source_table导出源表中的数据到本地JSON文件中。具体操作,请参见导出数据。
scan -o /tmp/sourceData.json
步骤三:导入目标表数据
通过config命令配置目标表所在实例的接入信息。
执行前请使用目标表所在的实例访问地址、实例名称、AccessKey ID、AccessKey Secret替换命令中的endpoint、instance、id、key。
config --endpoint https://myinstance.cn-hangzhou.ots.aliyuncs.com --instance myinstance --id NTSVL******************** --key 7NR2****************************************导入数据。
执行
use命令以使用目标表。以target_table为例。use --wc -t target_table导入本地JSON文件中的数据到目标表中。具体操作,请参见导入数据。
import -i /tmp/sourceData.json