本文主要介绍工作流的搭配和节点配置操作。
智能工作流 = 把多个节点像乐高一样拼起来,自动跑通整个流程
人脸提取+视频摘要(OTT)
流程:

适用场景:需要快速提取视频中人脸信息,并生成视频摘要(如影视内容中明星片段剪辑、新闻人物集锦等)。
优势:一键完成“人脸定位+内容摘要”,减少手动筛选成本。
抽帧检测(Custom)
流程:

适用场景:需要对视频进行逐帧分析(如广告帧检测、画面合规性检查、关键帧提取等)。
优势:专注“帧级内容检测”,满足精细化画面分析需求。
提取语音+ASR + 文本内容提取 + 抽帧检测(Custom)
流程:

适用场景:需要同时处理“音频转文字、文本信息提取、画面帧检测”的全流程(如直播回放的内容合规审查、长视频的多维度分析等)。
优势:覆盖“音频→文本→画面”的全链路分析,避免多工具切换。
自定义工作流
自定义工作流允许用户根据业务需求,自由组合多个节点(人脸识别、提取语音+ASR、文本内容提取、视频摘要(OTT)、抽帧检测(Custom))。
具体节点能力,请参见:产品能力说明
提取语音+ASR 、文本内容提取 、抽帧检测(Custom)三个节点搭配使用
「提取语音+ASR」为「文本内容提取」节点的输入项,建议一起使用,否则将导致结果失败!
推荐配置组合(典型场景参考)
方案一:全链路串行深度分析
流程:

适用场景: 采用单线串行模式。适用于对视频内容进行标准化的、按部就班的深度结构化处理,确保每个环节的数据都能被下一个环节利用。
优势: 流程线性清晰,便于排查问题;能够在一个任务中完成从画面到声音再到语义的全维度解析。
方案二:画面与语音串行处理
流程:

适用场景: 采用单线串行模式。侧重于内容语义分析,不需要识别具体人物,但需要保留关键帧画面和语音转文字内容的场景(如普通会议记录、Vlog内容分析)。
优势: 相比方案一减少了人脸计算资源消耗,处理速度更快,专注于“画面存档+语音语义”。
方案三:音视频并行独立处理
流程:
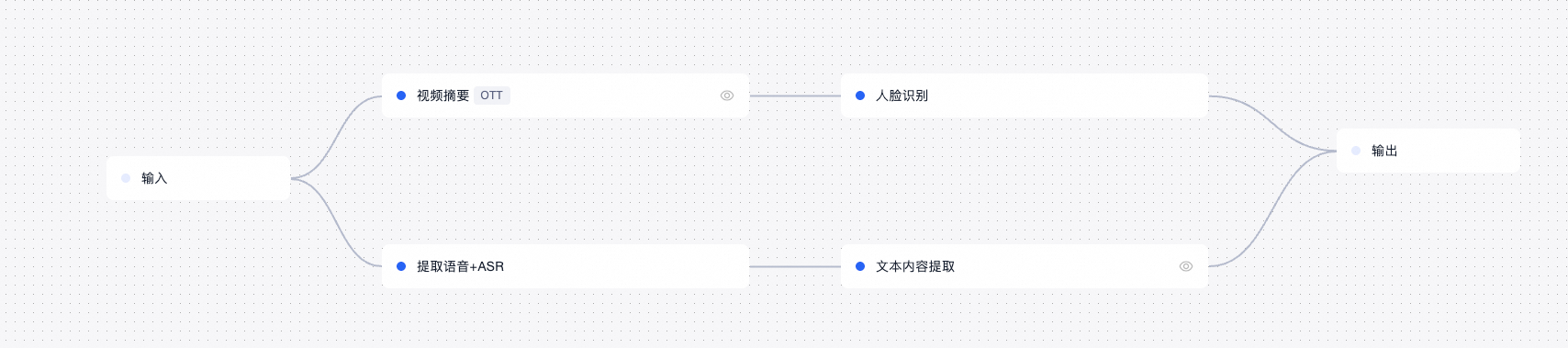
适用场景: 采用双线并联模式。绝大多数媒资入库场景。既需要知道视频里是谁(人脸),也需要知道说了什么(文本提取),且两者互不干扰。
优势: 并行处理效率极高,互不阻塞;如果某一路(如人脸识别)失败,不会影响另一路(如文本提取)的结果产出。
方案四:画面检测与人物识别并行处理
流程:

适用场景: 适用于需要快速抓取人物信息,同时对视频内容进行抽帧和语音分析的场景。
优势: 灵活度高,将“内容分析”和“人物识别”解耦,适合对处理时效性要求较高的业务。
方案五:抽帧驱动的多模态分析
流程:

适用场景: 侧重于画面信息挖掘(如广告画面文字提取、PPT画面识别),同时兼顾语音转写。
优势: 最大化利用画面信息,适合“画面即内容”的视频类型(如教程、广告)。
方案六:复杂依赖交叉处理
流程:

适用场景: 需要进行多模态融合分析的高级场景,例如“画面出现某人且说了某话”的联合检索。
优势: 数据维度最全,能够捕捉跨模态的关联信息。