Agentic SOC功能,支持从 Kafka、Amazon S3、阿里云 OSS、三方服务API 等多种渠道集中采集日志,帮助建立统一的日志分析和安全运营中心,实现跨云环境的统一安全管理。
工作流程

方案选型
在开始配置前,请根据数据源类型、成本考量和对数据实时性的要求,选择最合适的日志导入渠道。
|
导入渠道 |
适用场景 |
功能特点 |
|
Kafka |
|
|
|
S3 (或兼容协议的对象存储) |
|
|
|
OSS (阿里云对象存储) |
日志数据已存储在阿里云 OSS。 |
与阿里云生态集成度高,配置便捷。 |
|
API |
|
|
投递日志到中间渠道
Agentic SOC导入功能需通过 Kafka、S3 、OSS、三方服务API等渠道获取数据。因此需要先将源端的日志数据投递到所选的中间渠道。
-
投递方式示例:
-
OSS:将日志数据存储至阿里云 OSS 存储空间(Bucket)中。更多说明,请参见OSS快速入门。
-
华为云:通过华为云日志服务(LTS)的日志转储功能,将数据转存至Kafka或OBS。更多说明,请参见导入华为云日志数据。
-
腾讯云:通过腾讯云日志服务 (CLS)的日志转储功能,将数据转存至Kafka或COS。更多说明,请参见导入腾讯云日志数据。
-
Azure:利用Azure Event Hub(事件中心)对Apache Kafka协议的兼容性,将事件中心视为一个Kafka服务,Agentic SOC从中获取日志数据。更多说明,请参见导入Azure日志数据。
-
-
保存访问信息:请妥善保管访问凭证(如 AccessKey、密码)和接入点信息(如 Endpoint、Bucket名称)。
授权云安全中心访问三方服务
使用三方数据渠道,需授权Agentic SOC访问其资源的权限,以允许 Agentic SOC 读取其中的日志数据。
Kafka、S3(对象存储)、API
-
访问云安全中心控制台-系统设置-功能设置,在页面左侧顶部,选择需防护资产所在的区域:中国内地或非中国内地。
-
在多云配置管理页签,选择多云资产后,单击新增授权,下拉选择IDC。在弹出的面板中进行如下配置:
说明-
具体的配置项的数值(如访问地址等)可参考各云厂商的官方说明文档。
-
当前版本中,配置通用的 Kafka 、 S3 兼容存储(如 AWS S3、腾讯云 COS、华为云 OBS)或 API 时,请选择 IDC 选项。此为界面归类方式,不影响实际功能。
Kafka
-
厂商:选择 Apache。
-
产品:选择 Kafka。
-
接入点:Kafka公网访问地址。
说明Event Hub访问地址为:
<YOUR-NAMESPACE>.servicebus.windows.net:9093。 -
用户名/密码:Kafka的用户名/密码。
说明Event Hub对应Kafka用户名默认为
$ConnectionString,密码为主连接字符串。 -
通信协议:Kafka配置中的security.protocol,支持设置plaintext(默认)、sasl_plaintext、sasl_ssl、ssl等。
-
SASL 认证机制:Kafka 配置中的 sasl.mechanism,支持设置:plain、SCRAM-SHA-256、SCRAM-SHA-512等。
S3
-
厂商:选择 AWS-S3。
-
产品:选择S3 。
-
接入点:对象存储的访问地址。
-
Access Key Id/Secret Access Key:输入访问S3的访问密钥。
API
-
厂商:选择 Salesforce / Lark / Akamai 等。
-
产品:选择厂商已经集成的 API 。
-
Salesforce API :Salesforce Rest API 。
-
Lark API :Lark Rest API 。
-
Akamai API :Akamai Rest API 。
-
-
接入点: 输入厂商 API 服务提供方的访问地址。
-
Salesforce 的接入点获取:登录 Salesforce ,点击右上角 Setup Menu ,在左侧 Quick Find 中搜索 My Domain ,点击搜索结果中的My Domain 查看详情,Current My Domain URL 就是接入点信息。
-
Lark 的接入点获取:固定值 https://open.larksuite.com 就是接入点信息。
-
Akamai 的接入点获取:登录 Akamai 控制台,在左上角菜单栏搜索 Identity & Access ,在右侧搜索结果页中点击进入 Identity & Access ,查找 API 接口对应的应用账户信息,点击进入用户详情页面,Host 就是接入点信息。
-
-
Access Key Id/Secret Access Key:输入调用 API 的访问密钥。
-
Salesforce 的 Access Key Id/Secret Access Key 获取 :登录 Salesforce ,点击右上角 Setup Menu ,在左侧 Quick Find 中搜索 App Manager ,点击搜索结果中的 App Manager 查看 App 列表,从右侧列表中查找 API 接口对应的应用,应用 App Type 类型一般为Connected ,点击对应应用右侧的按钮展开下拉框,点击 View 查看详情信息,进入后寻找 Consumer Key(对应 Access Key Id )和 Consumer Secret(对应 Secret Access Key )信息。
-
Lark 的 Access Key Id/Secret Access Key 获取 :登录 Lark 开发者 APP 后台,找到 API 接口对应的应用,点击进入应用详情,点击左侧基础信息菜单中的凭据与基础信息菜单,在详情页寻找 App ID(对应 Access Key Id )和 App Secret(对应 Secret Access Key )信息,注意 App ID 需要有调用 API 权限,可能要联系 Lark 的客户经理申请。
-
Akamai 的 Access Key Id/Secret Access Key 获取 :登录 Akamai 控制台,在左上角菜单栏搜索 Identity & Access ,在右侧搜索结果页中点击进入 Identity & Access ,查找 API 接口对应的应用账户信息,点击进去用户详情页面,找 Client Token(对应 Access Key Id )和 Client Secret(对应 Secret Access Key )信息,注意 Client Secret 仅在 Create credential 时才会显示,需要在创建完后记录下来。
-
-
Access Token :输入调用 API 的 Access Token,目前仅选择厂商 Akamai 时才会需要输入。
-
Akamai 的 Access Token 获取 :登录 Akamai 控制台,在左上角菜单栏搜索 Identity & Access ,在搜索结果页中点击进入 Identity & Access ,查找 API 接口的应用账户信息,点击进入用户详情页面,寻找 Access Token 信息。
-
-
设备名称:标识设备的唯一性的名称。
-
-
配置同步策略
AK服务状态检查:设置云安全中心自动检查访问密钥有效性的时间间隔。可选“关闭”,表示不进行检测。
OSS
-
访问云资源访问授权页面,单击确认授权,授予系统角色访问OSS资源的权限。
-
若为RAM用户,还需配置以下权限。具体操作,请参见创建自定义权限策略和管理RAM用户的权限。
{ "Statement": [ { "Effect": "Allow", "Action": ["ram:PassRole", "ram:GetRole"], "Resource": "acs:ram:*:*:role/aliyunlogimportossrole" }, { "Effect": "Allow", "Action": "oss:GetBucketWebsite", "Resource": "*" }, { "Effect": "Allow", "Action": "oss:ListBuckets", "Resource": "*" } ], "Version": "1" }
创建数据导入任务
-
创建数据源
为日志数据创建一个专属Agentic SOC 数据源,若已创建请跳过此步骤。
-
访问云安全中心控制台-Agentic SOC-管理-接入设置,在页面左侧顶部,选择需防护资产所在的区域:中国内地或非中国内地。
-
在数据源页签,创建接收日志的数据源。具体操作请参见创建数据源:日志未接入日志服务(SLS)。
-
源数据源类型:可选择Agentic SOC专属数据采集通道(推荐)或用户侧日志服务。
-
接入实例:建议新建日志库(Logstore),进行数据隔离。
-
-
-
在数据导入页签,单击新增数据导入。在弹出的面板中根据数据源类型进行如下配置:
说明具体的配置项的数值可参考各云厂商的官方说明文档。
Kafka
-
终端节点:选择授权云安全中心访问三方服务时填写的Kafka公网访问地址。
-
Topics:选择Kafka中存储日志的Topic。
说明Event Hub名称即为Kafka的topic。
-
值类型:日志存储格式,常见的关系如下:
三方存储格式
值类型
JSON格式
json
原始日志格式
text
S3
-
终端节点:S3存储桶访问地址(Endpoint)。
-
OBS桶(Bucket):S3存储桶ID。
-
文件路径前缀过滤:通过文件路径前缀过滤S3文件,用于准确定位待导入的文件。例如待导入的文件都在csv/目录下,则可以指定前缀为csv/。
警告强烈建议设置此参数。如果不设置,系统将遍历整个 S3 Bucket。当 Bucket 内文件数量巨大时,全量遍历会严重影响导入效率。
-
文件路径正则过滤:通过正则表达式筛选文件,用于准确定位待导入的文件。默认为空,表示不过滤。例如S3文件为
testdata/csv/bill.csv,可以设置正则表达式为(testdata/csv/)(.*)。说明-
推荐与文件路径前缀过滤一起设置,提高效率。此配置与文件路径前缀过滤之前为“且(and)”的关系。
-
调整正则表达式的方法,请参见如何调试正则表达式。
-
-
数据格式:文件的解析格式。
-
CSV:分隔符分割的文本文件,支持指定文件中的首行为字段名称或手动指定字段名称。除字段名称外的每一行都会被解析为日志字段的值。
-
JSON:逐行读取S3文件,将每一行看作一个JSON对象进行解析。解析后,JSON对象中的各个字段对应为日志中的各个字段。
-
单行文本:将S3文件中的每一行解析为一条日志。
-
跨行文本:多行模式,支持指定首行或者尾行的正则表达式解析日志。
若选择为CSV或跨行文本时,需额外设置相关参数,具体说明如下。
CSV
参数
说明
分隔符
设置日志的分隔符,默认值为半角逗号(,)。
引号
CSV字符串所使用的引号字符。
转义符
配置日志的转义符,默认值为反斜线(\)。
日志最大跨行数
当一条日志跨多行时,需要指定最大行数,默认值为1。
首行作为字段名称
打开开关后,将使用CSV文件中的首行作为字段名称。例如提取以下CSV数据中的首行为日志字段的名称。
remote_addr,remote_user,time_local,request_time,request_length xxx5,-,11/Dec/2020:15:31:06,0,000,133,3650,404,GET xxx5,-,11/Dec/2020:15:32:06,0,000,133,3650,404,GET xxx5,-,11/Dec/2020:15:34:10,0,000,133,3650,404,GET跳过行数
指定跳过的日志行数。例如设置为1,则表示从CSV文件中的第2行开始采集日志。
跨行文本
参数
说明
正则匹配位置
设置正则表达式匹配的位置,具体说明如下:
-
首行正则:使用正则表达式匹配一条日志的行首,未匹配部分为该条日志的一部分,直到达到最大行数。
-
尾行正则:使用正则表达式匹配一条日志的行尾,未匹配部分为下一条日志的一部分,直到达到最大行数。
正则表达式
根据日志内容,设置正确的正则表达式。调整正则表达式的方法,请参见如何调试正则表达式。
最大行数
一条日志最大的行数。
-
-
编码格式:待导入的S3文件的编码格式。支持GBK、UTF-8。
-
压缩格式:根据设置S3数据压缩格式,由系统自动检测。
-
文件修改时间过滤:从任务启动时刻回溯30分钟作为起始时间,导入此后修改的所有文件(含未来新增文件)。
-
检查新文件周期:用于设置导入任务定期扫描新文件的时间间隔,任务将按此时间间隔自动扫描并导入新增的文件。
OSS
重要目前仅支持导入5 GB以内的OSS文件,压缩文件大小按照压缩后的大小计算。
-
OSS区域:OSS数据存储区域。
说明跨区域访问会产生公网流量费用,此部分费用由OSS服务收取,具体说明请参见费用说明。
-
Bucket:待导入的OSS文件所在的Bucket。
-
文件路径前缀过滤:通过正则表达式筛选文件,用于准确定位待导入的文件。例如待导入的文件都在csv/目录下,则可以指定前缀为csv/。
警告建议设置此参数,如果不设置,系统遍历整个OSS Bucket。若当文件数量巨大时,遍历整个Bucket会影响导入效率并产生不必要的费用。
-
文件路径正则过滤:通过正则表达式筛选文件,用于准确定位待导入的文件。默认为空,表示不过滤。例如OSS文件为
testdata/csv/bill.csv,您可以设置正则表达式为(testdata/csv/)(.*)。说明-
推荐与文件路径前缀过滤一起设置,提高效率。此配置与文件路径前缀过滤之前为“且(and)”的关系。
-
调整正则表达式的方法,请参见如何调试正则表达式。
-
-
文件修改时间过滤:从任务启动时刻回溯30分钟作为起始时间,导入此后修改的所有文件(含未来新增文件)。
-
数据格式:文件的解析格式。
-
CSV:分隔符分割的文本文件,支持指定文件中的首行为字段名称或手动指定字段名称。除字段名称外的每一行都会被解析为日志字段的值。
-
单行JSON:逐行读取OSS文件,将每一行看做一个JSON对象进行解析。解析后,JSON对象中的各个字段对应为日志中的各个字段。
-
单行文本:将OSS文件中的每一行解析为一条日志。
-
跨行文本:多行模式,支持指定首行或者尾行的正则表达式解析日志。
-
ORC:ORC文件格式,无需任何配置,自动解析成日志格式。
-
Parquet:Parquet格式,无需任何配置,自动解析成日志格式。
-
阿里云OSS访问日志:阿里云OSS访问日志格式。更多信息,请参见日志转存。
-
阿里云CDN下载日志:阿里云CDN下载日志格式。更多信息,请参见快速入门。
若选择为CSV或跨行文本时,需额外设置相关参数,具体说明如下。
CSV
参数
说明
分隔符
设置日志的分隔符,默认值为半角逗号(,)。
引号
CSV字符串所使用的引号字符。
转义符
配置日志的转义符,默认值为反斜线(\)。
日志最大跨行数
当一条日志跨多行时,需要指定最大行数,默认值为1。
首行作为字段名称
打开开关后,将使用CSV文件中的首行作为字段名称。例如提取以下CSV数据中的首行为日志字段的名称。
remote_addr,remote_user,time_local,request_time,request_length xxx5,-,11/Dec/2020:15:31:06,0,000,133,3650,404,GET xxx5,-,11/Dec/2020:15:32:06,0,000,133,3650,404,GET xxx5,-,11/Dec/2020:15:34:10,0,000,133,3650,404,GET跳过行数
指定跳过的日志行数。例如设置为1,则表示从CSV文件中的第2行开始采集日志。
跨行文本
参数
说明
正则匹配位置
设置正则表达式匹配的位置,具体说明如下:
-
首行正则:使用正则表达式匹配一条日志的行首,未匹配部分为该条日志的一部分,直到达到最大行数。
-
尾行正则:使用正则表达式匹配一条日志的行尾,未匹配部分为下一条日志的一部分,直到达到最大行数。
正则表达式
根据日志内容,设置正确的正则表达式。调整正则表达式的方法,请参见如何调试正则表达式。
最大行数
一条日志最大的行数。
-
-
编码格式:待导入的OSS文件的编码格式。支持GBK、UTF-8。
-
压缩格式:根据设置OSS数据压缩格式,由系统自动检测。
-
检查新文件周期:用于设置导入任务定期扫描新文件的时间间隔,任务将按此时间间隔自动扫描并导入新增的文件。
API
-
产品: 选择一个产品的RestAPI。
-
客户端标识符:选择该产品对应的客户端标识符,如果下拉列表没有可选的客户端标识符,需要点击右侧 “去配置多云资产授权” 链接去管理客户端标识符。
-
采集剧本模版:选择该产品对应的采集剧本模版。
-
剧本名称:填写剧本名称。
-
剧本参数设置:填写剧本参数。(仅部分剧本才需要设置)
-
导入频率:填写日志导入周期,用于设置导入任务定期通过API查询新增日志的时间间隔,任务将按此时间间隔自动查询并拉取新增的日志。
-
-
配置目标数据源
-
数据源名称:选择步骤1创建的数据源。
-
目标Logstore:根据步骤1设置的日志库(Logstore)。
-
-
单击确定保存配置:导入配置完成后,云安全中心将自动从数据导入渠道拉取日志。
分析导入数据
数据成功接入后,需配置相应的解析和检测规则,才能让云安全中心对这些日志进行分析。
费用与成本
-
Agentic SOC 与 SLS 计费:费用的承担主体取决于选择的数据存储方式。
说明Agentic SOC计费说明,请参见Agentic SOC包年包月、Agentic SOC按量付费。
日志服务(SLS)计费说明,请参见计费概述。
数据源类型
Agentic SOC 计费项
SLS 计费项
特别说明
Agentic SOC专属数据采集通道
-
日志接入费用。
-
日志存储、写入费用。
说明以上均消耗日志接入流量。
除日志存储和写入外的其他费用(如公网流量等)。
由Agentic SOC 创建并管理 SLS 资源,因此日志库存储和写入费用由Agentic SOC出账。
用户侧日志服务
日志接入费用,消耗日志接入流量。
日志相关所有费用(包含日志存储和写入、公网流量费用等)。
日志资源全部由日志服务(SLS)管理,因此日志相关费用,均由SLS出账。
-
-
OSS相关费用:从 OSS 导入数据时,OSS需收取流量费用和请求费用,关计费项的定价详情,请参见OSS定价。
-
成本计算公式
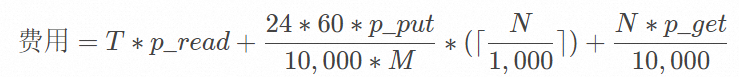
字段
说明
N每天导入的文件个数。
T每天导入的总数据量,单位:GB。
p_read每GB数据的流量费用。
同地域导入时,会产生OSS的内网流出流量,该流量免费。
跨地域导入时,会产生OSS的外网流出流量。
p_put每万次的Put类型请求费用。
日志服务使用ListObjects接口获取目标Bucket中的文件列表。该接口在OSS侧按照Put类型请求收费。另外,该接口每次最多返回1000条数据,因此如果您有100万个新增文件,需要进行1,000,000/1000=1000次请求。
p_get每万次的GET类型请求费用。
M新文件检查周期,单位:分钟。
您可以在创建数据导入配置时,设置检查新文件周期参数。
-
计费案例
-
-
三方费用:
-
腾讯云:腾讯云日志服务-计费概述、腾讯云COS-计费概述。
-
Azure:事件中心定价。
-