Query Insights是PolarSearch的查询分析功能,通过实时查询监控、Top N慢查询分析和配置管理,帮助您全面了解集群的查询负载情况,快速定位和优化性能瓶颈。
功能入口
登录PolarSearch Dashboard,选择OpenSearch Plugins > Query Insights,进入查询洞察页面。Query Insights包含以下三个功能模块:
Live queries:实时监控当前集群正在处理的查询负载。
Top N queries:记录和分析过去一段时间的低效查询。
Configuration:定义慢查询筛选标准、统计规则和数据存储策略。
开启Query insights
PolarSearch中Query insights功能默认关闭。若您有相关需求,可通过Dashboard或者curl命令进行开启。
Dashboard
在OpenSearch Plugins > Query Insights > Configuration中进行开启,需要将Enabled按钮关闭并保存,然后再打开并保存。
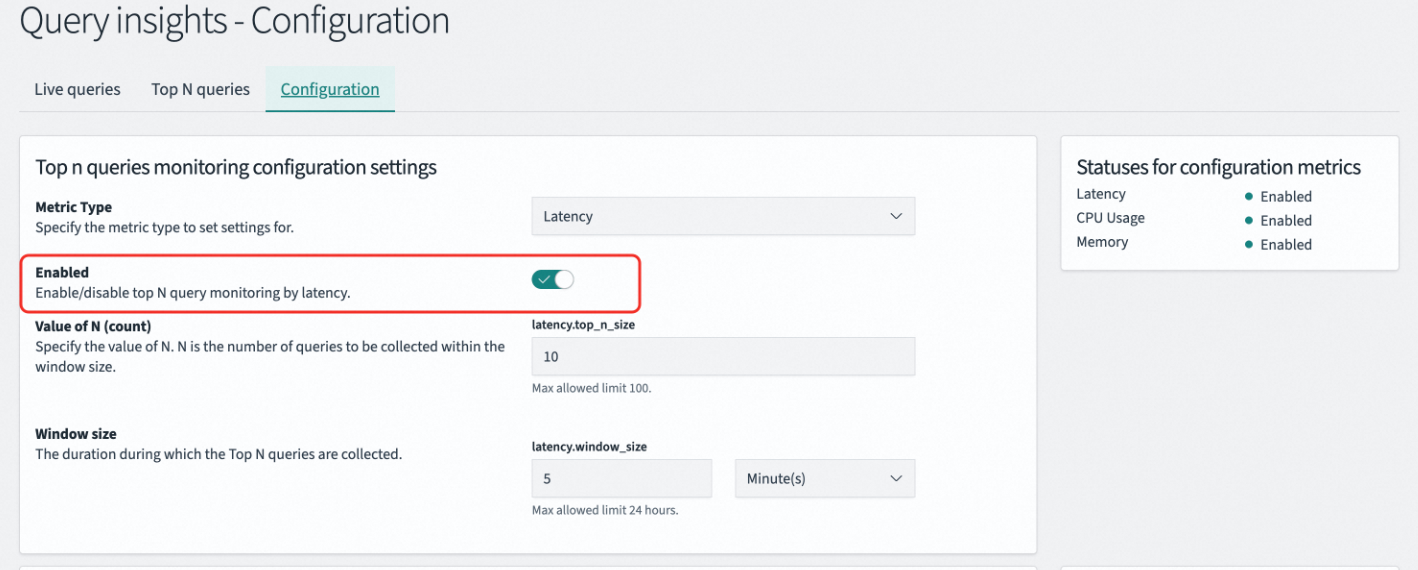
命令行
curl -XPUT "http://<endpoint>:<port>/_cluster/settings?pretty" \
--user "<user_name>:<passwd>" \
-H 'Content-Type: application/json' \
-d '{
{
"persistent": {
"search.insights.top_queries.latency.enabled": true
}
}'Live queries(实时查询)
Live queries页面用于实时监控当前集群正在处理的查询负载,展示活跃查询的关键性能指标、负载分布和统计计数。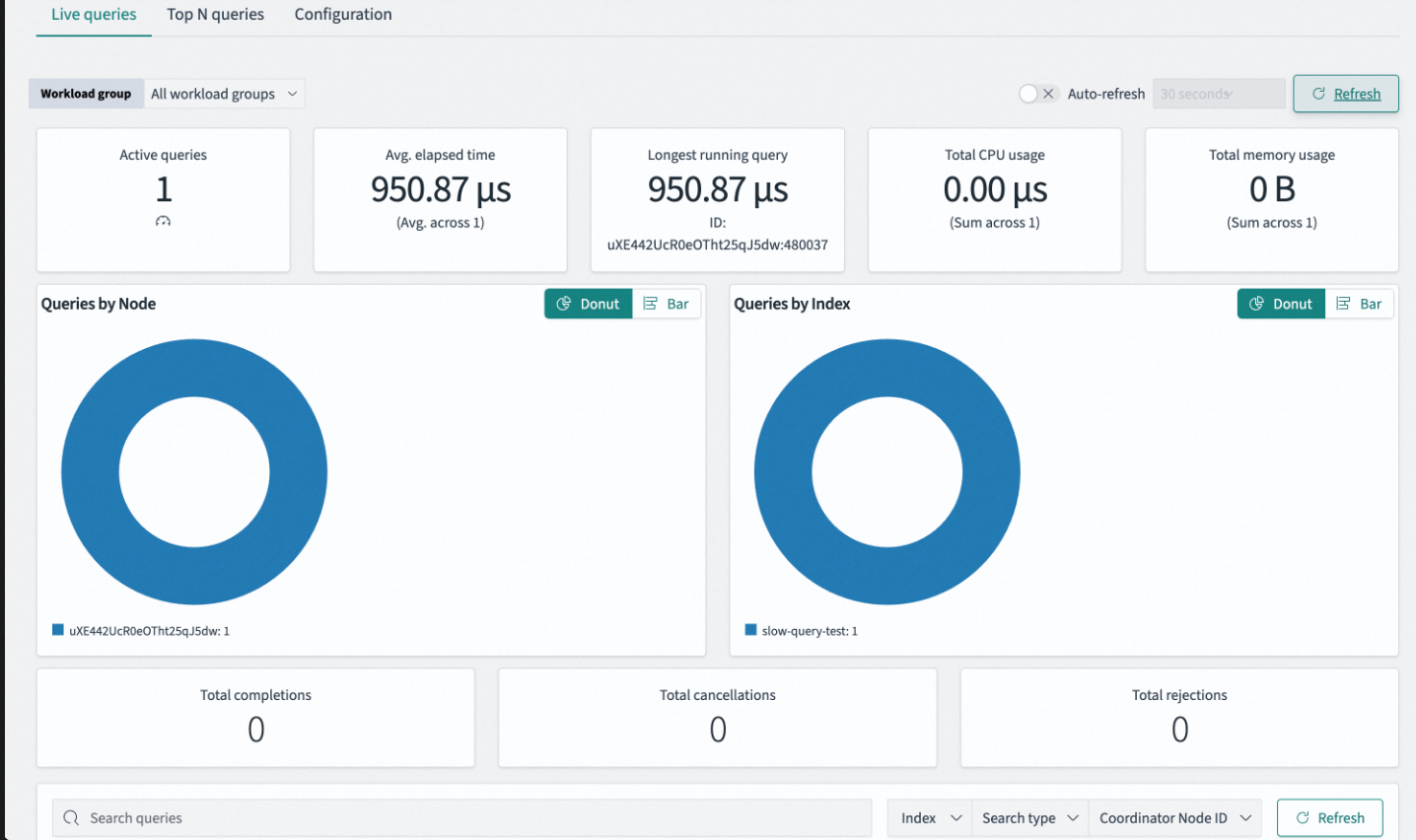
查询指标
指标 | 说明 |
Active queries(活跃查询数) | 当前集群中正处于执行状态的查询请求总数。用于评估集群的并发负载压力,识别是否存在任务堆积现象。 |
Avg. elapsed time(平均耗时) | 当前所有活跃查询自启动至今所消耗时间的算术平均值。用于量化集群的实时响应延迟,衡量系统拥堵程度与处理效率。 |
Longest running query(最长运行查询) | 当前所有活跃查询中持续时间最久的单个查询所消耗的耗时。用于快速定位潜在的长尾延迟或阻塞性查询。 |
Total CPU usage(总CPU使用率) | 当前所有活跃查询占用的CPU计算资源总和。用于甄别查询是否为CPU密集型操作(如复杂聚合分析、脚本评分计算等)。 |
Total memory usage(总内存使用率) | 当前所有活跃查询占用的堆内存总量。用于监测查询是否为内存密集型操作(如大规模排序、深度分页、高基数聚合等),预警内存溢出(OOM)风险。 |
分布图表
分布图表用于直观展示负载在集群中的分布情况。
图表 | 说明 |
Queries by Node(按节点分布) | 显示当前活跃查询在各数据节点上的分布数量。用于检查负载均衡,识别热点节点(Hot Spot),判断是否存在数据倾斜或路由不均。 |
Queries by Index(按索引分布) | 显示当前活跃查询主要集中在哪些索引上。用于定位热点索引,识别导致负载压力的业务表。 |
统计计数器
统计计数器展示当前统计周期内的累计事件数。
计数器 | 说明 |
Total completions(总完成数) | 在当前统计周期内成功执行完毕的查询总数。 |
Total cancellations(总取消数) | 被用户主动取消或因超时被系统强制终止的查询数。数值过高表明有较多查询因响应过慢被终止。 |
Total rejections(总拒绝数) | 被线程池拒绝的查询数。出现拒绝说明集群处理能力已达上限,线程池队列已满,部分请求被丢弃。 |
如果Total rejections数值持续增长,说明集群负载已超出承受能力,建议尽快扩容节点或优化高消耗查询。
Top N queries(Top N慢查询)
Top N queries页面用于记录和分析过去一段时间发生的低效查询,帮助您进行可视化分析和性能优化。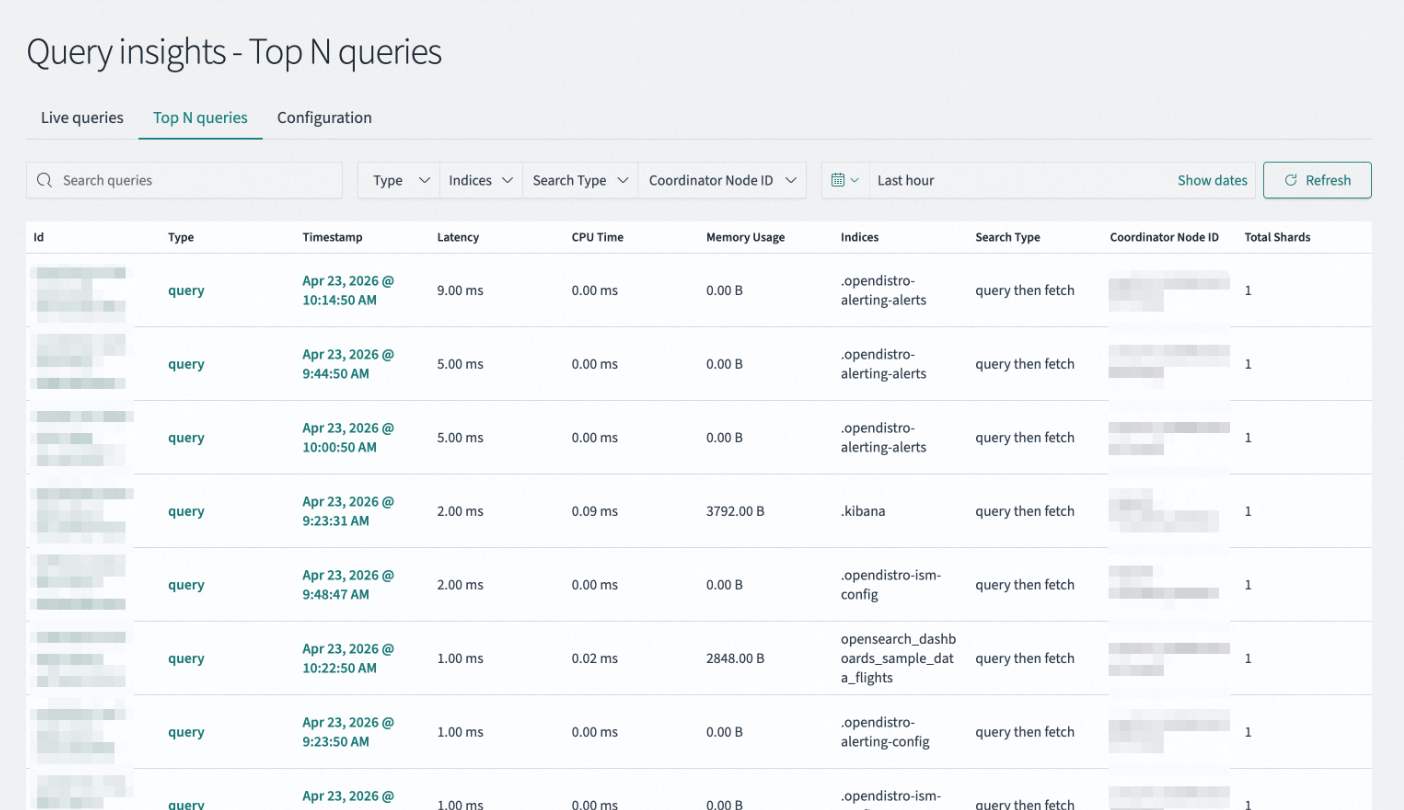
筛选与控制栏
筛选项 | 说明 |
Search queries | 通过关键词(如索引名、部分查询语句)快速检索特定慢查询记录。 |
Type / Indices / Search Type / Coordinator Node ID | 多维筛选器,分别按查询类型、涉及索引、搜索执行策略、协调节点ID进行过滤,缩小排查范围。 |
Last hour / Show dates | 设定查看历史数据的时间窗口,支持选择预设时间范围或自定义时间段。 |
查询详情字段
查询列表展示被系统判定为Top N的查询详情,包含以下字段。
字段 | 说明 |
Id | 查询请求的唯一识别码。单击可跳转至详细查询页面查看具体查询语句。 |
Type | 请求的操作类别,例如query(标准搜索请求)。 |
Timestamp | 查询请求被接收并开始执行的时间点。 |
Latency | 查询从开始到结束所消耗的总时间(单位:毫秒)。数值越高说明查询越慢,是性能优化的首要关注点。 |
CPU Time | 查询执行过程中实际占用CPU进行计算的时间。若CPU Time接近Latency,说明是计算密集型;若远小于Latency,说明大量时间花在I/O等待上。 |
Memory Usage | 查询执行期间占用的堆内存大小。用于识别高内存消耗的查询,预防OOM风险。 |
Indices | 查询所扫描或操作的索引名称。用于定位热点数据,优化分片策略或映射结构。 |
Search Type | 执行查询的具体策略。不同搜索类型有不同的性能特征。 |
Coordinator Node ID | 接收客户端请求并负责分发、汇总结果的协调节点标识。用于排查是否存在节点负载倾斜。 |
Total Shards | 查询总共扫描的分片数量。扫描分片越多开销越大,可通过优化路由或减少不必要的索引扫描来改善。 |
Configuration(配置管理)
Configuration是Query Insights的控制中心,用于定义慢查询的筛选标准、统计规则和数据存储策略。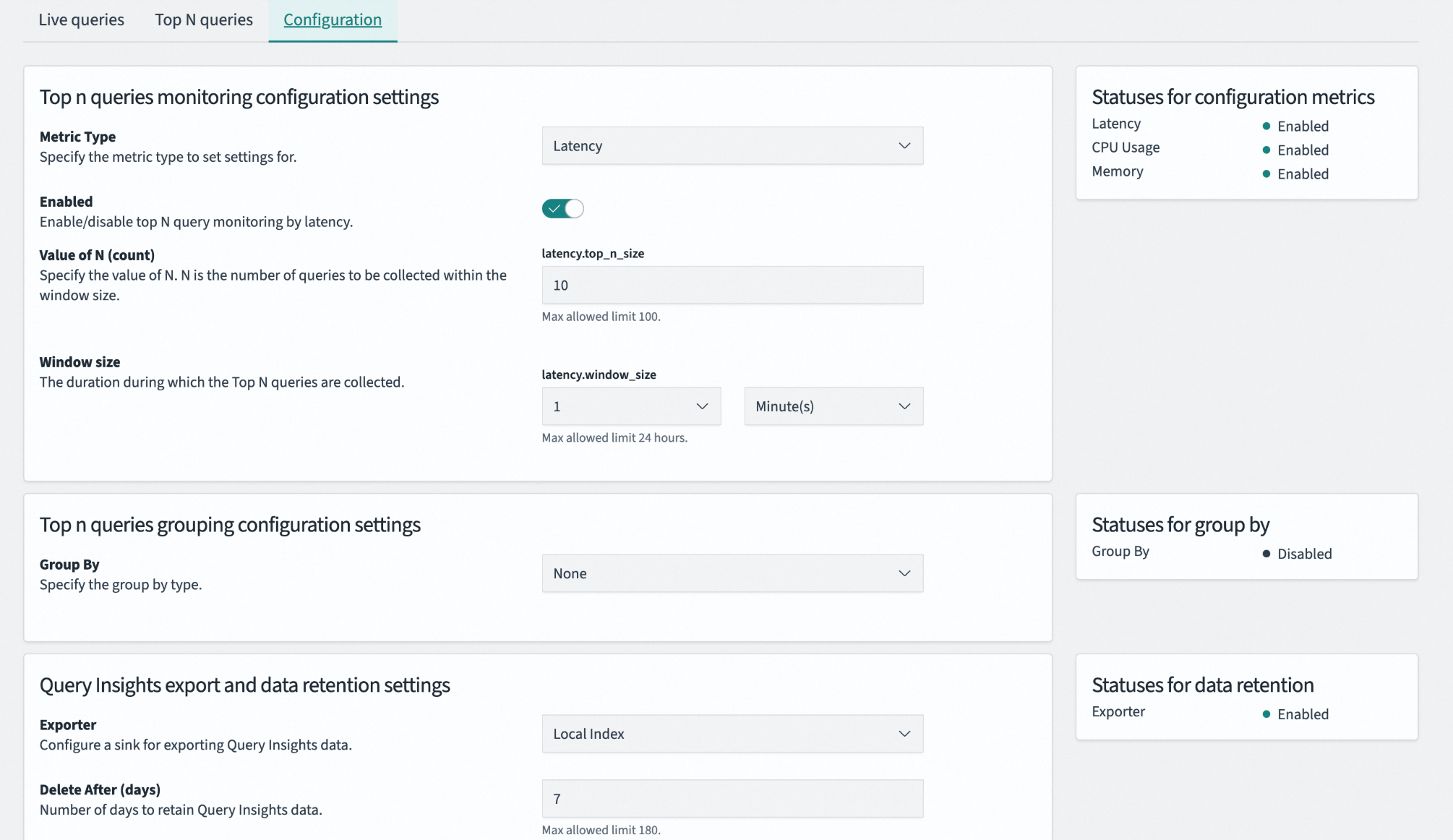
Top n queries monitoring configuration settings(Top N查询监控配置)
定义系统如何筛选和记录慢查询或高资源消耗查询。
配置项 | 说明 |
Metric Type(指标类型) | 指定用于评估查询性能的核心度量标准。可选择Latency(耗时)、CPU Usage(CPU占用)或Memory(内存占用)。 |
Enabled(启用状态) | 当前选定指标类型的Top N监控功能开关。关闭后可减少系统开销,但会停止相关诊断数据的生成。 |
Value of N(N值) | 设定在统计时间窗口内保留的排名靠前的查询记录条数。数值过小可能遗漏问题,过大会增加存储负担。上限为100。 |
Window size(时间窗口大小) | 定义系统进行统计和排名的时间周期。较短的窗口能捕捉瞬时尖峰,较长的窗口能反映持续性负载问题。上限为24小时。 |
Top n queries grouping configuration settings(Top N查询分组配置)
定义如何将相似的查询进行归类,避免榜单被大量重复的相同查询占据。
配置项 | 说明 |
Group By(分组依据) | 指定对查询请求进行指纹识别和归类的维度。开启后,系统会将结构相同的查询视为一类进行统计,防止单一高频查询刷屏,帮助发现模式化的性能问题。 |
Query Insights export and data retention settings(数据导出与留存配置)
管理监控数据的存储位置和生命周期。
配置项 | 说明 |
Exporter(导出器) | 指定Query Insights采集数据的存储目标。Local Index表示存储在集群内部的专用索引中。 |
Delete After(数据保留天数) | 设定监控数据的最大存活时间,过期后自动删除。设置过短会影响历史趋势分析,设置过长可能导致监控索引膨胀。 |
状态面板
页面右侧的状态面板提供配置的实时反馈(只读),包括以下信息:
Statuses for configuration metrics:展示Latency、CPU Usage、Memory三项核心指标的监控启用状态。
Statuses for group by:显示查询分组功能当前的启用或禁用状态。
Statuses for data retention:显示数据导出器是否正常工作,确保数据被成功写入存储位置。