本文介绍了使用列存索引功能查询OSS上的外表数据的技术原理和使用方法等内容。
背景信息
业务存续期间,随着时间的推移,数据的规模不断增加导致存储成本上升。用户在应对激烈的市场竞争时,业务逻辑也在不断地发生变化,对应计算分析的复杂度也在提升,因此,计算性能至关重要。另外,一个完整的数据应用,通常需要组合多个分析工具来完成不同的需求,数据需要流转在不同的系统之间。
使用列存索引功能读取OSS上的外表数据能很好的实现上述需求,优势如下:
OSS作为云原生的存储方案有着非常高的性价比;
列存索引功能能够提供超高的计算速度和计算的灵活性;
开放的数据存储格式(如ORC、Parquet)有着广泛的兼容性以及高压缩比,便于数据在不同系统之间流转。
适用范围
仅支持MySQL 8.0.2版本。
对于8.0.2.2.30.2及以下版本,请勿直接使用,因其可能存在兼容性问题,从而影响列存节点的可用性。如需相关技术支持,请提交工单与我们联系。
技术原理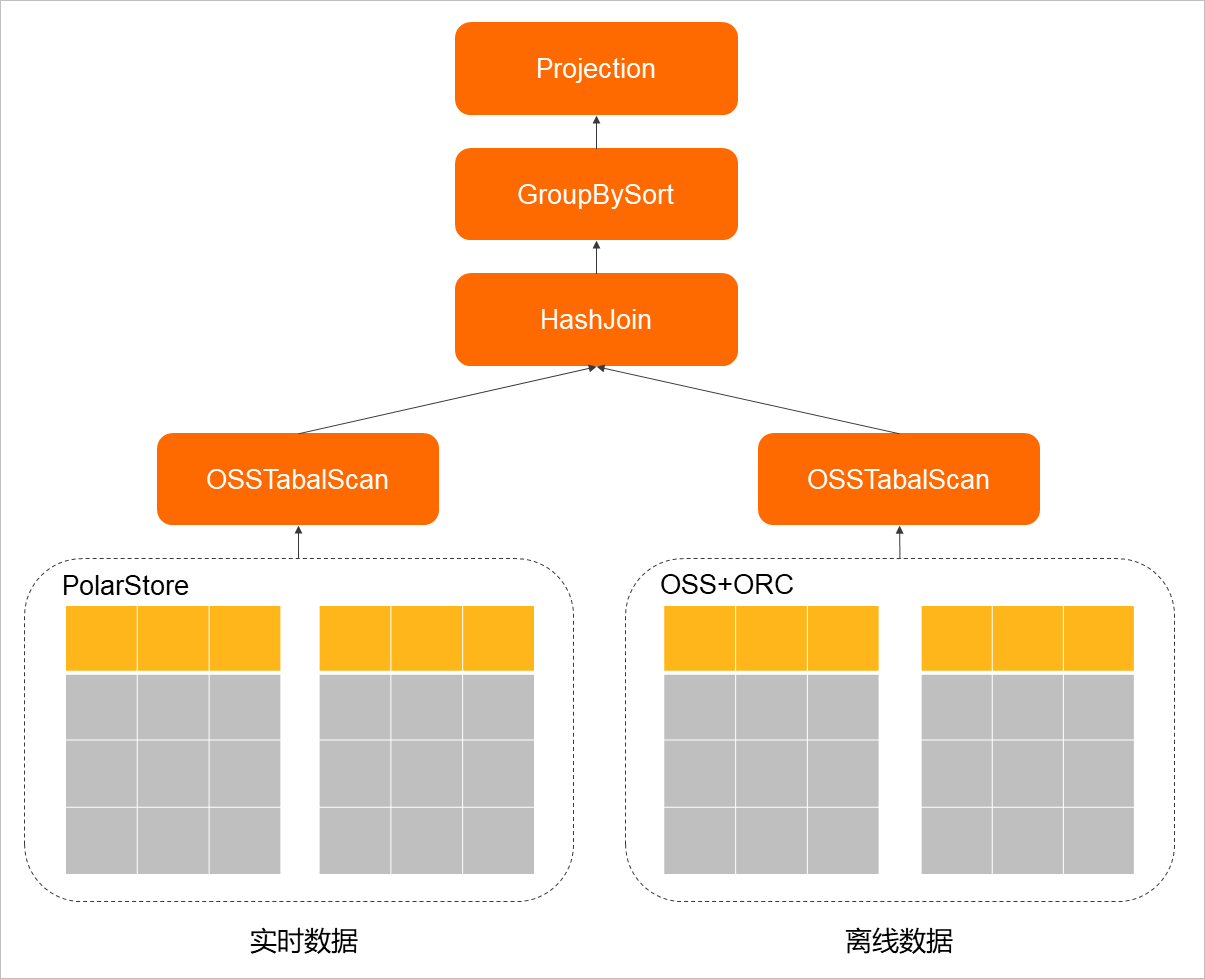
列存索引(IMCI)是一个高性能的列存分析引擎,ORC和Parquet也是列存格式,OSS支持高并发读取,在高并发时可以获取更高的网络吞吐。因此,IMCI的并行扫描功能可以充分利用OSS的高带宽,并通过并行计算或向量计算来提升CPU的使用效率,最终获得极高的分析速度,并支持离线和实时数据的聚合分析。
典型应用场景
以一个典型数仓架构为例,通过ETL将在线数据(关系数据库或者应用服务日志)导入离线分析平台做计算分析,分析的结果(如数仓模型的数据集市层ADS)再导入关系数据库中,用于对接BI报告、监控和广告计算等应用。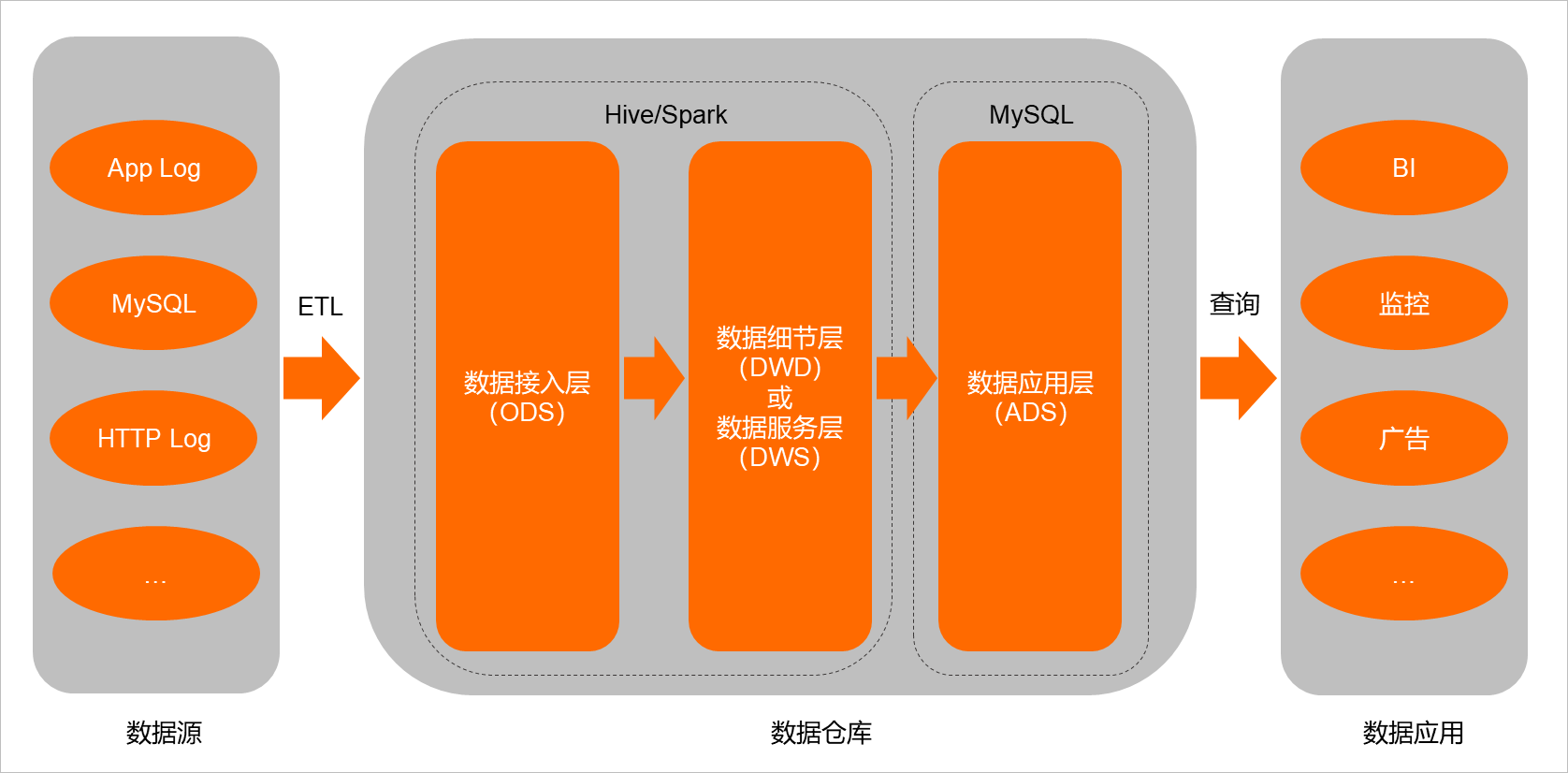
该架构有几个典型的瓶颈点:
将离线数仓分析结果导入关系型数据库时,存在导入速度慢和存储成本高等问题;
数据应用层(ADS)并不只是简单的查询数据和分析结果,也存在大量的计算,甚至会将离线数据和实时数据进行聚合分析,此时,行存格式的MySQL并不能很好的支撑这些操作。
使用该功能后,数据架构如下图所示: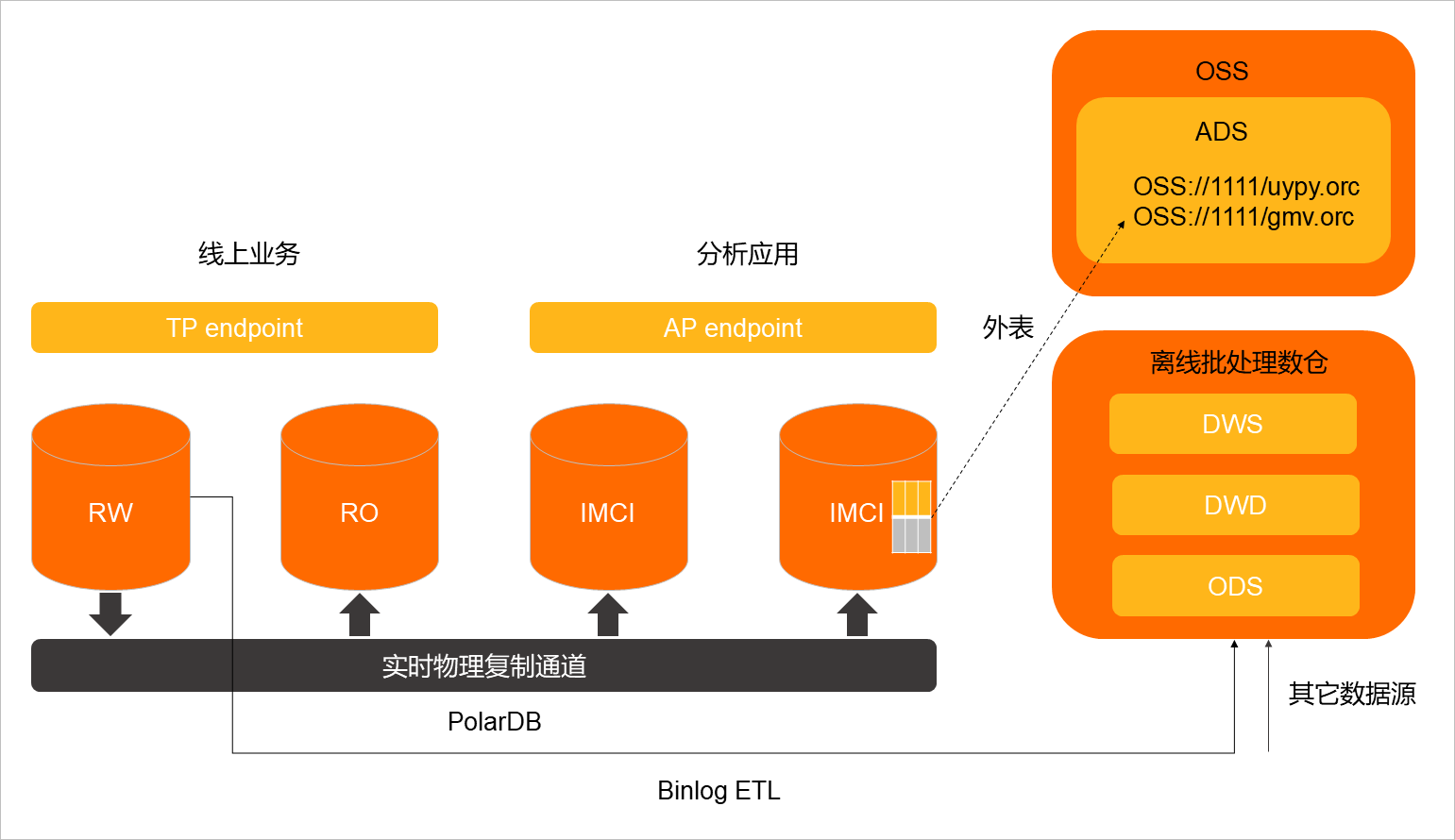
该架构既解决了数据应用层(ADS)的存储成本,同时也实现了高性能的“二次”即席分析以及离线或在线数据的整合分析。
注意事项
CREATE语句中必须添加
COMMENT='columnar=1'和CONNECTION信息。当查询同时涉及本地表和OSS外表时,需要在本地表上创建列存索引。
参数说明
参数 | 说明 |
imci_ignore_schema_miss_match_oss_file | 扫描OSS上的数据文件时,是否忽略与Schema不匹配的文件。取值如下:
|
imci_oss_table_scan_unit | IMCI并行扫描的单次扫描范围。 取值范围:0~1000。默认值为2。 |
imci_oss_max_retries | 读取OSS上的外表数据失败时的重试次数。 取值范围:0~100。默认值为0。 |
imci_oss_max_retriy_backoff_ms | 取值范围:10~1000。默认值为300。 |
imci_oss_scan_odps_compatible | 是否以ODPS兼容模式导出数据。取值如下:
|
使用方法
创建OSS外表。
通过CREATE语句建表,并标明列类型、OSS连接信息以及OSS上的数据文件路径。您可以使用以下两种方式来标明列类型。
第一种方式:从OSS数据文件中获取列类型(推荐),如下所示:
CREATE FOREIGN TABLE `test` FROM CONNECTION='OSS://${oss_key}:${oss_key_secret}@${endpoint}/${bucket}/test.orc' COMMENT='columnar=1';您可以使用
SHOW create tabletabname命令来查看列类型,如下所示: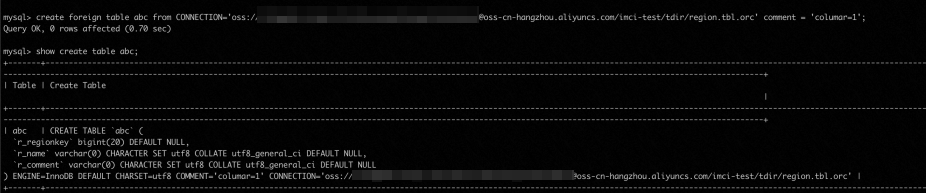
第二种方式:在建表时指定列类型,如下所示:
CREATE TABLE `test` ( `r_regionkey` bigint(20), `r_name` text, `r_comment` text, PRIMARY KEY (`r_regionkey`) ) COMMENT='columnar=1' CONNECTION='OSS://${oss_key}:${oss_key_secret}@${endpoint}/${bucket}/test.orc'其中,OSS连接信息可以写在
CONNECTION字段中。也可以先创建FOREIGH SERVER,然后在创建表时,在CONNECTION字段引用FOREIGH SERVER的OSS连接信息。示例如下:CREATE SERVER test_oss_server FOREIGN DATA WRAPPER oss OPTIONS (EXTRA_SERVER_INFO '{"oss_bucket":"xxx, "oss_access_key_id":"xxx", "oss_endpoint":"xxx", "oss_access_key_secret":"xxx", "oss_prefix":"/test/path"}'); SELECT * FROM mysql.servers; CREATE TABLE `test` (...) COMMENT='columnar=1' CONNECTION='test_oss_server/test.orc';上述配置用于读取OSS上
/test/path/路径下的test.orc文件中的数据 。如果需要读取多个文件中的数据,您可以在建表时指定文件所在目录,且目录以“/”结尾。示例如下:CREATE TABLE `test`(...) COMMENT='columnar=1' CONNECTION='OSS://${oss_key}:${oss_key_secret}@${endpoint}/${bucket}/orders/2022-09-01/'上述配置用于读取OSS上
orders/2022-09-01/目录下所有符合条件的文件中的数据。
对接MaxCompute导出数据。
执行如下命令,将数据写入OSS。
CREATE EXTERNAL TABLE IF NOT EXISTS mc_oss_orc_external ( vehicleId int, recordId int, patientId int, calls int, locationLatitute double, locationLongtitue double, recordTime string, direction string ) STORED AS orc LOCATION 'oss:///${oss_key}:${oss_key_secret}@oss-cn-hangzhou-internal.aliyuncs.com/oss-mc-test/Demo4/output/'; INSERT INTO TABLE mc_oss_orc_external SELECT * FROM mc_oss_orc_external;上述命令会在
output目录下创建一个名称为.odps的文件夹,包含.meta文件和保存ORC文件的文件夹。且每执行一次写入操作都会创建一个以日期为前缀的文件夹,来存放最近一次写入的数据。如:output/.odps/20220413*********/****.orc。以ODPS(MaxCompute)兼容模式建表和读取数据。示例如下:
SET imci_oss_scan_odps_compatible=on; CREATE FOREIGN TABLE `test` FROM CONNECTION='oss:///${oss_key}:${oss_key_secret}@oss-cn-hangzhou-internal.aliyuncs.com/oss-mc-test/Demo4/output/' COMMENT='columnar=1'; SELECT count(*) FROM test;说明开启ODPS兼容模式读取数据时,只读最近一次写入的数据。
性能测试
本次将使用TPC-H生成100 GB的数据,来测试使用列存索引功能查询OSS上外表中的数据的性能。
测试环境:Ice Lake 32C256 GB nvme本地盘。
参数配置:集群默认参数配置。
测试结果:测试结果请参见下表:
查询SQL
Parquet格式-执行SQL语句耗时(单位:秒)
ORC格式-执行SQL语句耗时(单位:秒)
Q1
57.464
52.741
Q2
41.1
71.311
Q3
53.907
49.745
Q4
42.695
31.302
Q5
92.04
90.19
Q6
34.717
33.243
Q7
58.458
57.47
Q8
66.797
79.089
Q9
129.574
147.035
Q10
54.873
74.768
Q11
18.321
23.555
Q12
47.032
40.028
Q13
16.315
25.563
Q14
36.304
46.174
Q15
68.015
80.016
Q16
10.461
23.829
Q17
69.351
74.21
Q18
57.945
45.357
Q19
52.077
61.992
Q20
39.846
67.283
Q21
112.834
92.385
Q22
13.02
22.267
TOTAL
1173.146
1289.553