该基准测试展示了PolarDB向量索引在MySQL协议特定软硬件配置下,处理亿级千维向量的写入与查询性能。本文包括测试环境、数据集、关键配置参数、复现步骤及性能结果分析,为技术选型、容量规划和性能调优提供数据参考。
适用范围
性能数据基于特定的集群环境和数据集。在应用这些数据进行决策前,需确认环境与以下条件相似。
集群规格与版本
主节点:4核 16GB。
只读节点:4核 16GB。
列存索引只读节点:88核 710 GB。
客户端延迟:0.201毫秒。
内核版本:MySQL 8.0.2。
数据集
分类 | 子项 | 详情 |
软件版本 | PolarDB MySQL | 8.0.2 |
数据集 | MSMARCO V2.1 | |
数据类型 | 单精度浮点数(FP32) | |
数据规模 | 113,520,750 | |
向量维度 | 1024 | |
查询集大小 | 1677 | |
算法参数 | 距离度量 | INNER_PRODUCT(内积距离) |
索引类型 | HNSW |
测试步骤
以下步骤描述了如何复现索引创建、数据写入和性能压测。
创建向量索引并写入数据
创建用于存储向量数据的表,并定义向量索引的类型和关键参数。执行以下DDL语句创建
doc_embeddings表。CREATE TABLE doc_embeddings ( id INT(11) NOT NULL AUTO_INCREMENT, docid VARCHAR(45) NOT NULL, emb VECTOR(1024) DEFAULT NULL COMMENT 'imci_vector_index=FAISS_HNSW_SQ(metric=INNER_PRODUCT,max_degree=16,ef_construction=200,sq_type=fp16)', PRIMARY KEY (id) ) ENGINE = InnoDB COMMENT 'columnar=1' PARTITION BY HASH (id) PARTITIONS 8;参数说明
COMMENT 'columnar=1':此注释用于为该表创建列存索引,是使用向量索引的前提。COMMENT 'imci_vector_index=...':通过注释方式定义向量索引。FAISS_HNSW_SQ:表示使用基于FAISS库实现的HNSW算法,并结合标量量化(Scalar Quantization)进行压缩。sq_type=fp16:指定量化类型为16位浮点数(FP16),可在保证较高精度的同时,将内存占用和原始数据大小减半。max_degree=16、ef_construction=200:HNSW索引的构建参数。详情请参见创建向量索引。
PARTITION BY HASH (id) PARTITIONS 8:利用自增主键将表和索引数据哈希打散到8个分区。此策略旨在利用多核并行处理能力,平衡高并发下的查询延迟和吞吐量。分区数通常建议与CPU核数相关或根据压测结果调整。
写入数据:将MSMARCO V2.1数据集写入
doc_embeddings表。PolarDB会自动在列存索引只读节点后台构建FAISS_HNSW_SQ向量索引。
写性能
总耗时:6296.51秒(约1.75小时),此时间包含数据网络传输、写入
doc_embeddings表以及后台FAISS_HNSW_SQ索引构建的全部时间。平均写入吞吐量:18029.15 vectors/sec。
执行查询性能测试
测试不同并发度和ef_search参数组合下的查询吞吐量(QPS)、延迟(Latency)和召回率(Recall)。
concurrency:模拟从1到128个并发查询。ef_search:查询时在HNSW图中搜索的邻居节点广度。此值越大,理论上召回率越高,但计算开销也越大,会导致QPS下降和延迟升高。
压测命令
执行以下命令,在脚本内部对concurrency和ef_search的进行不同组合,且为期60秒的压测。
若您有相关需求,请提交工单与我们联系,获取测试脚本以复现当前测试流程。
# 示例命令
python perf_test_parallel.py性能测试结果
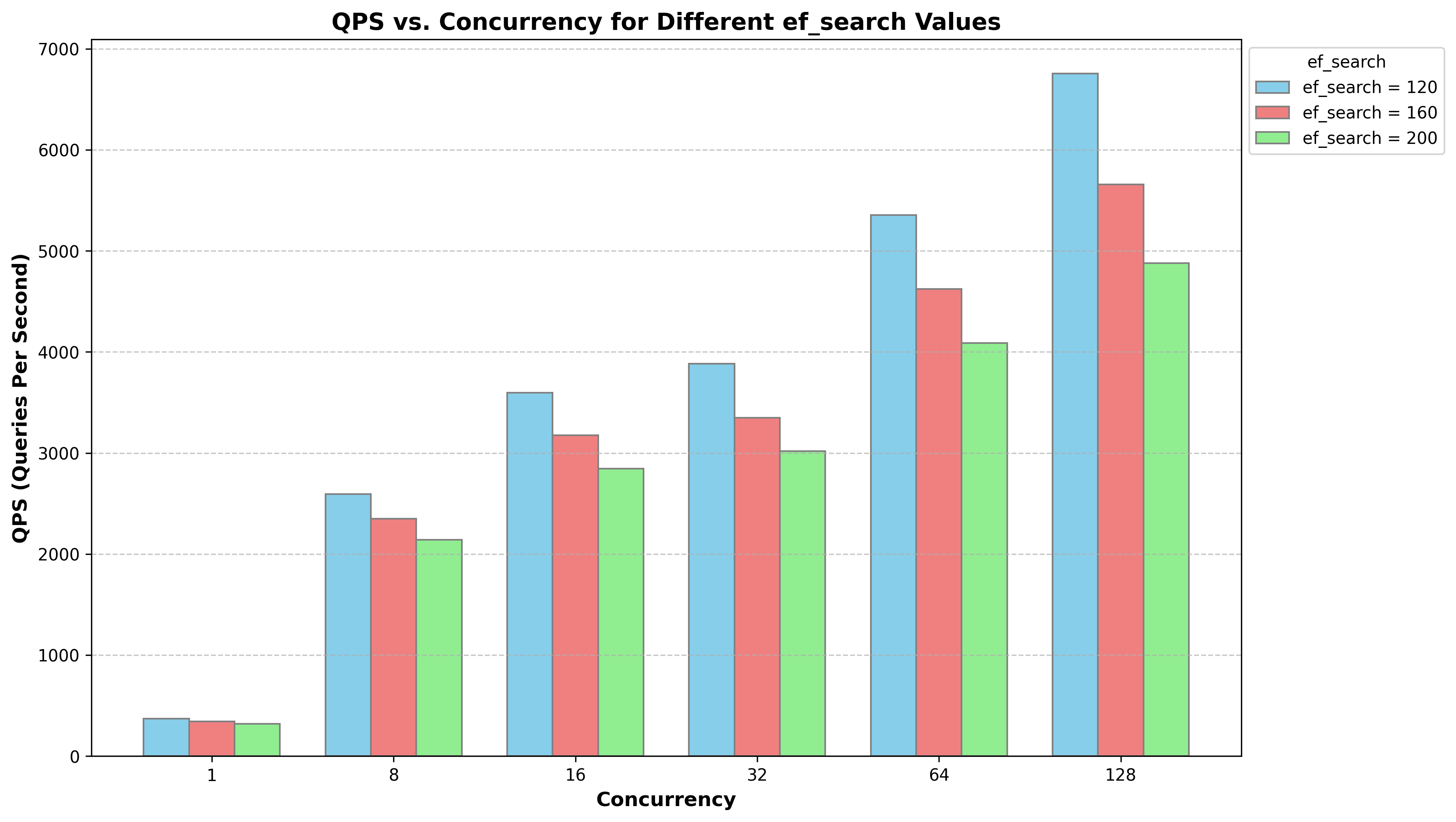
ef_search | concurrency | Recall@10 | QPS | Avg Latency (ms) | P95 Latency (ms) | P99 Latency (ms) |
120 | 1 | 0.9519 | 370.73 | 2.69 | 3.23 | 3.67 |
120 | 8 | 0.9525 | 2593.79 | 3.07 | 3.80 | 4.41 |
120 | 16 | 0.9523 | 3596.98 | 4.44 | 6.16 | 7.41 |
120 | 32 | 0.9525 | 3884.38 | 8.23 | 11.47 | 13.35 |
120 | 64 | 0.9524 | 5352.73 | 11.94 | 18.30 | 21.82 |
120 | 128 | 0.9524 | 6753.36 | 18.94 | 34.27 | 42.53 |
160 | 1 | 0.9600 | 343.76 | 2.90 | 3.55 | 4.00 |
160 | 8 | 0.9600 | 2348.89 | 3.40 | 4.24 | 4.81 |
160 | 16 | 0.9598 | 3175.30 | 5.03 | 6.88 | 8.21 |
160 | 32 | 0.9599 | 3347.77 | 9.55 | 12.94 | 14.85 |
160 | 64 | 0.9600 | 4624.36 | 13.83 | 21.32 | 25.44 |
160 | 128 | 0.9603 | 5657.66 | 22.61 | 41.08 | 51.13 |
200 | 1 | 0.9647 | 317.60 | 3.14 | 3.88 | 4.34 |
200 | 8 | 0.9658 | 2139.50 | 3.73 | 4.68 | 5.33 |
200 | 16 | 0.9657 | 2843.98 | 5.62 | 7.70 | 9.26 |
200 | 32 | 0.9658 | 3018.77 | 10.59 | 14.24 | 16.48 |
200 | 64 | 0.9661 | 4086.58 | 15.65 | 24.30 | 29.03 |
200 | 128 | 0.9657 | 4879.21 | 26.22 | 47.74 | 59.58 |
性能结论分析
高吞吐与良好的扩展性:
随着并发度从1增加到128,系统整体QPS持续增长,表明PolarDB的并行计算框架能够有效利用多核资源处理并发请求。
在
ef_search=120时,QPS从单并发的370增长至128并发下的6,753,展现了优异的水平扩展能力。
低延迟与稳定的长尾表现:
在单并发的理想情况下,平均延迟低至2.69ms,P99延迟控制在3.67ms,响应速度快。
即使在128高并发、
ef_search=200的重度负载下,P99延迟仍能控制在60ms以内,保障了高负载下服务的可用性。
性能与精度的权衡关系:
对比
ef_search为120、160、200三组数据可见:随着ef_search的增加,召回率(Recall@10)从约0.952提升至0.966,获得了约1.4%的精度提升。为此付出的代价是,在128并发下,QPS从6753下降至4879(降低约28%),平均延迟从18.94ms上升至26.22ms(增加约38%)。
高并发下的性能瓶颈:
在并发度从64增至128时,QPS的增长速度开始放缓,而P99延迟则出现较大幅度的上升。这表明系统资源(如CPU)已接近饱和,开始出现资源竞争,这是高并发系统的正常现象。
关键参数建议
选择合适的索引和查询参数,是在查询精度(召回率)、性能(QPS和延迟)和资源成本(内存)之间进行权衡的过程。
索引构建参数(
max_degree与ef_construction):这两个参数在创建索引时定义,决定了HNSW图的结构,影响索引构建时间、内存占用和最终的查询性能。max_degree:HNSW图中每个节点的最大出度(连接数)。ef_construction:构建索引时,动态邻居列表的大小。
场景
max_degreeef_construction效果
高召回率优先
增大(如32、64)
增大(如400、500)
索引图更复杂,连接更丰富,查询时更容易找到最优路径,召回率更高。但构建更慢,内存占用更高。
快速构建/低内存
减小(如12、16)
减小(如100、200)
索引图更稀疏,构建速度快,内存占用低。但可能牺牲一定的召回率。
本次测试选择
16
200
在召回率、性能和资源消耗之间取得的一个平衡点。
查询参数(
ef_search):此参数在查询时指定,决定了搜索范围的广度,是性能与精度权衡的最直接手段。ef_search值越大:优点:搜索范围更广,访问的节点更多,召回率(
Recall)更高。缺点:计算开销更大,导致查询延迟(
Latency)升高,吞吐量(QPS)下降。
ef_search值越小:优点:计算开销小,查询速度快,延迟低,吞吐量高。
缺点:搜索范围受限,可能错过最优结果,导致召回率降低。
决策建议
对于在线服务、对延迟敏感的场景:选择较小的
ef_search值(如本测试中的120),在可接受的召回率下换取最高的QPS和最低的延迟。对于离线分析、对精度要求极高的场景:可以选择更大的
ef_search值(如200或更高),以牺牲性能为代价换取尽可能高的召回率。