在大语言模型(LLM)应用中,用户请求与模型响应的长度差异、模型在Prompt和Generate阶段生成的Token数量的随机性,以及GPU资源占用的不确定性,使得传统负载均衡策略难以实时感知后端负载压力,导致实例负载不均,影响系统吞吐量和响应效率。EAS推出LLM智能路由组件,基于LLM特有的Metrics动态分发请求,均衡各推理实例的算力与显存分配,提升集群资源利用率与系统稳定性。
工作原理
架构概览
LLM智能路由是由LLM Gateway、LLM Scheduler以及LLM Agent三个核心组件构成,它们协同工作,为后端的大语言模型推理实例集群提供智能的流量分发和管理。
LLM智能路由本质上是一种特殊的EAS服务,必须和推理服务部署在同一个服务群组下,才能正常工作。

核心流程如下:
实例注册:推理服务启动后,
LLM Agent等待推理引擎就绪,然后向LLM Scheduler注册该实例,并开始周期性上报健康状况和性能指标。流量接入:用户的请求首先到达
LLM Gateway。调度决策:
LLM Gateway向LLM Scheduler发起调度请求。智能调度:
LLM Scheduler基于调度策略和从各LLM Agent收集的实时指标,选择一个当前最优的后端实例。请求转发:
LLM Scheduler将决策结果返回给LLM Gateway,LLM Gateway随即把用户的原始请求转发到该目标实例。请求缓冲:当所有后端实例均处于高负载状态时,新请求会暂时缓存在
LLM Gateway的队列中,等待LLM Scheduler找到合适的转发时机,以避免请求失败。
核心组件
组件 | 核心职责 |
LLM Gateway | 流量入口与请求处理中心。负责接收所有用户请求,并根据
|
LLM Scheduler | 智能调度的大脑。它汇集所有 |
LLM Agent | 部署在推理实例旁的探针。作为Sidecar容器与每个推理实例一同部署。负责采集推理引擎的性能指标,与 |
Failover机制
系统设计了多层容错机制以保障服务稳定性:
LLM Gateway(高可用):作为无状态的流量接入层,建议部署至少2个实例。当某个实例故障时,流量会自动切换至其他健康实例,保证服务的持续可用性。
LLM Scheduler(降级容错):作为请求调度组件,单实例运行以实现全局调度。
LLM Scheduler发生故障时,LLM Gateway会在心跳失败后自动降级,采用轮询策略将请求直接转发给后端实例。这保证了服务的可用性,但会牺牲调度性能。待LLM Scheduler恢复后,LLM Gateway会自动切换回智能调度模式。推理实例或LLM Agent(自动摘除):当某个推理实例或其伴生的
LLM Agent发生故障时,LLM Agent与LLM Scheduler之间的心跳会中断。LLM Scheduler会立即将该实例从可用服务列表中移除,不再向其分配新流量。待实例恢复并重新上报心跳后,它将自动重新加入服务列表。
多推理引擎支持
由于不同LLM推理引擎的/metrics接口返回的指标信息存在差异,LLM Agent负责对这些指标进行采集并统一格式化处理后上报。LLM Scheduler无需关注具体推理引擎的实现细节,只需基于统一化指标进行调度算法的编写。目前支持的LLM推理引擎及其对应的采集指标如下:
LLM推理引擎 | 指标 | 说明 |
vLLM | vllm:num_requests_running | 正在运行的请求数。 |
vllm:num_requests_waiting | 在排队等待的请求数。 | |
vllm:gpu_cache_usage_perc | GPU KV Cache的使用率。 | |
vllm:prompt_tokens_total | 总Prompt的Token数。 | |
vllm:generation_tokens_total | 生成的总的Token数。 | |
SGLang | sglang:num_running_reqs | 正在运行的请求数。 |
sglang:num_queue_reqs | 在排队等待的请求数。 | |
sglang:token_usage | KV Cache的使用率。 | |
sglang:prompt_tokens_total | 总Prompt的Token数。 | |
sglang:gen_throughput | 每秒生成的Token数。 |
使用限制
不支持更新时添加:LLM智能路由功能仅能在创建新服务时配置。对于一个已存在的、未使用智能路由的推理服务,无法通过更新服务操作来为其添加智能路由。
推理引擎限制:目前仅支持 vLLM 或 SGLang。
推荐部署多推理实例:在部署多个推理实例的场景下,LLM智能路由的功能价值才能得以发挥。
快速开始:使用LLM智能路由
步骤一:部署LLM智能路由服务
登录PAI控制台,在页面上方选择目标地域。
在左侧导航栏单击模型在线服务(EAS),选择目标工作空间后进入EAS。
单击部署服务,选择场景化模型部署>LLM智能路由部署。
配置参数:
参数
描述
基本信息
服务名称
自定义服务名称,例如
llm_gateway。资源信息
部署资源
LLM Gateway的资源配置。为确保高可用,副本数默认为2,建议保持。默认 CPU 为4核,内存 为8 GB。调度配置
LLM Scheduler的资源配置。默认 CPU 为2核,内存为 4 GB。调度策略
选择后端推理实例的负载均衡策略,默认基于前缀缓存。详细对比和选择建议请参见调度策略详解与选择。
单击部署。当服务状态变为运行中,表示部署成功。
部署成功后,系统会自动创建一个群组服务,命名格式为group_<LLM智能路由服务名称>。您可以前往模型在线服务(EAS)页面的灰度发布页签进行查看。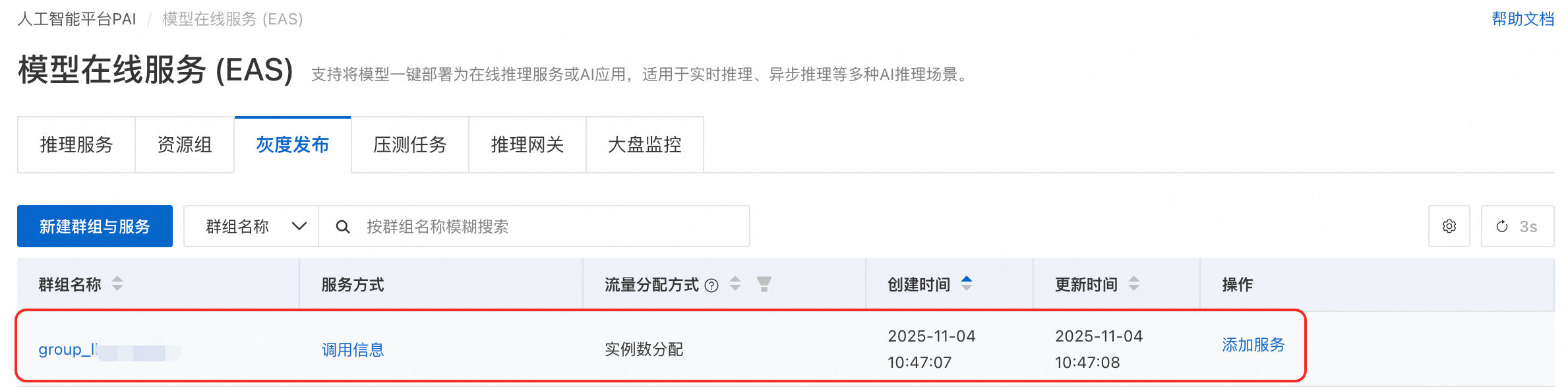
由于智能路由与服务队列存在冲突,同一服务群组中两者不可同时存在。
步骤二:部署LLM服务
必须在部署新LLM服务时配置智能路由功能,无法通过更新已有LLM服务来添加。
以部署 Qwen3-8B 为例,步骤如下:
单击部署服务,选择场景化模型部署> LLM大语言模型部署。
配置以下关键参数:
参数
值
基本信息
模型配置
选择公共模型,搜索并选择Qwen3-8B。
推理引擎
选择vLLM(推荐,兼容 OpenAI API)。
说明如果LLM智能路由服务选择基于前缀缓存的调度策略,部署LLM服务时若推理引擎选择vLLM,请确保开启引擎的前缀缓存功能。
部署模板
选择单机。系统将根据模板自动填充推荐的实例规格、镜像等参数。
服务功能
LLM智能路由
打开开关,从下拉列表中选择步骤一部署的LLM智能路由服务。
单击部署,服务部署耗时约5分钟。当服务状态变为运行中,表示部署成功。
步骤三:调用测试
所有请求都应发送到LLM智能路由服务的访问地址,而不是后端的具体推理服务。
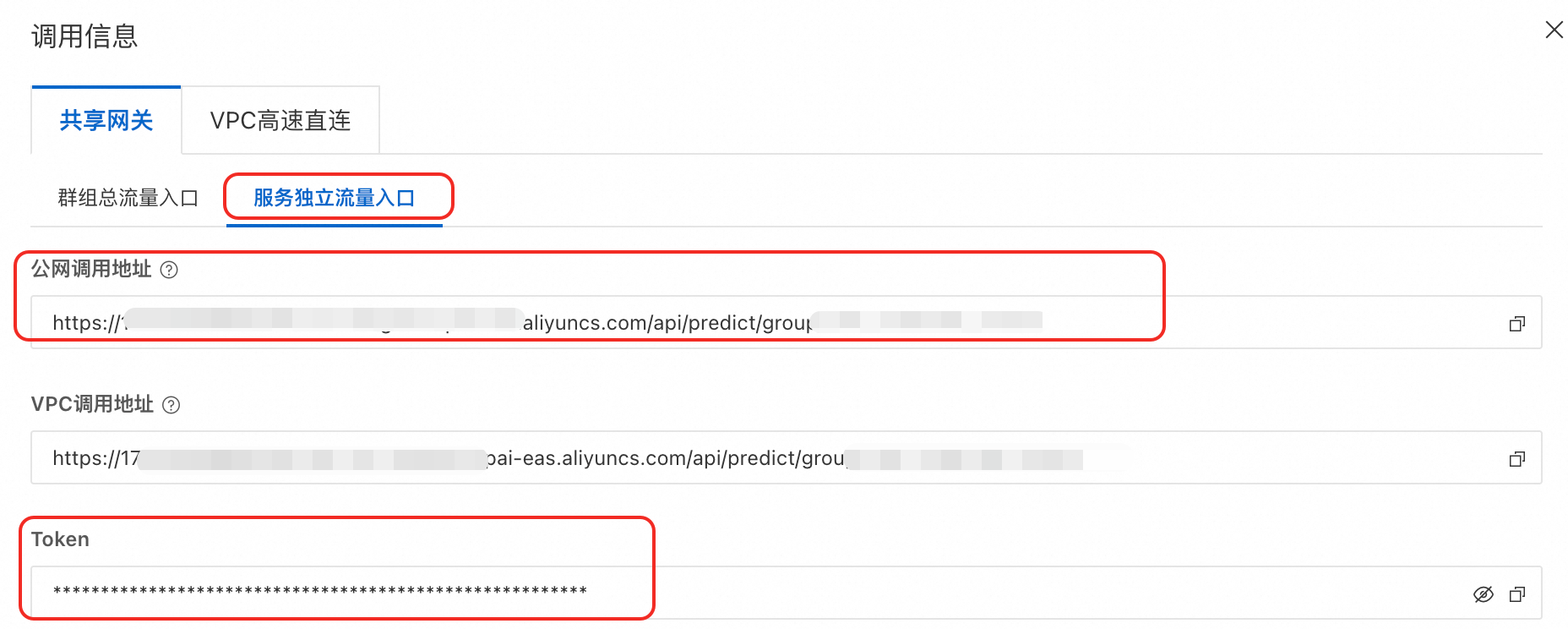
获取访问凭证。
单击LLM智能路由服务进入概览页面,在基本信息区域单击查看调用信息。
在调用信息页面,复制服务独立流量入口下的公网调用地址和Token。
构建请求URL并发起调用。
URL结构:
<LLM智能路由访问地址>/<LLM服务API路径>示例:
http://********.pai-eas.aliyuncs.com/api/predict/group_llm_gateway.llm_gateway/v1/chat/completions
请求示例:
# 将 <YOUR_GATEWAY_URL> 和 <YOUR_TOKEN> 替换为您的实际信息 curl -X POST "<YOUR_GATEWAY_URL>/v1/chat/completions" \ -H "Authorization: Bearer <YOUR_TOKEN>" \ -H "Content-Type: application/json" \ -N \ -d '{ "messages": [{"role": "user", "content": "你好"}], "stream": true }'返回结果示例如下:
data: {"id":"chatcmpl-9a9f8299*****","object":"chat.completion.chunk","created":1762245102,"model":"Qwen3-8B","choices":[{"index":0,"delta":{"role":"assistant","content":""},"logprobs":null,"finish_reason":null}]} data: {"id":"chatcmpl-9a9f8299*****","object":"chat.completion.chunk","created":1762245102,"model":"Qwen3-8B","choices":[{"index":0,"delta":{"content":"<think>","tool_calls":[]}}]} ... data: [DONE]
高阶配置
JSON独立部署提供了更灵活的配置选项,可以对LLM Gateway 指定资源规格,对请求处理行为进行精细化配置。
配置入口:在推理服务页面,单击部署服务,然后在自定义模型部署区域,单击JSON独立部署。
配置示例:
{ "cloud": { "computing": { "instance_type": "ecs.c7.large" } }, "llm_gateway": { "max_queue_size": 128, "retry_count": 2, "wait_schedule_timeout": 5000, "wait_schedule_try_period": 500 }, "llm_scheduler": { "cpu": 2, "memory": 4000, "policy": "prefix-cache" }, "metadata": { "group": "group_llm_gateway", "instance": 2, "name": "llm_gateway", "type": "LLMGatewayService" } }参数说明:
参数
说明
metadata
type
必填。固定为
LLMGatewayService,表示部署一个LLM智能路由服务。instance
必填。
LLM Gateway的副本数。建议至少设置为2,以防止单点故障。cpu
LLM Gateway每个副本的CPU(核数)。memory
LLM Gateway的内存(GB)。group
LLM智能路由服务归属的服务群组。
cloud.computing.instance_type
指定
LLM Gateway使用的资源规格。此时无需配置metadata.cpu与metadata.memory。llm_gateway
max_queue_size
LLM Gateway缓存队列的最大长度,默认是512。当超过后端推理框架处理能力时,多余的请求会缓存在该队列,等待调度。
retry_count
重试次数,默认是2。当后端推理实例异常时,进行请求重试并转发到新的实例。
wait_schedule_timeout
当后端引擎处于满负荷时,请求会间隔尝试进行调度。该参数表示尝试调度的时间,默认为10秒。
wait_schedule_try_period
每次尝试调度的间隔时间,默认为1秒。
llm_scheduler
cpu
LLM Scheduler的CPU(核数),默认为4核。memory
LLM Scheduler的内存(GB),默认为4 GB。policy
调度策略,默认值
prefix-cache。可选值及说明请参见调度策略详解与选择。prefill_policy
policy选择pd-split时,需分别指定Prefill和Decode阶段的调度策略。可取值:prefix-cache、llm-metric-based、least-request、least-token。
decode_policy
调度策略详解与选择
选择合适的调度策略是发挥LLM智能路由价值的关键。下表详细对比了各种策略的逻辑、适用场景及优缺点,帮助您做出最佳决策。
策略名称 | JSON值 | 核心逻辑 | 适用场景 | 优点 | 注意事项 |
基于前缀缓存 | prefix-cache | (推荐) 综合性策略。优先将具有相同历史上下文(Prompt)的请求发往已缓存其KV Cache的实例。 | 多轮对话机器人、RAG系统中System Prompt固定的场景。 | 显著降低TTFT,提升多轮对话性能和吞吐量。 | 需推理引擎开启Prefix Caching功能。 |
基于LLM指标 | llm-metric-based | 根据后端实例的综合负载指标(如排队请求数、运行中请求数、KV Cache使用率)进行智能调度。 | 请求模式多样化,无明显对话特征的通用LLM工作负载。 | 能够很好地平衡不同实例的负载,提高资源利用率。 | 调度逻辑相对复杂,不如前缀缓存策略在特定场景下效果极致。 |
最少请求 | least-request | 将新请求发送到当前正在处理的请求数量最少的实例。 | 请求的计算复杂度(Token长度、生成长度)相对均匀的场景。 | 简单高效,能快速均衡实例间的请求数量。 | 无法感知请求的实际负载,可能导致短请求实例空闲,长请求实例过载。 |
最少token | least-token | 将新请求发送到当前正在处理的Token总数(输入+输出)最少的实例。 | Token数量能较好地反映请求处理成本的场景。 | 比“最少请求”更能反映实例的真实负载。 | 依赖对Token数量的预估,且并非所有引擎都上报此指标。 |
静态PD分离 | pd-split | 需预先将实例划分为Prefill组和Decode组,并为两组分别指定调度策略。 | Prefill和Decode阶段的计算/访存特性差异巨大,且分离部署能带来显著收益的场景。 | 极致优化,最大化硬件利用率。 | 配置复杂,需要对模型和业务有深入理解,并独立部署Prefill和Decode服务。 |
动态PD分离 | dynamic-pd-split | 实例无需预设角色,调度器根据实时负载动态地将请求的Prefill或Decode阶段分发给最合适的实例。 | 同上,但适用于负载动态变化的场景。 | 比静态分离更灵活,能自适应负载变化。 | 配置更复杂,对调度器和引擎要求更高。 |
查看服务监控指标
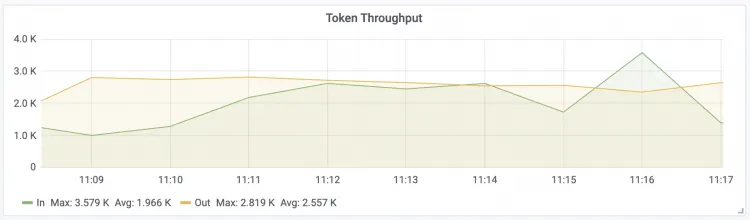
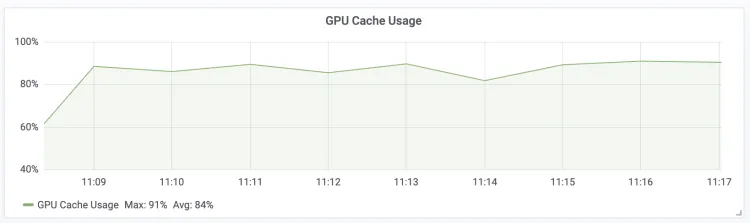
部署服务后,可以在EAS控制台查看服务的核心性能指标,以评估智能路由的效果。
在模型在线服务(EAS)页面,单击已部署的LLM智能路由服务进入服务详情。在监控页签,关注以下核心指标:
Token Throughput LLM输入和输出Token的吞吐量
| GPU Cache Usage LLM Engine GPU KV Cache的使用率
|
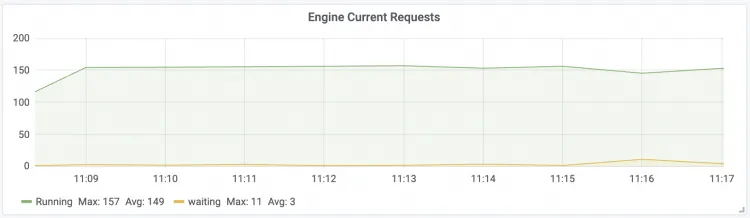
Engine Current Requests LLM Engine实时请求并发数
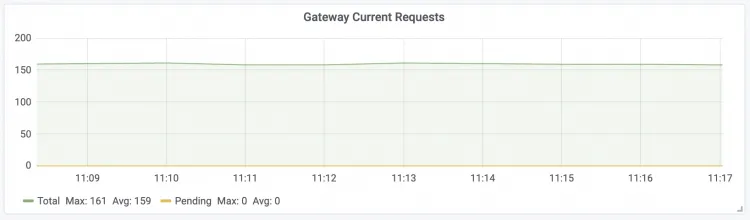
| Gateway Current Requests LLM智能路由实时请求数
|
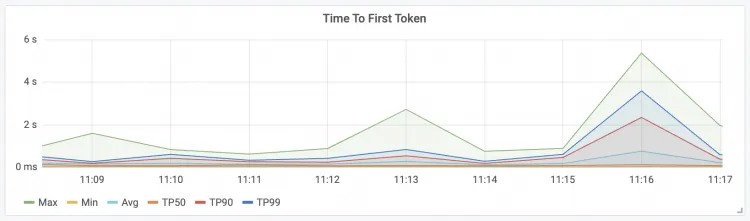
Time To First Token 请求的首包延时
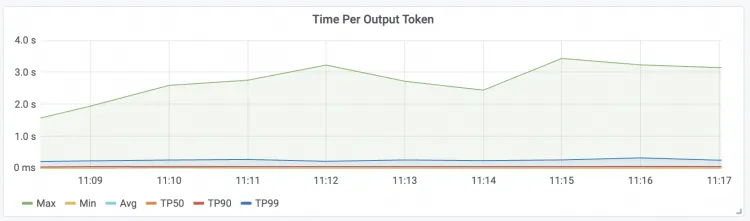
| Time Per Output Token 请求的每包延时
|
附录:使用Claude Code调用
设置 Claude Code 使用EAS智能路由服务提供的 BASE URL 与 TOKEN。
# 将 <YOUR_GATEWAY_URL> 和 <YOUR_TOKEN> 替换为您的实际信息 export ANTHROPIC_BASE_URL=<YOUR_GATEWAY_URL> export ANTHROPIC_AUTH_TOKEN=<YOUR_TOKEN>直接运行 Claude Code 工具。
claude "写一个 Python 的 Hello World"
附录:性能测试对比
通过对Distill-Qwen-7B、QwQ-32B和Qwen2.5-72B三个模型进行测试,发现LLM智能路由在推理服务的速度和吞吐上有显著的性能提升,具体的测试环境和测试结果如下。
以下测试结果仅供参考,实际表现请以您的实际测试结果为准。
测试环境
调动策略:prefix-cache
测试数据: ShareGPT_V3_unfiltered_cleaned_split.json (多轮对话数据集)
推理引擎: vLLM (0.7.3)
后端实例数: 5
测试结果
测试模型 | Distill-Qwen-7B | QwQ-32B | Qwen2.5-72b | ||||||
卡型 | ml.gu8tf.8.40xlarge | ml.gu8tf.8.40xlarge | ml.gu7xf.8xlarge-gu108 | ||||||
并发数 | 500 | 100 | 100 | ||||||
指标 | 无LLM智能路由 | 使用LLM智能路由 | 效果提升 | 无LLM智能路由 | 使用LLM智能路由 | 效果提升 | 无LLM智能路由 | 使用LLM智能路由 | 效果提升 |
Successful requests | 3698 | 3612 | - | 1194 | 1194 | - | 1194 | 1194 | - |
Benchmark duration | 460.79 s | 435.70 s | - | 1418.54 s | 1339.04 s | - | 479.53 s | 456.69 s | - |
Total input tokens | 6605953 | 6426637 | - | 2646701 | 2645010 | - | 1336301 | 1337015 | - |
Total generated tokens | 4898730 | 4750113 | - | 1908956 | 1902894 | - | 924856 | 925208 | - |
Request throughput | 8.03 req/s | 8.29 req/s | +3.2% | 0.84 req/s | 0.89 req/s | +5.95% | 2.49 req/s | 2.61 req/s | +4.8% |
Output token throughput | 10631.17 tok/s | 10902.30 tok/s | +2.5% | 1345.72 tok/s | 1421.08 tok/s | +5.6% | 1928.66 tok/s | 2025.92 tok/s | +5.0% |
Total Token throughput | 24967.33 tok/s | 25652.51 tok/s | +2.7% | 3211.52 tok/s | 3396.38 tok/s | +5.8% | 4715.34 tok/s | 4953.56 tok/s | +5.0% |
Mean TTFT | 532.79 ms | 508.90 ms | +4.5% | 1144.62 ms | 859.42 ms | +25.0% | 508.55 ms | 389.66 ms | +23.4% |
Median TTFT | 274.23 ms | 246.30 ms | - | 749.39 ms | 565.61 ms | - | 325.33 ms | 190.04 ms | - |
P99 TTFT | 3841.49 ms | 3526.62 ms | - | 5339.61 ms | 5027.39 ms | - | 2802.26 ms | 2678.70 ms | - |
Mean TPOT | 40.65 ms | 39.20 ms | +3.5% | 68.78 ms | 65.73 ms | +4.4% | 46.83 ms | 43.97 ms | +4.4% |
Median TPOT | 41.14 ms | 39.61 ms | - | 69.19 ms | 66.33 ms | - | 45.37 ms | 43.30 ms | - |
P99 TPOT | 62.57 ms | 58.71 ms | - | 100.35 ms | 95.55 ms | - | 62.29 ms | 54.79 ms | - |