本文介绍如何使用Pai-Megatron-Patch优化PyTorch版Transformer模型训练。
背景信息
以下所有实验结果均在阿里云ECS服务器上进行,实验使用的ECS配置信息如下。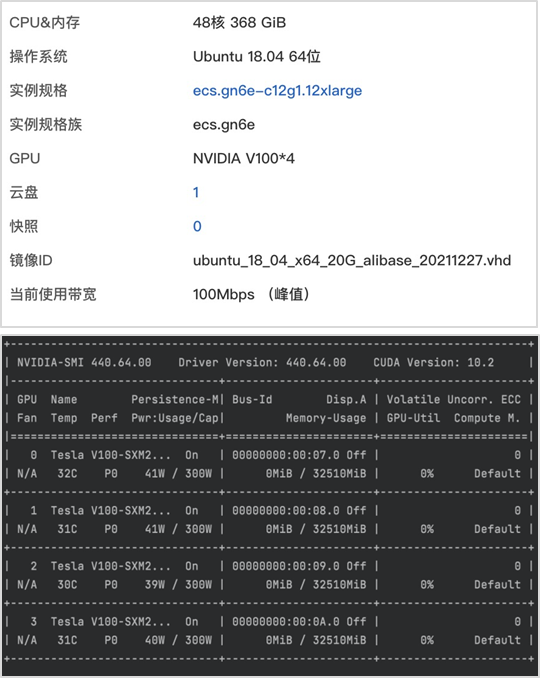
混合精度
实验环境:英文huggingface bert预训练
num-layers 12
hidden-size 768
num-attention-heads 12
num-params 110106428
local-rank 4
seq-length 512
micro-batch-size 16
global-batch-size 64
方案 | 吞吐 (samples/s) | Peak Memory (MB) |
单精度训练 | 103.07 +/- 1.03 | 17025 |
混合精度训练 | 178.15 +/- 2.10 | 12698 |
分布式显存优化:模型状态切分
实验环境:英文megatron gpt预训练
num-layers 24
hidden-size 2048
num-attention-heads 32
num-params 1313722368(13亿)
local-rank 4
seq-length 1024
micro-batch-size 1
global-batch-size 4
使用Pytorch原生的分布式数据并行会导致出现OOM,导致OOM的关键原因是模型无法放在32G的显卡上,因为Adam优化器的状态参数就消耗16G显存。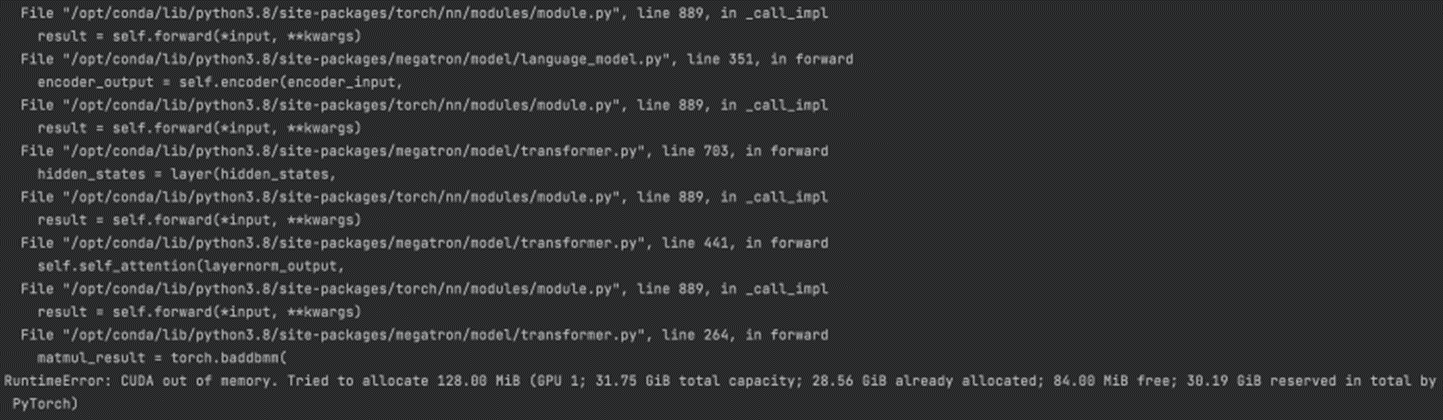
方案 | 吞吐 (samples/s) | Peak Memory (MB) |
无加速技术 | OOM | OOM |
混合精度训练 | 9.57 +/- 0.26 | 25061 |
混合精度训练 + oss模型状态切分 | 6.02 +/- 0.06 | 22077 |
混合精度训练 + oss/sdp模型状态切分 | 7.01 +/- 0.07 | 17113 |
混合精度训练 + fsdp模型状态切分 | NA | NA |
混合精度训练 + Zero-1 | 12.88 +/- 0.10 | 15709 |
混合精度训练 + Zero-2 | 10.27 +/- 0.08 | 15693 |
混合精度训练 + Zero-3 | NA | NA |
3D混合并行
实验环境:英文megatron gpt预训练
num-layers 24
hidden-size 2048
num-attention-heads 32
num-params 1313722368(13亿)
local-rank 4
seq-length 1024
micro-batch-size 1
global-batch-size 4
开启混合精度训练下:
算子拆分 | 流水并行 | 吞吐 (samples/s) | Peak Memory (MB) |
1 | 1 | 9.63 +/- 0.29 | 25061 |
2 | 1 | 7.59 +/- 0.14 | 11300 |
4 | 1 | 6.16 +/- 0.06 | 5673 |
1 | 2 | 8.46 +/- 0.17 | 12375 |
1 | 4 | 8.03 +/- 0.12 | 8141 |
2 | 2 | 7.37 +/- 0.11 | 6211 |
4 | 4 | 6.24 +/- 0.08 | 5673 |
ORT计算图优化
实验环境:英文huggingface bert 微调
num-layers 12
hidden-size 768
num-attention-heads 12
num-params 110106428
local-rank 4
seq-length 512
micro-batch-size 16
global-batch-size 64
提升15.6%:
方案 | 吞吐 (samples/s) | Peak Memory (MB) |
单精度训练 | 479.15 +/- 1.67 | 2112 |
混合精度训练 | 589.66 +/- 4.79 | 2127 |
ORT计算图优化 | 554.24 +/- 1.98 | 2430 |
ORT+混合精度 | 614.70 +/- 8.69 | 2289 |