标量检索是OSS提供的基于Object元数据的索引功能,允许您自定义条件,快速筛选并获取Object列表。可以帮助您更好地管理与了解数据结构,方便您后续查询、统计和管理Object。
使用场景
数据审计场景
通过标量检索,您可以快速定位文件,以满足数据审计或监管需求。例如,在金融服务行业,您可以通过自定义标签、访问权限等元数据进行筛选,从而找到具有特定敏感性级别或特定权限的文件,以提升数据审计的效率。
企业备份与归档场景
企业在进行数据备份和归档时,可以利用标量检索,例如根据文件的创建时间、存储类型或自定义标签等元数据,迅速检索到特定日期或类型的文件,从而快速恢复历史数据或归档记录。
使用限制
地域限制
华东1(杭州)、华东2(上海)、华北1(青岛)、华北2(北京)、华北3(张家口)、华南1(深圳)、华南3(广州)、西南1(成都)、华北6(乌兰察布)、中国香港、新加坡、印度尼西亚(雅加达)、德国(法兰克福)、美国(弗吉尼亚)、美国(硅谷)、英国(伦敦)地域的Bucket支持使用标量检索功能。
Bucket限制
开通标量检索的 Bucket,其包含的文件数量最多为500亿。Bucket内文件数量超过500亿时,可能出现检索性能下降的情况。如需处理更大规模的数据,请联系技术支持进行评估。
分片上传
对于通过分片上传生成的Object,查询结果中只显示已通过CompleteMultipartUpload操作将碎片(Part)合成的完整Object,不显示已初始化但未完成(Complete)或者未中止(Abort)的碎片。
性能参考
OSS 标量检索模式的性能表现如下内容,仅供参考。
存量文件索引生成时间参考
单 Bucket 文件数量 1 亿:4 小时
单 Bucket 文件数量 10 亿:10 小时左右
单 Bucket 文件数量 100 亿:1~3 天左右
单 Bucket 文件数量 200 亿:2~4 天左右
单 Bucket 文件数量 300 亿:3~6 天左右
单 Bucket 文件数量 500 亿:6~10 天左右
若您的 bucket 内文件数量超出 10 亿,且文件携带 Tag,则索引生成的时间会较上述时间更长。
增量文件索引更新时间参考
OSS 默认为标量检索模式额外提供 5000 QPS(即每秒可处理5000个文件索引更新请求),该QPS不占用您 Bucket 的 QoS。当 Bucket 内新增、修改或删除的QPS低于默认值5000时,文件从上传或修改到可被检索的延迟通常在分钟级;若超过默认值5000QPS,您可以通过技术支持联系我们,我们将根据实际情况评估,并提供技术支持。
文件检索响应性能
检索结果返回为秒级,默认超时时间为 30 秒。
开启标量检索
使用OSS控制台
Bucket为华东1(杭州)、华东2(上海)、华北1(青岛)、华北2(北京)、华北3(张家口)、华南1(深圳)、华南3(广州)、西南1(成都)、中国香港、新加坡、印度尼西亚(雅加达)、德国(法兰克福)
登录OSS管理控制台。
单击Bucket 列表,然后单击目标Bucket名称。
在左侧导航栏, 选择。
在数据索引页面,首次使用数据索引功能时,需要按指引完成对 AliyunMetaQueryDefaultRole 角色的授权,以便 OSS 服务能管理 Bucket 中的数据。授权后,单击开通数据索引。
选择标量检索,单击确认开启。
说明开启标量检索需要等待一定的时间,具体等待时长取决于Bucket中Object的数量。
Bucket为英国(伦敦)、华北6(乌兰察布)、美国(弗吉尼亚)、美国(硅谷)地域
登录OSS管理控制台。
单击Bucket 列表,然后单击目标Bucket名称。
在左侧导航栏, 选择。首次使用数据索引功能时,需要按指引完成对 AliyunMetaQueryDefaultRole 角色的授权,以便 OSS 服务能管理 Bucket 中的数据。
开启元数据管理。
说明开启元数据管理需要等待一定的时间,具体等待时长取决于Bucket中Object的数量。
使用阿里云SDK
使用标量检索功能前,您需要为指定Bucket开启元数据管理功能,示例如下。
Java
import com.aliyun.oss.*;
import com.aliyun.oss.common.auth.*;
import com.aliyun.oss.common.comm.SignVersion;
import com.aliyun.oss.model.MetaQueryMode;
public class OpenMetaQuery {
public static void main(String[] args) throws com.aliyuncs.exceptions.ClientException {
// Endpoint以华东1(杭州)为例,其它Region请按实际情况填写。
String endpoint = "https://oss-cn-hangzhou.aliyuncs.com";
// 填写Bucket名称,例如examplebucket。
String bucketName = "examplebucket";
// 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。
EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider();
// 填写Bucket所在地域。以华东1(杭州)为例,Region填写为cn-hangzhou。
String region = "cn-hangzhou";
// 创建OSSClient实例。
//当OSSClient实例不再使用时,调用shutdown方法以释放资源。
ClientBuilderConfiguration clientBuilderConfiguration = new ClientBuilderConfiguration();
clientBuilderConfiguration.setSignatureVersion(SignVersion.V4);
OSS ossClient = OSSClientBuilder.create()
.endpoint(endpoint)
.credentialsProvider(credentialsProvider)
.clientConfiguration(clientBuilderConfiguration)
.region(region)
.build();
try {
// 开启标量检索功能。
ossClient.openMetaQuery(bucketName);
} catch (OSSException oe) {
System.out.println("Error Message:" + oe.getErrorMessage());
System.out.println("Error Code:" + oe.getErrorCode());
System.out.println("Request ID:" + oe.getRequestId());
System.out.println("Host ID:" + oe.getHostId());
} catch (ClientException ce) {
System.out.println("Error Message: " + ce.getMessage());
} finally {
// 关闭OSSClient。
if(ossClient != null){
ossClient.shutdown();
}
}
}
}
Python
import argparse
import alibabacloud_oss_v2 as oss
# 创建命令行参数解析器,并添加描述信息
parser = argparse.ArgumentParser(description="open meta query sample")
# 添加必需的命令行参数 --region,用于指定存储空间所在的区域
parser.add_argument('--region', help='The region in which the bucket is located.', required=True)
# 添加必需的命令行参数 --bucket,用于指定要操作的存储空间名称
parser.add_argument('--bucket', help='The name of the bucket.', required=True)
# 添加可选的命令行参数 --endpoint,用于指定访问OSS时使用的域名
parser.add_argument('--endpoint', help='The domain names that other services can use to access OSS')
def main():
# 解析命令行参数
args = parser.parse_args()
# 从环境变量中加载认证信息
credentials_provider = oss.credentials.EnvironmentVariableCredentialsProvider()
# 使用SDK提供的默认配置
cfg = oss.config.load_default()
# 设置认证信息提供者
cfg.credentials_provider = credentials_provider
# 根据命令行参数设置区域
cfg.region = args.region
# 如果提供了endpoint,则更新配置中的endpoint
if args.endpoint is not None:
cfg.endpoint = args.endpoint
# 创建OSS客户端
client = oss.Client(cfg)
# 发起打开元查询请求
result = client.open_meta_query(oss.OpenMetaQueryRequest(
bucket=args.bucket,
))
# 打印请求的结果状态码和请求ID
print(f'status code: {result.status_code},'
f' request id: {result.request_id},'
)
# 当作为主程序运行时调用main函数
if __name__ == "__main__":
main()
Go
package main
import (
"context"
"flag"
"log"
"github.com/aliyun/alibabacloud-oss-go-sdk-v2/oss"
"github.com/aliyun/alibabacloud-oss-go-sdk-v2/oss/credentials"
)
var (
region string // 定义一个变量来保存从命令行获取的区域(Region)信息
bucketName string // 定义一个变量来保存从命令行获取的存储空间名称
)
// init函数在main函数之前执行,用来初始化程序
func init() {
// 设置命令行参数来指定region
flag.StringVar(®ion, "region", "", "The region in which the bucket is located.")
// 设置命令行参数来指定bucket名称
flag.StringVar(&bucketName, "bucket", "", "The name of the bucket.")
}
func main() {
flag.Parse() // 解析命令行参数
// 检查是否提供了存储空间名称,如果没有提供,则输出默认参数并退出程序
if len(bucketName) == 0 {
flag.PrintDefaults()
log.Fatalf("invalid parameters, bucket name required") // 记录错误并终止程序
}
// 检查是否提供了区域信息,如果没有提供,则输出默认参数并退出程序
if len(region) == 0 {
flag.PrintDefaults()
log.Fatalf("invalid parameters, region required") // 记录错误并终止程序
}
// 创建客户端配置,并使用环境变量作为凭证提供者
cfg := oss.LoadDefaultConfig().
WithCredentialsProvider(credentials.NewEnvironmentVariableCredentialsProvider()).
WithRegion(region)
client := oss.NewClient(cfg) // 使用配置创建一个新的OSS客户端实例
// 构建一个OpenMetaQuery请求,用于开启特定存储空间的元数据管理功能
request := &oss.OpenMetaQueryRequest{
Bucket: oss.Ptr(bucketName), // 指定要操作的存储空间名称
}
result, err := client.OpenMetaQuery(context.TODO(), request) // 执行请求以开启存储空间的元数据管理功能
if err != nil {
log.Fatalf("failed to open meta query %v", err) // 如果有错误发生,记录错误信息并终止程序
}
log.Printf("open meta query result:%#v\n", result) // 打印开启元数据管理的结果
}PHP
<?php
// 引入自动加载文件,确保依赖库能够正确加载
require_once __DIR__ . '/../vendor/autoload.php';
use AlibabaCloud\Oss\V2 as Oss;
// 定义命令行参数的描述信息
$optsdesc = [
"region" => ['help' => 'The region in which the bucket is located.', 'required' => True], // Bucket所在的地域(必填)
"endpoint" => ['help' => 'The domain names that other services can use to access OSS.', 'required' => False], // 访问域名(可选)
"bucket" => ['help' => 'The name of the bucket', 'required' => True], // Bucket名称(必填)
];
// 将参数描述转换为getopt所需的长选项格式
// 每个参数后面加上":"表示该参数需要值
$longopts = \array_map(function ($key) {
return "$key:";
}, array_keys($optsdesc));
// 解析命令行参数
$options = getopt("", $longopts);
// 验证必填参数是否存在
foreach ($optsdesc as $key => $value) {
if ($value['required'] === True && empty($options[$key])) {
$help = $value['help']; // 获取参数的帮助信息
echo "Error: the following arguments are required: --$key, $help" . PHP_EOL;
exit(1); // 如果必填参数缺失,则退出程序
}
}
// 从解析的参数中提取值
$region = $options["region"]; // Bucket所在的地域
$bucket = $options["bucket"]; // Bucket名称
// 加载环境变量中的凭证信息
// 使用EnvironmentVariableCredentialsProvider从环境变量中读取Access Key ID和Access Key Secret
$credentialsProvider = new Oss\Credentials\EnvironmentVariableCredentialsProvider();
// 使用SDK的默认配置
$cfg = Oss\Config::loadDefault();
$cfg->setCredentialsProvider($credentialsProvider); // 设置凭证提供者
$cfg->setRegion($region); // 设置Bucket所在的地域
if (isset($options["endpoint"])) {
$cfg->setEndpoint($options["endpoint"]); // 如果提供了访问域名,则设置endpoint
}
// 创建OSS客户端实例
$client = new Oss\Client($cfg);
// 创建OpenMetaQueryRequest对象,用于开启Bucket的标量检索功能
$request = new Oss\Models\OpenMetaQueryRequest(
bucket: $bucket
);
// 执行开启标量检索功能的操作
$result = $client->openMetaQuery($request);
// 打印开启标量检索功能的结果
printf(
'status code:' . $result->statusCode . PHP_EOL . // HTTP状态码,例如200表示成功
'request id:' . $result->requestId . PHP_EOL // 请求ID,用于调试或追踪请求
);
使用ossutil
以下示例展示了如何开启存储空间examplebucket的元数据管理功能。
ossutil api open-meta-query --bucket examplebucket关于该命令的更多信息,请参见open-meta-query。
发起标量检索
使用OSS控制台
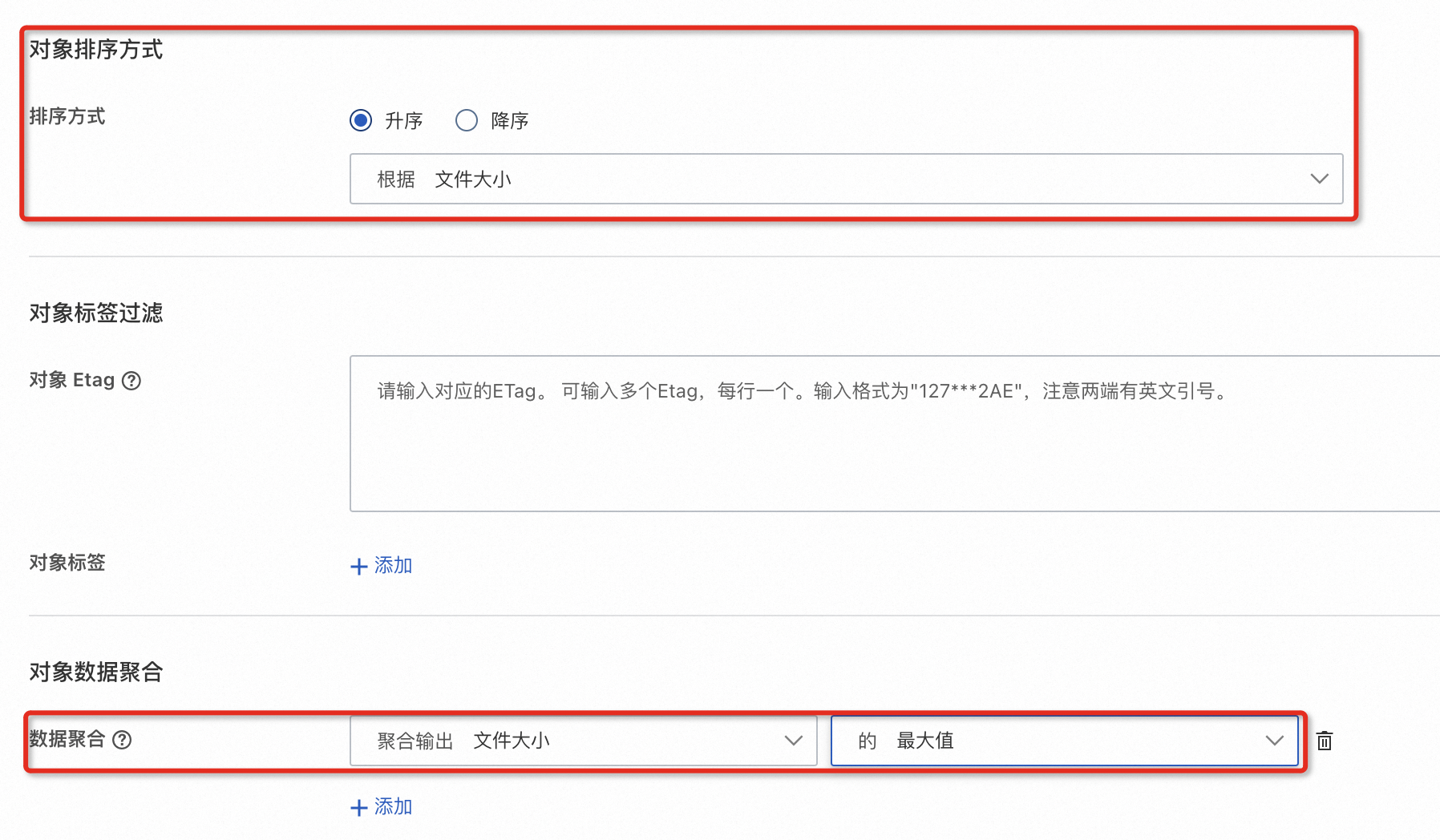
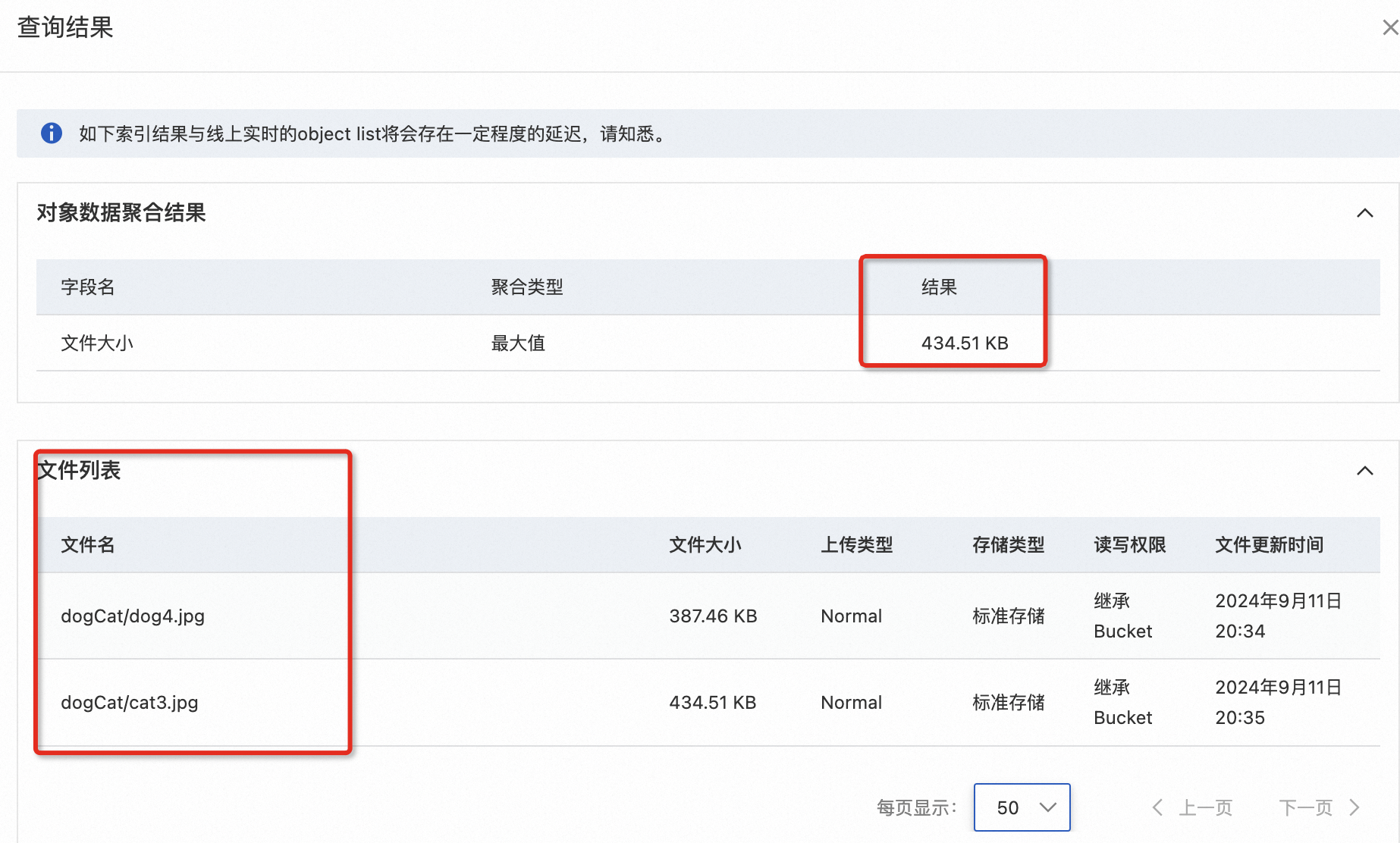
以查找所有文件大小小于500KB,最后更新时间在2024年9月11日0:00至2024年9月12日0:00的文件,输出结果按文件大小升序排列,并按文件大小统计最大值为例:
使用阿里云SDK
通过标量检索功能查询满足指定条件Object,代码示例如下。
Java
如需了解更多代码示例,请参见标量检索(Java SDK)。
import com.aliyun.oss.*;
import com.aliyun.oss.common.auth.*;
import com.aliyun.oss.common.comm.SignVersion;
import com.aliyun.oss.model.*;
import java.util.ArrayList;
import java.util.List;
public class DoMetaQuery {
public static void main(String[] args) throws Exception {
// Endpoint以华东1(杭州)为例,其它Region请按实际情况填写。
String endpoint = "https://oss-cn-hangzhou.aliyuncs.com";
// 填写Bucket名称,例如examplebucket。
String bucketName = "examplebucket";
// 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。
EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider();
// 填写Bucket所在地域。以华东1(杭州)为例,Region填写为cn-hangzhou。
String region = "cn-hangzhou";
// 创建OSSClient实例。
// 当OSSClient实例不再使用时,调用shutdown方法以释放资源。
ClientBuilderConfiguration clientBuilderConfiguration = new ClientBuilderConfiguration();
clientBuilderConfiguration.setSignatureVersion(SignVersion.V4);
OSS ossClient = OSSClientBuilder.create()
.endpoint(endpoint)
.credentialsProvider(credentialsProvider)
.clientConfiguration(clientBuilderConfiguration)
.region(region)
.build();
try {
// 查询满足指定条件的文件(Object),并按照指定字段和排序方式列举文件信息。
int maxResults = 20;
// 指定查询小于1048576字节的文件,且最多返回20个结果,返回结果按升序排列。
String query = "{\"Field\": \"Size\",\"Value\": \"1048576\",\"Operation\": \"lt\"}";
String sort = "Size";
DoMetaQueryRequest doMetaQueryRequest = new DoMetaQueryRequest(bucketName, maxResults, query, sort);
Aggregation aggregationRequest = new Aggregation();
Aggregations aggregations = new Aggregations();
List<Aggregation> aggregationList = new ArrayList<Aggregation>();
// 指定聚合操作的字段名称。
aggregationRequest.setField("Size");
// 指定聚合操作的操作符,max表示最大值。
aggregationRequest.setOperation("max");
aggregationList.add(aggregationRequest);
aggregations.setAggregation(aggregationList);
// 设置聚合操作。
doMetaQueryRequest.setAggregations(aggregations);
doMetaQueryRequest.setOrder(SortOrder.ASC);
DoMetaQueryResult doMetaQueryResult = ossClient.doMetaQuery(doMetaQueryRequest);
if(doMetaQueryResult.getFiles() != null){
for(ObjectFile file : doMetaQueryResult.getFiles().getFile()){
System.out.println("Filename: " + file.getFilename());
// 获取标识Object的内容。
System.out.println("ETag: " + file.getETag());
// 获取Object的访问权限
System.out.println("ObjectACL: " + file.getObjectACL());
// 获取Object的类型。
System.out.println("OssObjectType: " + file.getOssObjectType());
// 获取Object的存储类型。
System.out.println("OssStorageClass: " + file.getOssStorageClass());
// 获取Object的标签个数。
System.out.println("TaggingCount: " + file.getOssTaggingCount());
if(file.getOssTagging() != null){
for(Tagging tag : file.getOssTagging().getTagging()){
System.out.println("Key: " + tag.getKey());
System.out.println("Value: " + tag.getValue());
}
}
if(file.getOssUserMeta() != null){
for(UserMeta meta : file.getOssUserMeta().getUserMeta()){
System.out.println("Key: " + meta.getKey());
System.out.println("Value: " + meta.getValue());
}
}
}
} else if(doMetaQueryResult.getAggregations() != null){
for(Aggregation aggre : doMetaQueryResult.getAggregations().getAggregation()){
// 获取聚合字段名称。
System.out.println("Field: " + aggre.getField());
// 获取聚合字段的操作符。
System.out.println("Operation: " + aggre.getOperation());
// 获取聚合操作的结果值。
System.out.println("Value: " + aggre.getValue());
if(aggre.getGroups() != null && aggre.getGroups().getGroup().size() > 0){
// 获取分组聚合的值。
System.out.println("Groups value: " + aggre.getGroups().getGroup().get(0).getValue());
// 获取分组聚合的总个数。
System.out.println("Groups count: " + aggre.getGroups().getGroup().get(0).getCount());
}
}
} else {
System.out.println("NextToken: " + doMetaQueryResult.getNextToken());
}
} catch (OSSException oe) {
System.out.println("Error Message:" + oe.getErrorMessage());
System.out.println("Error Code:" + oe.getErrorCode());
System.out.println("Request ID:" + oe.getRequestId());
System.out.println("Host ID:" + oe.getHostId());
} catch (ClientException ce) {
System.out.println("Error Message: " + ce.getMessage());
} finally {
// 关闭OSSClient。
ossClient.shutdown();
}
}
}
Python
如需了解更多代码示例,请参见标量检索。
import argparse
import alibabacloud_oss_v2 as oss
# 创建一个命令行参数解析器,用于接收用户输入的参数
parser = argparse.ArgumentParser(description="do meta query sample")
parser.add_argument('--region', help='The region in which the bucket is located.', required=True)
parser.add_argument('--bucket', help='The name of the bucket.', required=True)
parser.add_argument('--endpoint', help='The domain names that other services can use to access OSS')
def main():
# 解析命令行参数
args = parser.parse_args()
# 从环境变量中加载认证信息
credentials_provider = oss.credentials.EnvironmentVariableCredentialsProvider()
# 使用SDK的默认配置
cfg = oss.config.load_default()
# 设置认证提供者
cfg.credentials_provider = credentials_provider
# 根据传入参数设置区域
cfg.region = args.region
# 如果提供了endpoint,则更新配置中的endpoint
if args.endpoint is not None:
cfg.endpoint = args.endpoint
# 创建OSS客户端
client = oss.Client(cfg)
# 执行元数据查询操作
result = client.do_meta_query(oss.DoMetaQueryRequest(
bucket=args.bucket, # 指定要查询的存储空间
meta_query=oss.MetaQuery( # 定义查询的具体内容
aggregations=oss.MetaQueryAggregations( # 定义聚合操作
aggregations=[ # 聚合列表
oss.MetaQueryAggregation( # 第一个聚合:计算总大小
field='Size',
operation='sum',
),
oss.MetaQueryAggregation( # 第二个聚合:找出最大值
field='Size',
operation='max',
)
],
),
next_token='', # 分页标记
max_results=80369, # 返回的最大结果数
query='{"Field": "Size","Value": "1048576","Operation": "gt"}', # 查询条件
sort='Size', # 排序字段
order=oss.MetaQueryOrderType.DESC, # 排序方式
),
))
# 输出查询结果的基本信息
print(f'status code: {result.status_code},'
f' request id: {result.request_id},'
# 下面这些注释掉的部分可以根据需要开启来获取更详细的信息
# f' files: {result.files},'
# f' file: {result.files.file},'
# f' file modified time: {result.files.file.file_modified_time},'
# f' etag: {result.files.file.etag},'
# f' server side encryption: {result.files.file.server_side_encryption},'
# f' oss tagging count: {result.files.file.oss_tagging_count},'
# f' oss tagging: {result.files.file.oss_tagging},'
# f' key: {result.files.file.oss_tagging.taggings[0].key},'
# f' value: {result.files.file.oss_tagging.taggings[0].value},'
# f' key: {result.files.file.oss_tagging.taggings[1].key},'
# f' value: {result.files.file.oss_tagging.taggings[1].value},'
# f' oss user meta: {result.files.file.oss_user_meta},'
# f' key: {result.files.file.oss_user_meta.user_metas[0].key},'
# f' value: {result.files.file.oss_user_meta.user_metas[0].value},'
# f' key: {result.files.file.oss_user_meta.user_metas[1].key},'
# f' value: {result.files.file.oss_user_meta.user_metas[1].value},'
# f' filename: {result.files.file.filename},'
# f' size: {result.files.file.size},'
# f' oss object type: {result.files.file.oss_object_type},'
# f' oss storage class: {result.files.file.oss_storage_class},'
# f' object acl: {result.files.file.object_acl},'
# f' oss crc64: {result.files.file.oss_crc64},'
# f' server side encryption customer algorithm: {result.files.file.server_side_encryption_customer_algorithm},'
# f' aggregations: {result.aggregations},'
f' field: {result.aggregations.aggregations[0].field},'
f' operation: {result.aggregations.aggregations[0].operation},'
f' field: {result.aggregations.aggregations[1].field},'
f' operation: {result.aggregations.aggregations[1].operation},'
f' next token: {result.next_token},'
)
# 如果存在文件信息,则打印标签和用户自定义元数据
if result.files:
if result.files.file.oss_tagging.taggings:
for r in result.files.file.oss_tagging.taggings:
print(f'result: key: {r.key}, value: {r.value}')
if result.files.file.oss_user_meta.user_metas:
for r in result.files.file.oss_user_meta.user_metas:
print(f'result: key: {r.key}, value: {r.value}')
# 打印所有聚合的结果
if result.aggregations.aggregations:
for r in result.aggregations.aggregations:
print(f'result: field: {r.field}, operation: {r.operation}')
if __name__ == "__main__":
main()
Go
如需了解更多代码示例,请参见标量检索(Go SDK V2)。
package main
import (
"context"
"flag"
"fmt"
"log"
"github.com/aliyun/alibabacloud-oss-go-sdk-v2/oss"
"github.com/aliyun/alibabacloud-oss-go-sdk-v2/oss/credentials"
)
var (
region string // 定义一个变量来保存从命令行获取的区域(Region)信息
bucketName string // 定义一个变量来保存从命令行获取的存储空间名称
)
// init函数在main函数之前执行,用来初始化程序
func init() {
// 设置命令行参数来指定region,默认为空字符串
flag.StringVar(®ion, "region", "", "The region in which the bucket is located.")
// 设置命令行参数来指定bucket名称,默认为空字符串
flag.StringVar(&bucketName, "bucket", "", "The name of the bucket.")
}
func main() {
flag.Parse() // 解析命令行参数
// 检查是否提供了存储空间名称,如果没有提供,则输出默认参数并退出程序
if len(bucketName) == 0 {
flag.PrintDefaults()
log.Fatalf("invalid parameters, bucket name required")
}
// 检查是否提供了区域信息,如果没有提供,则输出默认参数并退出程序
if len(region) == 0 {
flag.PrintDefaults()
log.Fatalf("invalid parameters, region required")
}
// 创建客户端配置,并使用环境变量作为凭证提供者和指定的区域
cfg := oss.LoadDefaultConfig().
WithCredentialsProvider(credentials.NewEnvironmentVariableCredentialsProvider()).
WithRegion(region)
client := oss.NewClient(cfg) // 使用配置创建一个新的OSS客户端实例
// 构建一个DoMetaQuery请求,用于执行元数据查询满足指定条件Object
request := &oss.DoMetaQueryRequest{
Bucket: oss.Ptr(bucketName), // 指定要查询的存储空间名称
MetaQuery: &oss.MetaQuery{
Query: oss.Ptr(`{"Field": "Size","Value": "1048576","Operation": "gt"}`), // 查询条件:大小大于1MB的对象
Sort: oss.Ptr("Size"), // 排序字段:按对象大小排序
Order: oss.Ptr(oss.MetaQueryOrderAsc), // 排序顺序:升序
},
}
result, err := client.DoMetaQuery(context.TODO(), request) // 发送请求以执行元数据查询
if err != nil {
log.Fatalf("failed to do meta query %v", err)
}
// 打印NextToken,用于分页查询下一页的数据
fmt.Printf("NextToken:%s\n", *result.NextToken)
// 遍历返回的结果,打印出每个文件的详细信息
for _, file := range result.Files {
fmt.Printf("File name: %s\n", *file.Filename)
fmt.Printf("size: %d\n", file.Size)
fmt.Printf("File Modified Time:%s\n", *file.FileModifiedTime)
fmt.Printf("Oss Object Type:%s\n", *file.OSSObjectType)
fmt.Printf("Oss Storage Class:%s\n", *file.OSSStorageClass)
fmt.Printf("Object ACL:%s\n", *file.ObjectACL)
fmt.Printf("ETag:%s\n", *file.ETag)
fmt.Printf("Oss CRC64:%s\n", *file.OSSCRC64)
if file.OSSTaggingCount != nil {
fmt.Printf("Oss Tagging Count:%d\n", *file.OSSTaggingCount)
}
// 打印对象的标签信息
for _, tagging := range file.OSSTagging {
fmt.Printf("Oss Tagging Key:%s\n", *tagging.Key)
fmt.Printf("Oss Tagging Value:%s\n", *tagging.Value)
}
// 打印用户自定义元数据信息
for _, userMeta := range file.OSSUserMeta {
fmt.Printf("Oss User Meta Key:%s\n", *userMeta.Key)
fmt.Printf("Oss User Meta Key Value:%s\n", *userMeta.Value)
}
}
}
PHP
如需了解更多代码示例,请参见标量检索(PHP SDK V2)。
<?php
// 引入自动加载文件,确保依赖库能够正确加载
require_once __DIR__ . '/../vendor/autoload.php';
use AlibabaCloud\Oss\V2 as Oss;
// 定义命令行参数的描述信息
$optsdesc = [
"region" => ['help' => 'The region in which the bucket is located.', 'required' => True], // Bucket所在的地域(必填)
"endpoint" => ['help' => 'The domain names that other services can use to access OSS.', 'required' => False], // 访问域名(可选)
"bucket" => ['help' => 'The name of the bucket', 'required' => True], // Bucket名称(必填)
];
// 将参数描述转换为getopt所需的长选项格式
// 每个参数后面加上":"表示该参数需要值
$longopts = \array_map(function ($key) {
return "$key:";
}, array_keys($optsdesc));
// 解析命令行参数
$options = getopt("", $longopts);
// 验证必填参数是否存在
foreach ($optsdesc as $key => $value) {
if ($value['required'] === True && empty($options[$key])) {
$help = $value['help']; // 获取参数的帮助信息
echo "Error: the following arguments are required: --$key, $help" . PHP_EOL;
exit(1); // 如果必填参数缺失,则退出程序
}
}
// 从解析的参数中提取值
$region = $options["region"]; // Bucket所在的地域
$bucket = $options["bucket"]; // Bucket名称
// 加载环境变量中的凭证信息
// 使用EnvironmentVariableCredentialsProvider从环境变量中读取Access Key ID和Access Key Secret
$credentialsProvider = new Oss\Credentials\EnvironmentVariableCredentialsProvider();
// 使用SDK的默认配置
$cfg = Oss\Config::loadDefault();
$cfg->setCredentialsProvider($credentialsProvider); // 设置凭证提供者
$cfg->setRegion($region); // 设置Bucket所在的地域
if (isset($options["endpoint"])) {
$cfg->setEndpoint($options["endpoint"]); // 如果提供了访问域名,则设置endpoint
}
// 创建OSS客户端实例
$client = new Oss\Client($cfg);
// 创建DoMetaQueryRequest对象,用于执行元数据查询操作
$request = new \AlibabaCloud\Oss\V2\Models\DoMetaQueryRequest(
bucket: $bucket,
metaQuery: new \AlibabaCloud\Oss\V2\Models\MetaQuery(
maxResults: 5, // 最大返回结果数量
query: "{'Field': 'Size','Value': '1048576','Operation': 'gt'}", // 查询条件:大小大于1MB的对象
sort: 'Size', // 按照对象大小排序
order: \AlibabaCloud\Oss\V2\Models\MetaQueryOrderType::ASC, // 升序排序
aggregations: new \AlibabaCloud\Oss\V2\Models\MetaQueryAggregations( // 聚合操作
aggregations: [
new \AlibabaCloud\Oss\V2\Models\MetaQueryAggregation(
field: 'Size', // 对象大小字段
operation: 'sum' // 聚合操作:求和
),
new \AlibabaCloud\Oss\V2\Models\MetaQueryAggregation(
field: 'Size', // 对象大小字段
operation: 'max' // 聚合操作:求最大值
),
]
)
)
);
// 执行元数据查询操作
$result = $client->doMetaQuery($request);
// 打印元数据查询的结果
printf(
'status code:' . $result->statusCode . PHP_EOL . // HTTP状态码,例如200表示成功
'request id:' . $result->requestId . PHP_EOL . // 请求ID,用于调试或追踪请求
'result:' . var_export($result, true) . PHP_EOL // 查询结果,包含匹配的对象及其聚合数据
);
使用ossutil
您可以使用命令行工具ossutil通过标量检索功能查询满足指定条件的Object,ossutil的安装请参见安装ossutil。
以下示例展示了如何查询存储空间examplebucket中满足指定条件的文件。
ossutil api do-meta-query --bucket examplebucket --meta-query "{\"MaxResults\":\"5\",\"Query\":\"{\\\"Field\\\": \\\"Size\\\",\\\"Value\\\": \\\"1048576\\\",\\\"Operation\\\": \\\"gt\\\"}\",\"Sort\":\"Size\",\"Order\":\"asc\",\"Aggregations\":{\"Aggregation\":[{\"Field\":\"Size\",\"Operation\":\"sum\"},{\"Field\":\"Size\",\"Operation\":\"max\"}]}}"关于该命令的更多信息,请参见do-meta-query。
关闭标量检索
关闭该功能不会影响您 OSS 中已存储的数据。若后续重新开启,系统将重新扫描存量文件并构建索引,需要一定等待时间,具体时间取决于您的文件数量。
功能关闭后的下一小时会停止计费,但出账会有一定延迟,请及时关注账单金额。
使用OSS控制台
登录OSS管理控制台,在数据索引功能页,单击元数据管理右侧关闭,按提示确认关闭即可。

使用阿里云SDK
Java
如需了解更多代码示例,请参见标量检索(Java SDK)。
import com.aliyun.oss.*;
import com.aliyun.oss.common.auth.*;
import com.aliyun.oss.common.comm.SignVersion;
public class CloseMetaQuery {
public static void main(String[] args) throws Exception {
// Endpoint以华东1(杭州)为例,其它Region请按实际情况填写。
String endpoint = "https://oss-cn-hangzhou.aliyuncs.com";
// 填写Bucket名称,例如examplebucket。
String bucketName = "examplebucket";
// 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。
EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider();
// 填写Bucket所在地域。以华东1(杭州)为例,Region填写为cn-hangzhou。
String region = "cn-hangzhou";
// 创建OSSClient实例。
// 当OSSClient实例不再使用时,调用shutdown方法以释放资源。
ClientBuilderConfiguration clientBuilderConfiguration = new ClientBuilderConfiguration();
clientBuilderConfiguration.setSignatureVersion(SignVersion.V4);
OSS ossClient = OSSClientBuilder.create()
.endpoint(endpoint)
.credentialsProvider(credentialsProvider)
.clientConfiguration(clientBuilderConfiguration)
.region(region)
.build();
try {
// 关闭存储空间(Bucket)的标量检索功能。
ossClient.closeMetaQuery(bucketName);
} catch (OSSException oe) {
System.out.println("Error Message:" + oe.getErrorMessage());
System.out.println("Error Code:" + oe.getErrorCode());
System.out.println("Request ID:" + oe.getRequestId());
System.out.println("Host ID:" + oe.getHostId());
} catch (ClientException ce) {
System.out.println("Error Message: " + ce.getMessage());
} finally {
// 关闭OSSClient。
if(ossClient != null){
ossClient.shutdown();
}
}
}
}
Python
如需了解更多代码示例,请参见标量检索。
import argparse
import alibabacloud_oss_v2 as oss
# 创建一个ArgumentParser对象,用于处理命令行参数
parser = argparse.ArgumentParser(description="close meta query sample")
parser.add_argument('--region', help='The region in which the bucket is located.', required=True)
parser.add_argument('--bucket', help='The name of the bucket.', required=True)
parser.add_argument('--endpoint', help='The domain names that other services can use to access OSS')
def main():
# 解析命令行参数
args = parser.parse_args()
# 从环境变量中加载凭据信息
credentials_provider = oss.credentials.EnvironmentVariableCredentialsProvider()
# 使用SDK的默认配置
cfg = oss.config.load_default()
# 设置凭据提供者为从环境变量获取的凭据
cfg.credentials_provider = credentials_provider
# 设置配置中的区域信息
cfg.region = args.region
# 如果提供了endpoint,则设置配置中的endpoint
if args.endpoint is not None:
cfg.endpoint = args.endpoint
# 创建OSS客户端
client = oss.Client(cfg)
# 调用close_meta_query方法关闭指定存储空间的元数据查询功能
result = client.close_meta_query(oss.CloseMetaQueryRequest(
bucket=args.bucket,
))
# 打印响应的状态码和请求ID
print(f'status code: {result.status_code}, request id: {result.request_id}')
# 当此脚本直接运行时执行main函数
if __name__ == "__main__":
main()
Go
如需了解更多代码示例,请参见标量检索(Go SDK V2)。
package main
import (
"context"
"flag"
"log"
"github.com/aliyun/alibabacloud-oss-go-sdk-v2/oss"
"github.com/aliyun/alibabacloud-oss-go-sdk-v2/oss/credentials"
)
var (
region string // 定义一个变量来保存从命令行获取的区域(Region)信息
bucketName string // 定义一个变量来保存从命令行获取的存储空间名称
)
// init函数在main函数之前执行,用来初始化程序
func init() {
// 设置命令行参数来指定region
flag.StringVar(®ion, "region", "", "The region in which the bucket is located.")
// 设置命令行参数来指定bucket名称
flag.StringVar(&bucketName, "bucket", "", "The name of the bucket.")
}
func main() {
flag.Parse() // 解析命令行参数
// 检查是否提供了存储空间名称,如果没有提供,则输出默认参数并退出程序
if len(bucketName) == 0 {
flag.PrintDefaults()
log.Fatalf("invalid parameters, bucket name required") // 记录错误并终止程序
}
// 检查是否提供了区域信息,如果没有提供,则输出默认参数并退出程序
if len(region) == 0 {
flag.PrintDefaults()
log.Fatalf("invalid parameters, region required") // 记录错误并终止程序
}
// 创建客户端配置,并使用环境变量作为凭证提供者和指定的区域
cfg := oss.LoadDefaultConfig().
WithCredentialsProvider(credentials.NewEnvironmentVariableCredentialsProvider()).
WithRegion(region)
client := oss.NewClient(cfg) // 创建一个新的OSS客户端实例
// 构建一个CloseMetaQuery请求,用于关闭特定存储空间的元数据管理功能
request := &oss.CloseMetaQueryRequest{
Bucket: oss.Ptr(bucketName), // 指定要操作的存储空间名称
}
result, err := client.CloseMetaQuery(context.TODO(), request) // 执行请求以关闭存储空间的元数据管理功能
if err != nil {
log.Fatalf("failed to close meta query %v", err) // 如果有错误发生,记录错误信息并终止程序
}
log.Printf("close meta query result:%#v\n", result)
}PHP
如需了解更多代码示例,请参见标量检索(PHP SDK V2)。
<?php
// 引入自动加载文件,确保依赖库能够正确加载
require_once __DIR__ . '/../vendor/autoload.php';
use AlibabaCloud\Oss\V2 as Oss;
// 定义命令行参数的描述信息
$optsdesc = [
"region" => ['help' => 'The region in which the bucket is located.', 'required' => True], // Bucket所在的地域(必填)
"endpoint" => ['help' => 'The domain names that other services can use to access OSS.', 'required' => False], // 访问域名(可选)
"bucket" => ['help' => 'The name of the bucket', 'required' => True], // Bucket名称(必填)
];
// 将参数描述转换为getopt所需的长选项格式
// 每个参数后面加上":"表示该参数需要值
$longopts = \array_map(function ($key) {
return "$key:";
}, array_keys($optsdesc));
// 解析命令行参数
$options = getopt("", $longopts);
// 验证必填参数是否存在
foreach ($optsdesc as $key => $value) {
if ($value['required'] === True && empty($options[$key])) {
$help = $value['help']; // 获取参数的帮助信息
echo "Error: the following arguments are required: --$key, $help" . PHP_EOL;
exit(1); // 如果必填参数缺失,则退出程序
}
}
// 从解析的参数中提取值
$region = $options["region"]; // Bucket所在的地域
$bucket = $options["bucket"]; // Bucket名称
// 加载环境变量中的凭证信息
// 使用EnvironmentVariableCredentialsProvider从环境变量中读取Access Key ID和Access Key Secret
$credentialsProvider = new Oss\Credentials\EnvironmentVariableCredentialsProvider();
// 使用SDK的默认配置
$cfg = Oss\Config::loadDefault();
$cfg->setCredentialsProvider($credentialsProvider); // 设置凭证提供者
$cfg->setRegion($region); // 设置Bucket所在的地域
if (isset($options["endpoint"])) {
$cfg->setEndpoint($options["endpoint"]); // 如果提供了访问域名,则设置endpoint
}
// 创建OSS客户端实例
$client = new Oss\Client($cfg);
// 创建CloseMetaQueryRequest对象,用于关闭Bucket的检索功能
$request = new \AlibabaCloud\Oss\V2\Models\CloseMetaQueryRequest(
bucket: $bucket
);
// 执行关闭检索功能的操作
$result = $client->closeMetaQuery($request);
// 打印关闭检索功能的结果
printf(
'status code:' . $result->statusCode . PHP_EOL . // HTTP状态码,例如200表示成功
'request id:' . $result->requestId . PHP_EOL // 请求ID,用于调试或追踪请求
);
使用ossutil
以下示例展示了如何关闭存储空间examplebucket的元数据管理功能。命令示例如下:
ossutil api close-meta-query --bucket examplebucket关于该命令的更多信息,请参见close-meta-query。
检索条件及输出设置
检索条件
以下是完整的检索条件,您可以根据需要进行单独或组合设置。
结果输出设置
您可对输出结果进行排序和简单统计。
对象排序方式:支持根据最后修改时间、文件名和文件大小进行升序、降序及默认排序。您可以按需选择并排序检索结果,便于快速找到所需文件。
数据聚合:支持多种输出类型,您可以对检索结果进行去重统计、分组计数、最大值、最小值、平均值和求和等计算,便于高效分析和管理数据。
相关API
以上操作方式底层基于API实现,如果您的程序自定义要求较高,您可以直接发起REST API请求。直接发起REST API请求需要手动编写代码计算签名。
关于开启元数据管理功能的更多信息,请参见OpenMetaQuery。
关于查询满足指定条件的文件,请参见DoMetaQuery。
关于关闭元数据管理功能的更多信息,请参见CloseMetaQuery。
计费说明
标量检索费用主要来自以下两个方面:
标量检索功能计费项(公测期间免费)
包括Object的元数据管理费用。当前处于公测阶段暂不计费,将于 2025 年 8 月 25 日公测结束后正式计费。公测结束后将按OSS数据索引定价标准计费,详见数据索引费用。
API请求费用
在增量文件索引更新期间会产生API请求费用,按照API调用次数收费。涉及的API请求如下:
行为
API
次数
为Bucket中的文件构建索引
HeadObject和GetObject
每个文件调用1次
Bucket中文件存在Tag
GetObjectTag
每个携带Tag的文件调用1次
Bucket中文件携带自定义Meta
GetObjectMeta
每个携带自定义Meta的文件调用1次
Bucket中存在软链接文件
GetSymlink
每个携带软链接的文件调用1次
扫描Bucket中的文件
ListObjects
每扫描1000个文件调用1次
关于OSS API的请求费用,请参见请求费用。
如您希望停止相关计费,请及时关闭标量检索。
常见问题
Bucket内文件数量达到上亿级别时,为什么很长时间都没有成功建立数据索引?
1秒内大约可以为600个增量文件建立索引。您可以结合Bucket内的文件数量,预估建立索引所需时间。
如何查询指定前缀/目录下的文件总大小?
登录OSS管理控制台。
单击Bucket 列表,然后单击目标Bucket名称。
在左侧导航栏, 选择。
将文件名设置为前缀匹配,并输入前缀匹配:
random_files/,其他参数保留默认设置。
设置输出方式。
对象排序方式选择按照默认排序排列。
数据聚合选择按照文件大小的求和输出。

单击立即查询,可以看到最终统计到的random_files/目录下所有文件和总大小结果。

相关文档
标量检索支持多项过滤条件,例如文件最后修改时间、存储类型、读写权限、文件大小等。如果您希望从OSS Bucket的海量Object中筛选出指定时间范围内的Object,请参见如何筛选OSS指定时间范围内的文件。