以阿里云 OSS 为统一存储底座,结合 Lance 列式格式与 Ray 分布式计算框架,构建一条端到端的向量数据处理流水线,覆盖数据写入、分布式 Embedding、向量与全文索引构建、混合检索、数据维护等核心环节。该方案适用于 RAG 知识库、多模态搜索、推荐系统等需处理百万级以上向量数据的 AI 工程场景,可满足大数据规模、Embedding 计算密集、检索延迟敏感、存储成本可控的共性诉求。
方案概览
以企业知识库 RAG 向量化处理流程为例,演示完整方案的落地。先了解方案优势与架构,准备 ECS、OSS、Ray 集群等前提条件,再配置 OSS 作为 Lance 存储后端,然后按以下步骤构建分布式向量数据处理流水线:
准备统一配置模块:将存储与计算参数集中到
config.py,供后续步骤共享。准备原始数据集:将原始文本以 Lance 格式写入 OSS。
分布式生成 Embedding 向量:在 Ray 集群上并行调用模型生成向量,并写回 OSS。
分布式构建向量索引并执行 ANN 搜索:在 OSS 上构建 IVF_PQ 向量索引并验证检索效果。
构建全文索引并执行混合搜索:通过 RRF 融合向量与关键词检索结果。
数据维护:进行增量追加、分布式 Compaction、版本管理与时间旅行。
典型应用场景:
RAG(检索增强生成):将企业知识库切片后向量化,支撑 LLM 实时检索引用。
多模态搜索:对图片、视频、音频生成 Embedding 并提供相似性检索。
推荐系统:用户行为与物品特征向量化后实时匹配。
方案优势
为什么使用阿里云 OSS
维度 | OSS 提供的能力 |
双协议接入 | 支持 S3 兼容协议( |
高性能 | 单 Bucket 提供超高 QPS 与带宽,与 Lance 列式随机读取的访问模式天然契合。 |
低成本 | 标准存储按量计费;Lance MVCC 零拷贝版本机制使新旧版本共享数据文件,几乎不产生额外存储开销。 |
弹性伸缩 | 容量从 GB 到 TB 级自动扩展,配合 ECS 计算资源按需扩缩。 |
数据湖生态 | 作为阿里云数据湖统一存储底座,可与 MaxCompute、EMR、PAI 等大数据与 AI 服务无缝协同。 |
数据安全 | 在 Lance 自身 MVCC 版本控制基础上,可叠加 OSS 服务端加密、访问控制策略等机制。 |
数据集直接驻留在 OSS 上,计算节点无需配置数据盘,实现真正的存算分离:ECS 节点可随时弹性扩缩,数据始终安全持久地保存在 OSS 中。
为什么使用 Lance 格式
Lance 是专为 ML/AI 工作负载优化的列式数据格式。相比 Parquet 等传统格式:
随机访问性能优:O(1) 行级随机访问,远快于基于 Row Group 的格式。
原生支持向量类型:内置高维向量列与 ANN 索引(IVF_PQ、IVF_HNSW 等)。
支持全文检索:内置倒排索引,可与向量检索组合使用(Hybrid Search)。
零拷贝版本控制:每次写入自动创建版本快照,支持时间旅行;新旧版本共享未变更数据文件。
云原生:原生支持 S3/OSS 对象存储,数据无需落本地磁盘。
为什么使用 Ray
当数据量达到百万、千万级时,单机处理 Embedding 与索引构建会成为瓶颈。Ray 是通用分布式计算框架,天然适配数据密集型 AI 负载:
流水线并行:Ray Data 提供流式 Pipeline,将”读取 → 计算 → 写入”三阶段并行执行。
Actor Pool 模型常驻:Embedding 模型实例以 Ray Actor 形式常驻 Worker,避免每个 batch 重复加载模型。
分布式索引构建:通过
lance-ray将向量索引、全文索引按 fragment 切分并行构建。资源弹性:Ray 自动管理 Worker 生命周期与资源分配,集群规模可按业务需要灵活调整。
Lance 官方提供 lance-ray 集成库,封装了 Lance 数据集的分布式读写、索引构建、Compaction 等能力,开箱即用。
配置 OSS 作为 Lance 存储后端
Lance 通过 S3 兼容协议或 OSS 原生协议访问阿里云 OSS。本节配置适用于所有 Lance + OSS 场景,不限于 Ray 分布式环境。
S3 兼容协议(推荐)
Lance 通过 S3 兼容接口访问 OSS,底层使用 object_store crate 实现。
通过 S3 兼容协议访问 OSS 前,请联系技术支持申请为目标 Bucket 开通 S3 兼容访问能力,未开通时请求会被拒绝。
关键配置约束:
endpoint 格式:
https://<bucket>.oss-<region>-internal.aliyuncs.com(包含 bucket 名)。必须设置
virtual_hosted_style_request: "true"。数据集 URI 格式:
s3://<bucket>/path/to/dataset.lance。
基础配置:
storage_options = {
"region": "cn-hangzhou",
"endpoint": "https://<bucket>.oss-cn-hangzhou-internal.aliyuncs.com",
"access_key_id": "...",
"secret_access_key": "...",
"virtual_hosted_style_request": "true",
}调优配置:在大数据量写入或索引构建场景下,建议显式设置超时与重试参数。以下为参考值,可根据实际网络环境与数据规模调整:
storage_options = {
"region": "cn-hangzhou",
"endpoint": "https://<bucket>.oss-cn-hangzhou-internal.aliyuncs.com",
"access_key_id": "...",
"secret_access_key": "...",
"virtual_hosted_style_request": "true",
"request_timeout": "120s",
"connect_timeout": "10s",
"client_max_retries": "15",
}OSS 原生协议
通过 OSS 原生接口访问,底层基于 Apache OpenDAL 实现,无需额外申请。
OSS 原生协议仅适用于从未开启过版本控制(Versioning)功能的 Bucket;若 Bucket 曾开启过版本控制,请使用 S3 兼容协议。
关键配置约束:
endpoint 格式:
https://oss-<region>-internal.aliyuncs.com(不含 bucket 名)。数据集 URI 格式:
oss://<bucket>/path/to/dataset.lance。
配置示例:
storage_options = {
"oss_endpoint": "https://oss-cn-hangzhou-internal.aliyuncs.com",
"oss_access_key_id": "...",
"oss_secret_access_key": "...",
"oss_region": "cn-hangzhou",
}架构总览
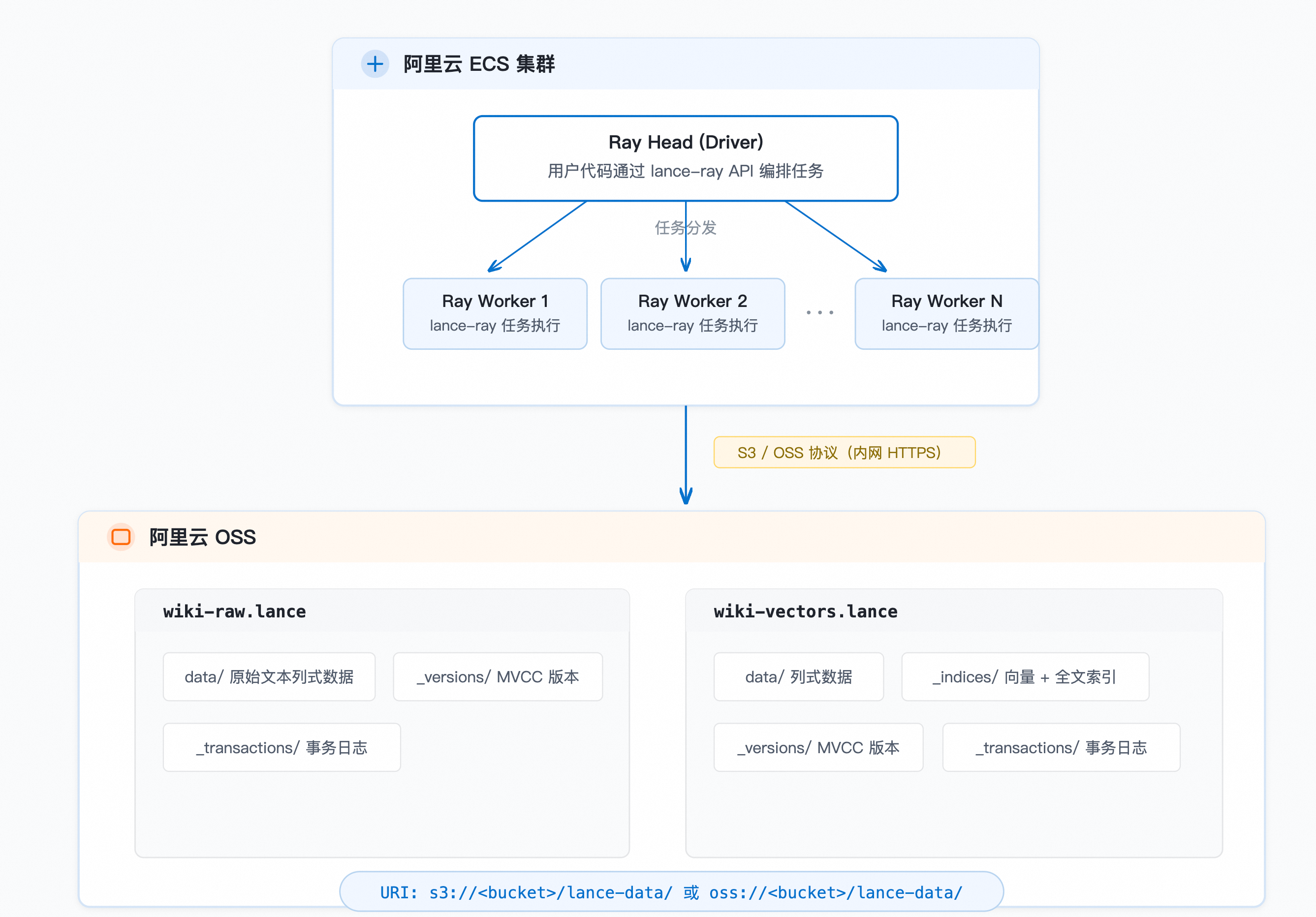
数据流:原始文本 → 以 Lance 格式写入 OSS → Ray 集群分布式 Embedding → 向量数据写回 OSS → 分布式构建索引 → 向量/全文/混合搜索。
前提条件
阿里云 ECS:建议 3 台及以上同可用区实例(1 Head + N Worker),推荐 8C 32G 及以上规格,操作系统 Ubuntu 24.04 LTS。
阿里云 OSS:与 ECS 同地域,使用内网 endpoint 访问。协议配置详见上方配置 OSS 作为 Lance 存储后端。
Python 3.12 虚拟环境,已安装核心依赖:
pip install "pylance>=6.0.0" "lance-ray>=0.4.2" "ray[data]>=2.41.0" pip install torch --index-url https://download.pytorch.org/whl/cpu pip install sentence-transformers "modelscope[framework]" datasets pandas pyarrowRay 集群已就绪:
# Head 节点 ray start --head --port=6379 --dashboard-host=0.0.0.0 --dashboard-port=8265 # Worker 节点(传入 Head 的内网 IP) ray start --address=<HEAD_INTERNAL_IP>:6379OSS 访问凭证:已配置到 Head 节点环境变量(Ray 会自动序列化分发到 Worker):
export BUCKET_NAME="<your-bucket-name>" # S3 兼容协议(推荐,本实践默认使用) export AWS_ACCESS_KEY_ID="<your-access-key-id>" export AWS_SECRET_ACCESS_KEY="<your-access-key-secret>" export AWS_ENDPOINT="https://<bucket>.oss-cn-hangzhou-internal.aliyuncs.com"
1. 准备统一配置模块
为便于各步骤共享参数,将配置集中到 config.py,分为存储配置与计算配置两部分。
存储配置
本实践默认使用 S3 兼容协议,配置原理详见配置 OSS 作为 Lance 存储后端。
"""config.py — 存储配置部分"""
import os
from datetime import datetime
RUN_ID = os.environ.get("RUN_ID", datetime.now().strftime("%Y%m%d_%H%M%S"))
# 数据规模(写入调优参数依赖此值,因此提前定义)
NUM_SAMPLES = int(os.environ.get("NUM_SAMPLES", 100_000))
# OSS / 存储配置(S3 兼容协议)
BUCKET_NAME = os.environ["BUCKET_NAME"]
OSS_REGION = os.environ.get("OSS_REGION", "cn-hangzhou")
STORAGE_OPTIONS = {
"region": OSS_REGION,
"endpoint": os.environ.get(
"AWS_ENDPOINT",
f"https://{BUCKET_NAME}.oss-{OSS_REGION}-internal.aliyuncs.com",
),
"access_key_id": os.environ["AWS_ACCESS_KEY_ID"],
"secret_access_key": os.environ["AWS_SECRET_ACCESS_KEY"],
"virtual_hosted_style_request": "true",
}
# 数据集 URI
RAW_DATASET_URI = f"s3://{BUCKET_NAME}/lance-data/{RUN_ID}/wiki-raw.lance"
VECTOR_DATASET_URI = f"s3://{BUCKET_NAME}/lance-data/{RUN_ID}/wiki-vectors.lance"
# 写入调优
RAW_MAX_ROWS_PER_FILE = min(NUM_SAMPLES, 100_000)
RAW_MIN_ROWS_PER_FILE = min(NUM_SAMPLES // 2, 50_000)
VECTOR_MAX_ROWS_PER_FILE = min(NUM_SAMPLES, 200_000)
VECTOR_MIN_ROWS_PER_FILE = min(NUM_SAMPLES // 2, 50_000)计算配置
包含 Embedding 模型、Ray 调度参数、索引与搜索参数。Ray 调度参数在 ray.init() 之后由 init_ray_config() 从集群拓扑自动推导:
"""config.py — 计算配置部分"""
import math
# Embedding 模型
EMBEDDING_MODEL = "sentence-transformers/all-MiniLM-L6-v2"
EMBEDDING_DIM = 384
TEXT_TRUNCATE_LENGTH = 512
# Ray 参数 — init_ray_config() 自动填充
RAY_CPUS_PER_WORKER = 2
RAY_NUM_WORKERS = None
RAY_MEMORY_PER_WORKER = None
ACTOR_MIN_SIZE = None
ACTOR_MAX_SIZE = None
RAY_REMOTE_ARGS = None
ENCODE_BATCH_SIZE = 256
MAP_BATCH_SIZE = 1024
def init_ray_config():
"""ray.init() 之后调用,自动推导 Ray 调度参数。"""
import ray
global RAY_NUM_WORKERS, RAY_MEMORY_PER_WORKER
global ACTOR_MIN_SIZE, ACTOR_MAX_SIZE, RAY_REMOTE_ARGS
nodes = ray.nodes()
alive_nodes = [n for n in nodes if n["Alive"]]
num_nodes = len(alive_nodes)
total_cpus = sum(n["Resources"].get("CPU", 0) for n in alive_nodes)
total_memory_bytes = sum(n["Resources"].get("memory", 0) for n in alive_nodes)
total_memory_gb = total_memory_bytes / 1024**3
print(f"[config] Cluster: {num_nodes} nodes, "
f"{total_cpus:.0f} CPUs, {total_memory_gb:.1f} GB schedulable memory")
min_node_memory_gb = min(
n["Resources"].get("memory", 0) for n in alive_nodes
) / 1024**3
max_workers_per_node = max(1, int(min_node_memory_gb) // 10)
RAY_MEMORY_PER_WORKER = int(
min_node_memory_gb / max_workers_per_node * 0.8 * 1024**3
)
max_workers_by_cpu = int(total_cpus) // RAY_CPUS_PER_WORKER
max_workers_by_mem = num_nodes * max_workers_per_node
RAY_NUM_WORKERS = max(1, min(max_workers_by_cpu, max_workers_by_mem))
ACTOR_MIN_SIZE = 2
ACTOR_MAX_SIZE = min(6, max_workers_by_cpu)
RAY_REMOTE_ARGS = {
"num_cpus": RAY_CPUS_PER_WORKER,
"memory": RAY_MEMORY_PER_WORKER,
}
print(f"[config] Auto-tuned: num_workers={RAY_NUM_WORKERS}, "
f"memory/worker={RAY_MEMORY_PER_WORKER / 1024**3:.1f} GB, "
f"actor_pool=[{ACTOR_MIN_SIZE}, {ACTOR_MAX_SIZE}]")
# 向量索引
VECTOR_INDEX_NAME = "vector_idx"
VECTOR_INDEX_METRIC = "cosine"
IVF_NUM_PARTITIONS = max(16, min(4096, int(math.sqrt(NUM_SAMPLES))))
PQ_NUM_SUB_VECTORS = 48
# 全文索引
TITLE_FTS_INDEX_NAME = "title_fts_idx"
TEXT_FTS_INDEX_NAME = "text_fts_idx"
FTS_WITH_POSITION = True
# 搜索参数
VECTOR_SEARCH_K = 10
KEYWORD_SEARCH_LIMIT = 20
HYBRID_VECTOR_K = 20
RRF_K = 60
# 数据管理
APPEND_BATCH_SIZE = min(10_000, NUM_SAMPLES // 10)2. 准备原始数据集
从 ModelScope 下载 Wikipedia 数据集,以 Lance 格式写入 OSS。
"""步骤 2:准备测试数据集,以 Lance 格式写入 OSS"""
import lance
import pyarrow as pa
from modelscope.msdatasets import MsDataset
from config import NUM_SAMPLES, RAW_DATASET_URI, RAW_MAX_ROWS_PER_FILE, STORAGE_OPTIONS
def main():
print("Loading Wikipedia dataset from ModelScope...")
ds = MsDataset.load(
"wikimedia/wikipedia",
subset_name="20231101.en",
split=f"train[:{NUM_SAMPLES}]",
trust_remote_code=True,
)
print(f"Loaded {len(ds)} articles")
print(f"Sample: {ds[0]['title']}")
table = pa.table(
{
"doc_id": pa.array(range(len(ds)), type=pa.int64()),
"title": pa.array(ds["title"], type=pa.utf8()),
"text": pa.array(ds["text"], type=pa.utf8()),
}
)
print(f"Writing {table.num_rows} rows to OSS: {RAW_DATASET_URI}")
lance.write_dataset(
table,
RAW_DATASET_URI,
storage_options=STORAGE_OPTIONS,
max_rows_per_file=RAW_MAX_ROWS_PER_FILE,
)
ds_lance = lance.dataset(RAW_DATASET_URI, storage_options=STORAGE_OPTIONS)
print("Dataset written successfully!")
print(f" Rows: {ds_lance.count_rows()}")
print(f" Fragments: {len(ds_lance.get_fragments())}")
print(f" Schema: {ds_lance.schema}")
print(f" Version: {ds_lance.version}")
if __name__ == "__main__":
main()3. 分布式生成 Embedding 向量
通过 Ray Actor Pool 将 Embedding 计算分布到集群多个节点。每个 Actor 加载一次模型实例,持续处理多个 batch,避免重复加载模型的开销。整条流水线以 block 为单位在读取 → 计算 → 写入三阶段间流转,无需等待全量数据加载完成。
"""步骤 3:使用 Ray 分布式生成 Embedding 向量,并以 Lance 格式写回 OSS"""
import time
import lance
import lance_ray as lr
import ray
import config
from config import (
EMBEDDING_MODEL,
ENCODE_BATCH_SIZE,
MAP_BATCH_SIZE,
RAW_DATASET_URI,
RAY_CPUS_PER_WORKER,
STORAGE_OPTIONS,
TEXT_TRUNCATE_LENGTH,
VECTOR_DATASET_URI,
VECTOR_MAX_ROWS_PER_FILE,
VECTOR_MIN_ROWS_PER_FILE,
init_ray_config,
)
class EmbeddingGenerator:
"""Ray Actor:在每个 Worker 上加载一次模型,处理多个 batch"""
def __init__(self):
from modelscope import snapshot_download
from sentence_transformers import SentenceTransformer
local_path = snapshot_download(EMBEDDING_MODEL)
self.model = SentenceTransformer(local_path)
print(f"Model loaded on worker: {EMBEDDING_MODEL}")
def __call__(self, batch: dict) -> dict:
texts = [
f"{title}: {text[:TEXT_TRUNCATE_LENGTH]}"
for title, text in zip(batch["title"], batch["text"])
]
embeddings = self.model.encode(
texts,
batch_size=ENCODE_BATCH_SIZE,
show_progress_bar=False,
normalize_embeddings=True,
)
import numpy as np
import pyarrow as pa
flat = embeddings.astype(np.float32).ravel()
batch["vector"] = pa.FixedSizeListArray.from_arrays(
pa.array(flat, type=pa.float32()),
list_size=embeddings.shape[1],
)
return batch
def main():
ray.init(address="auto")
init_ray_config()
print("\n=== Phase 1: Reading raw data from OSS ===")
t0 = time.time()
ds = lr.read_lance(
RAW_DATASET_URI,
columns=["doc_id", "title", "text"],
storage_options=STORAGE_OPTIONS,
)
print(f"Read dataset: {ds.count()} rows, took {time.time()-t0:.1f}s")
print(f"Schema: {ds.schema()}")
print("\n=== Phase 2: Distributed Embedding Generation ===")
t1 = time.time()
ds_with_vectors = ds.map_batches(
EmbeddingGenerator,
batch_size=MAP_BATCH_SIZE,
compute=ray.data.ActorPoolStrategy(
min_size=config.ACTOR_MIN_SIZE,
max_size=config.ACTOR_MAX_SIZE,
),
num_gpus=0,
num_cpus=RAY_CPUS_PER_WORKER,
)
print(f"Embedding generation configured, took {time.time()-t1:.1f}s to plan")
print("\n=== Phase 3: Writing vectors to OSS in Lance format ===")
t2 = time.time()
lr.write_lance(
ds_with_vectors,
VECTOR_DATASET_URI,
storage_options=STORAGE_OPTIONS,
mode="create",
max_rows_per_file=VECTOR_MAX_ROWS_PER_FILE,
min_rows_per_file=VECTOR_MIN_ROWS_PER_FILE,
)
write_time = time.time() - t2
print(f"Write completed in {write_time:.1f}s")
print("\n=== Verification ===")
result_ds = lance.dataset(VECTOR_DATASET_URI, storage_options=STORAGE_OPTIONS)
print(f"Total rows: {result_ds.count_rows()}")
print(f"Fragments: {len(result_ds.get_fragments())}")
print(f"Schema: {result_ds.schema}")
print(f"Dataset version: {result_ds.version}")
sample = result_ds.take(indices=[0])
print(f"Sample doc_id: {sample['doc_id'][0].as_py()}")
print(f"Sample title: {sample['title'][0].as_py()}")
print(f"Sample vector dim: {len(sample['vector'][0].as_py())}")
print(f"Sample vector[:5]: {sample['vector'][0].as_py()[:5]}")
total_time = time.time() - t0
print(f"\nTotal pipeline time: {total_time:.1f}s")
ray.shutdown()
if __name__ == "__main__":
main()4. 分布式构建向量索引并执行 ANN 搜索
通过 lance-ray 分布式构建 IVF_PQ 向量索引。索引数据直接写入 OSS 上的 Lance 数据集目录,无需本地磁盘中转。
"""步骤 4:使用 Ray 分布式构建 IVF_PQ 向量索引"""
import time
import lance
import lance_ray as lr
import ray
import config
from config import (
IVF_NUM_PARTITIONS,
PQ_NUM_SUB_VECTORS,
STORAGE_OPTIONS,
VECTOR_DATASET_URI,
VECTOR_INDEX_METRIC,
VECTOR_INDEX_NAME,
VECTOR_SEARCH_K,
init_ray_config,
)
def main():
ray.init(address="auto")
init_ray_config()
ds = lance.dataset(VECTOR_DATASET_URI, storage_options=STORAGE_OPTIONS)
num_rows = ds.count_rows()
num_fragments = len(ds.get_fragments())
print(f"Dataset: {num_rows} rows, {num_fragments} fragments")
print("\n=== Building IVF_PQ Vector Index ===")
print(f" num_partitions={IVF_NUM_PARTITIONS}, num_sub_vectors={PQ_NUM_SUB_VECTORS}")
t0 = time.time()
updated_ds = lr.create_index(
VECTOR_DATASET_URI,
column="vector",
index_type="IVF_PQ",
name=VECTOR_INDEX_NAME,
metric=VECTOR_INDEX_METRIC,
num_partitions=IVF_NUM_PARTITIONS,
num_sub_vectors=PQ_NUM_SUB_VECTORS,
num_workers=config.RAY_NUM_WORKERS,
storage_options=STORAGE_OPTIONS,
ray_remote_args=config.RAY_REMOTE_ARGS,
)
index_time = time.time() - t0
print(f"Vector index built in {index_time:.1f}s")
indices = updated_ds.list_indices()
print(f"Indices: {indices}")
print(f"Dataset version after indexing: {updated_ds.version}")
print("\n=== Testing ANN Search ===")
sample = updated_ds.take(indices=[42])
query_vector = sample["vector"][0].as_py()
query_title = sample["title"][0].as_py()
print(f"Query document: '{query_title}'")
t1 = time.time()
results = updated_ds.to_table(
nearest={"column": "vector", "q": query_vector, "k": VECTOR_SEARCH_K},
columns=["doc_id", "title"],
)
search_time = time.time() - t1
print(
f"ANN search completed in {search_time*1000:.1f}ms, "
f"found {results.num_rows} results:"
)
for i in range(results.num_rows):
doc_id = results.column("doc_id")[i].as_py()
title = results.column("title")[i].as_py()
print(f" [{i+1}] doc_id={doc_id}, title='{title}'")
ray.shutdown()
if __name__ == "__main__":
main()5. 构建全文索引并执行混合搜索
分布式构建倒排索引(INVERTED),结合向量搜索实现 Hybrid Search。通过 RRF(Reciprocal Rank Fusion)融合两路检索结果,兼顾语义相似性与关键词匹配。
"""步骤 5:构建全文索引 + 混合搜索(向量 + 关键词)"""
import time
import lance
import lance_ray as lr
import ray
import config
from config import (
EMBEDDING_MODEL,
FTS_WITH_POSITION,
HYBRID_VECTOR_K,
KEYWORD_SEARCH_LIMIT,
RRF_K,
STORAGE_OPTIONS,
TEXT_FTS_INDEX_NAME,
TITLE_FTS_INDEX_NAME,
VECTOR_DATASET_URI,
VECTOR_SEARCH_K,
init_ray_config,
)
def main():
ray.init(address="auto")
init_ray_config()
# 分布式构建倒排索引
print("=== Building Full-Text Index ===")
t0 = time.time()
lr.create_scalar_index(
VECTOR_DATASET_URI,
column="title",
index_type="INVERTED",
name=TITLE_FTS_INDEX_NAME,
num_workers=config.RAY_NUM_WORKERS,
storage_options=STORAGE_OPTIONS,
ray_remote_args=config.RAY_REMOTE_ARGS,
with_position=FTS_WITH_POSITION,
)
fts_time = time.time() - t0
print(f"Full-text index on 'title' built in {fts_time:.1f}s")
print("\nBuilding FTS index on 'text' column...")
t1 = time.time()
lr.create_scalar_index(
VECTOR_DATASET_URI,
column="text",
index_type="INVERTED",
name=TEXT_FTS_INDEX_NAME,
num_workers=config.RAY_NUM_WORKERS,
storage_options=STORAGE_OPTIONS,
ray_remote_args=config.RAY_REMOTE_ARGS,
with_position=FTS_WITH_POSITION,
)
print(f"Text FTS index built in {time.time()-t1:.1f}s")
ds = lance.dataset(VECTOR_DATASET_URI, storage_options=STORAGE_OPTIONS)
print(f"\nAll indices: {ds.list_indices()}")
# 全文搜索
print("\n=== Full-Text Search ===")
query_text = "machine learning neural network"
t2 = time.time()
fts_results = ds.to_table(
full_text_query=query_text,
columns=["doc_id", "title"],
limit=VECTOR_SEARCH_K,
)
fts_search_time = time.time() - t2
print(f"FTS query '{query_text}' completed in {fts_search_time*1000:.1f}ms")
print(f"Found {fts_results.num_rows} results:")
for i in range(min(5, fts_results.num_rows)):
print(f" [{i+1}] {fts_results.column('title')[i].as_py()}")
# 混合搜索(向量 + 全文)
print("\n=== Hybrid Search (Vector + Full-Text) ===")
user_question = "What are the applications of deep learning in healthcare?"
from modelscope import snapshot_download
from sentence_transformers import SentenceTransformer
local_path = snapshot_download(EMBEDDING_MODEL)
model = SentenceTransformer(local_path)
query_vector = model.encode(user_question, normalize_embeddings=True).tolist()
t3 = time.time()
vector_results = ds.to_table(
nearest={"column": "vector", "q": query_vector, "k": HYBRID_VECTOR_K},
columns=["doc_id", "title", "text"],
)
vector_time = time.time() - t3
t4 = time.time()
keyword_results = ds.to_table(
full_text_query="deep learning healthcare",
columns=["doc_id", "title", "text"],
limit=KEYWORD_SEARCH_LIMIT,
)
keyword_time = time.time() - t4
print(f"\nUser question: '{user_question}'")
print(
f"Vector search: {vector_results.num_rows} results in {vector_time*1000:.1f}ms"
)
print(
f"Keyword search: {keyword_results.num_rows} results in {keyword_time*1000:.1f}ms"
)
# Reciprocal Rank Fusion
doc_scores = {}
doc_titles = {}
for i in range(vector_results.num_rows):
doc_id = vector_results.column("doc_id")[i].as_py()
doc_scores[doc_id] = doc_scores.get(doc_id, 0) + 1.0 / (RRF_K + i)
doc_titles[doc_id] = vector_results.column("title")[i].as_py()
for i in range(keyword_results.num_rows):
doc_id = keyword_results.column("doc_id")[i].as_py()
doc_scores[doc_id] = doc_scores.get(doc_id, 0) + 1.0 / (RRF_K + i)
doc_titles[doc_id] = keyword_results.column("title")[i].as_py()
ranked_docs = sorted(doc_scores.items(), key=lambda x: x[1], reverse=True)[:10]
print("\nHybrid search top results (RRF fusion):")
for rank, (doc_id, score) in enumerate(ranked_docs, 1):
title = doc_titles.get(doc_id, "Unknown")
print(f" [{rank}] score={score:.4f} | {title}")
ray.shutdown()
if __name__ == "__main__":
main()6. 数据维护——增量追加、Compaction 与版本回溯
演示生产环境中常见的数据维护操作:增量追加、分布式 Compaction、版本时间旅行。
"""步骤 6:数据管理 — 增量追加、分布式 Compaction、版本管理"""
import time
import lance
import lance_ray as lr
import numpy as np
import pyarrow as pa
import ray
from lance_ray.compaction import CompactionOptions
import config
from config import (
APPEND_BATCH_SIZE,
EMBEDDING_DIM,
STORAGE_OPTIONS,
VECTOR_DATASET_URI,
init_ray_config,
)
def main():
ray.init(address="auto")
init_ray_config()
ds = lance.dataset(VECTOR_DATASET_URI, storage_options=STORAGE_OPTIONS)
print(f"Current state: {ds.count_rows()} rows, {len(ds.get_fragments())} fragments")
print(f"Current version: {ds.version}")
# 1. 增量追加(演示用随机向量,生产环境应使用 Embedding 模型生成真实向量)
print("\n=== Incremental Append ===")
num_new = APPEND_BATCH_SIZE
start_id = ds.count_rows()
new_docs = pa.table(
{
"doc_id": pa.array(
range(start_id, start_id + num_new), type=pa.int64()
),
"title": pa.array(
[f"New Document {i}" for i in range(num_new)], type=pa.utf8()
),
"text": pa.array(
[
f"This is new content for document {i}. Updated knowledge base entry."
for i in range(num_new)
],
type=pa.utf8(),
),
"vector": pa.FixedSizeListArray.from_arrays(
pa.array(
(lambda v: (v / np.linalg.norm(v, axis=1, keepdims=True)).ravel())(
np.random.randn(num_new, EMBEDDING_DIM).astype(np.float32)
)
),
list_size=EMBEDDING_DIM,
),
}
)
ray_ds = ray.data.from_arrow(new_docs)
lr.write_lance(
ray_ds,
VECTOR_DATASET_URI,
storage_options=STORAGE_OPTIONS,
mode="append",
)
ds_after_append = lance.dataset(VECTOR_DATASET_URI, storage_options=STORAGE_OPTIONS)
print(
f"After append: {ds_after_append.count_rows()} rows, "
f"{len(ds_after_append.get_fragments())} fragments"
)
print(f"New version: {ds_after_append.version}")
# 2. 分布式 Compaction
print("\n=== Distributed Compaction ===")
t0 = time.time()
metrics = lr.compact_files(
VECTOR_DATASET_URI,
compaction_options=CompactionOptions(),
num_workers=config.RAY_NUM_WORKERS,
storage_options=STORAGE_OPTIONS,
ray_remote_args=config.RAY_REMOTE_ARGS,
)
compact_time = time.time() - t0
if metrics:
print(f"Compaction completed in {compact_time:.1f}s")
print(f"Metrics: {metrics}")
else:
print("No compaction needed")
ds_after_compact = lance.dataset(
VECTOR_DATASET_URI, storage_options=STORAGE_OPTIONS
)
print(
f"After compaction: {ds_after_compact.count_rows()} rows, "
f"{len(ds_after_compact.get_fragments())} fragments"
)
# 3. 版本管理(时间旅行)
print("\n=== Version Management (Time Travel) ===")
versions = ds_after_compact.versions()
print(f"Total versions: {len(versions)}")
for v in versions[-3:]:
print(f" Version {v['version']}: {v['timestamp']}")
old_version = versions[0]["version"]
ds_old = lance.dataset(
VECTOR_DATASET_URI,
version=old_version,
storage_options=STORAGE_OPTIONS,
)
print(f"\nOld version ({old_version}): {ds_old.count_rows()} rows")
print(
f"Current version ({ds_after_compact.version}): "
f"{ds_after_compact.count_rows()} rows"
)
ray.shutdown()
if __name__ == "__main__":
main()增量 Append 后,已有的向量索引和全文索引不会自动覆盖新增行。如需让搜索结果包含新数据,请重建索引。对于少量增量数据,Lance 会对未索引行自动执行暴力搜索作为兜底。
效果展示
以下为基于 3 节点 Ray 集群(3 × 8C 32G ECS)、10 万条 Wikipedia 文档的实际运行结果。
各阶段耗时参考
阶段 | 耗时 | 说明 |
数据写入 OSS | ~38s | 10 万条文档以 Lance 格式写入 OSS |
分布式 Embedding | ~490s | 6 个 Actor 并行,384 维向量,读写全程走 OSS |
向量索引构建 | ~101s | IVF_PQ 分布式构建,索引直接写入 OSS |
全文索引构建 | ~61s | title + text 两列倒排索引(title 4.3s + text 56.6s) |
Compaction | ~65s | 碎片 fragment 合并 |
搜索效果
ANN 向量搜索 — 以 “Crouching Tiger, Hidden Dragon” 为查询向量,直接在 OSS 上搜索语义最相似的文档:
Query: 'Crouching Tiger, Hidden Dragon'
[1] Crouching Tiger, Hidden Dragon
[2] Cheng Pei-pei
[3] Dragon Lord
[4] Dragon Fist (manga)
[5] The White Dragon (film)
[6] Tiger Child
[7] Wu Yonggang
[8] Sam Lee (actor)
[9] Action of the Tiger
[10] New Fist of Fury混合搜索(Hybrid Search) — 对用户问题 “What are the applications of deep learning in healthcare?”,同时执行向量语义搜索与关键词全文搜索,再通过 RRF 融合排序:
User question: 'What are the applications of deep learning in healthcare?'
Vector search: 20 results in ~1265ms
Keyword search: 20 results in ~347ms
Hybrid top results (RRF fusion):
[1] List of artificial intelligence projects
[2] Predictive analytics
[3] Artificial intelligence
[4] Clinical engineering
[5] NeuroSolutions版本管理与时间旅行
Lance 在 OSS 上以 MVCC 机制实现零拷贝快照。每次写入(Append、索引构建、Compaction)都会自动创建新版本,新旧版本共享未变更的数据文件,几乎不产生额外存储开销:
Total versions: 7
Version 1: 100,000 rows ← 初始写入
Version 4: 100,000 rows ← 索引构建后
Version 5: 110,000 rows ← 增量追加 10,000 条
Version 7: 110,000 rows ← Compaction 后
# 时间旅行:随时回溯到任意历史版本
ds_old = lance.dataset(uri, version=1) → 100,000 rows
ds_new = lance.dataset(uri, version=7) → 110,000 rows进阶:使用 OSS 加速器提升 RAG 在线检索性能
完成上述步骤后,数据集已具备在线检索能力。生产环境中 RAG 系统的检索延迟直接影响用户体验与系统吞吐,因此本节进一步验证OSS加速器在 Lance 在线检索场景下的性能提升效果。
Lance 的在线检索(向量、全文、混合搜索)本质上是对 OSS 上索引文件与数据文件的高频随机读取——例如一次向量搜索需读取 IVF 索引的多个分区,开启 PQ 精排时还需回读原始向量重排序,这些 I/O 延迟直接决定检索性能上限。OSS 加速器在计算节点与 OSS 之间提供低延迟、高吞吐的数据通路,可显著降低单次 I/O 耗时;并且 Lance "先写入再反复检索"的写后读模式天然适配加速器的同步预热特性,数据在写入阶段即被缓存,无需额外预热步骤。
测试场景
基于上述流水线构建的 Wikipedia 向量知识库,模拟真实 RAG 在线检索的端到端流程:输入文本 query → Embedding 推理 → OSS 检索 → 返回结果。使用 6 节点 Ray 集群、10 万条文档(IVF_PQ 向量索引 316 分区 + 全文倒排索引),36 个并发 Worker 各自独立执行完整检索流程,每个场景发起 5000 次检索请求。测试在服务预热完成后的稳态下进行。
加速器配置
测试中使用的 OSS 加速器通过阿里云控制台开通,配置如下:

应用代码无需任何改动,只需将 storage_options 中的 endpoint 替换为加速器地址即可生效。
测试参数
参数 | 值 | 说明 |
并发 Workers | 36 | 并行执行检索的 Ray Actor 数 |
nprobes | 10 | 搜索时探测的 IVF 分区数 |
refine_factor | 5 | PQ 精排候选倍数 |
vector_k | 10 | 返回 top-k 结果数 |
每场景请求数 | 5000 | 固定请求数,保证统计稳定性 |
测试结果
对比标准 OSS 与 OSS 加速器在 RAG 端到端场景下的性能差异:
任务总耗时对比(5000 次请求,36 并发,稳态阶段):
场景 | 标准 OSS | OSS 加速器 | 加速比 |
向量搜索 | 15.4s | 7.8s | 2.0x |
混合搜索 | 26.2s | 13.0s | 2.0x |
检索延迟对比(p50 中位数):
场景 | 标准 OSS | OSS 加速器 | 加速比 | 说明 |
向量搜索(含 Embedding) | 97.4ms | 43.8ms | 2.2x | Embedding 推理 + Lance 向量检索 |
向量搜索(纯检索) | 85.5ms | 30.2ms | 2.8x | 仅 Lance 向量检索 |
混合搜索(含 Embedding) | 173.5ms | 73.5ms | 2.4x | Embedding 推理 + 向量检索 + 全文检索 + RRF 融合 |
混合搜索(纯检索) | 161.5ms | 60.2ms | 2.7x | 仅向量检索 + 全文检索 + RRF 融合 |
关键结论
检索任务总耗时缩短一半:5000 次向量搜索从 15.4s 缩短至 7.8s(2.0x),混合搜索从 26.2s 缩短至 13.0s(2.0x)。
纯检索延迟 p50 降低 2.7~2.8 倍:向量搜索从 85.5ms 降至 30.2ms(2.8x),混合搜索从 161.5ms 降至 60.2ms(2.7x)。
nprobes 与 refine_factor 的最优值取决于数据集规模、索引分区数与召回率要求。上述测试基于 10 万条数据集(316 个 IVF 分区),生产环境建议根据实际召回率需求调整。
应用于生产环境
存储访问配置
优先使用 S3 兼容协议:生态成熟,且条件写入语义不受 Bucket 版本管理状态影响,适合生产环境的多写者并发场景。协议配置详见配置 OSS 作为 Lance 存储后端。
使用内网 endpoint:ECS 与 OSS 同地域时使用内网 endpoint 访问,免流量费且带宽更高。
在线检索加速
启用 OSS 加速器:对 Lance 向量检索、全文检索等高频随机读取场景,OSS 加速器可将纯检索延迟降低 2.7~2.8 倍,整体吞吐提升 2.0 倍。仅需将 endpoint 切换为加速器地址,应用代码无需改动。
写后读自动预热:数据在写入与索引构建阶段即被加速器缓存,后续检索请求直接命中,无需额外预热操作。
成本优化
存算分离:数据存储在 OSS,计算节点无需数据盘,可随时弹性扩缩,按需付费。
零拷贝版本与版本清理:Lance MVCC 新旧版本共享未变更数据文件,版本快照几乎零额外存储开销。清理旧版本时需通过 Lance API 操作,不要依赖外部存储策略,以避免误删仍被当前版本引用的共享文件:
# 清理 7 天前的旧版本及其不再被引用的数据文件 from datetime import timedelta ds = lance.dataset(uri, storage_options=storage_options) ds.cleanup_old_versions(older_than=timedelta(days=7))
Ray 分布式调优
自动资源探测:在
ray.init()之后调用init_ray_config(),从集群拓扑自动推导 Worker 数量、内存声明与 Actor Pool 大小。Fragment 即并行度:
lance-ray按 fragment 分配索引构建任务;写入时通过max_rows_per_file控制 fragment 数量,即索引构建的并行度上限。Actor Pool 弹性与流水线反压:Embedding 阶段使用
ActorPoolStrategy(min_size, max_size),Ray 根据负载自动伸缩模型实例数量;Ray Data 流式 Pipeline 内置反压(Backpressure)机制,自动协调读取、计算、写入各阶段速率。可通过 Ray Dashboard 的 Ray Data 面板监控各算子吞吐与积压情况。