多节点并发启动AI推理服务时,OSS Connector支持模型广播功能,仅由单个节点从OSS加载模型数据,其余节点通过链式拓扑结构完成模型数据的分发,大幅减少数据回源量,提升模型分发效率。
方案介绍
多节点并发启动AI推理服务时,若模型文件存储于OSS,各节点同时从OSS源端拉取模型会导致源端出口带宽成为性能瓶颈,引发服务启动延迟或失败。尤其在一些OSS出口带宽比较低的Region,多节点同时回源将严重影响服务部署效率。
OSS Connector模型广播是AI推理服务大规模部署时的优化策略,指在批量启动同一模型的推理服务时,仅由单个或少量节点从OSS加载模型数据,其余节点通过预设的链式拓扑结构完成模型数据的分发。模型广播可以利用节点的存储和网络资源,大幅减少数据回源量,降低源端压力,提升模型分发效率。
OSS Connector模型广播采用链式传输方式。链式传输通过将模型文件在节点间串行传递,使每个节点仅接收和转发一次数据。在模型文件传输的场景下,单个数据流往往就能打满多数主流机型节点带宽,链式传输避免了树形传输中节点向多个下游节点发送数据而触达带宽瓶颈。
OSS Connector通过内存缓冲区机制,采用高并发策略将OSS上的模型文件预加载至缓冲区,供推理引擎按需载入GPU显存,完成推理后延时释放缓冲内存。模型广播功能在此基础上扩展了缓冲区的共享能力,集成了DADI P2P相关功能,仅需要部署一个Redis或Tair服务用于节点发现和元数据管理,实现将缓冲数据分发至其他节点。相较于单机部署方案,该方案仅增加轻量级缓冲区共享逻辑,却能充分利用模型加载阶段闲置的节点出口带宽,是一种兼具经济性与高效性的分布式模型加载方案。

OSS Connector模型广播启动同一模型在同一时间段仅会有一份数据回源OSS,可以极大减轻批量启动时OSS源的压力。但若源的性能仍为瓶颈,则须配合OSS加速器或DADI P2P分布式缓存版使用。
前提条件
已安装OSS Connector for AI/ML V1.2.0及以上版本。安装方法请参见使用OSS Connector for AI/ML提升模型部署效率。
已准备好Redis或Tair数据库,用于节点发现和元数据管理。
配置数据库
模型广播功能基于Redis或Tair服务进行节点发现和元数据管理,使用前需先配置数据库。
方案一:购买并配置云数据库Tair(推荐)
Tair是阿里云提供的兼容Redis协议的云数据库服务,具备高可用性和免运维的优势。
参考快速入门概览创建Tair实例,版本需 ≥ 6.0,最低规格。
设置白名单,确保推理节点能够访问Tair实例。
准备好
连接地址、端口号、账号和密码,用于后续配置模型广播。
方案二:独立部署Redis服务
如果不使用云数据库Tair,你也可以在Kubernetes集群中自行部署Redis服务。
以下YAML文件部署了一个包含ACL认证的Redis服务:
创建ACL配置文件并生成Kubernetes Secret。
# 创建 ACL 内容 cat > users.acl << EOF user default off -@all user Username on >Password ~* &* +@all EOF # 创建 Secret kubectl create secret generic redis-acl-secret \ --from-file=users.acl \ --dry-run=client -o yaml | kubectl apply -f -说明请将
Username和Password替换为实际的用户名和密码。使用以下YAML文件部署Redis Service和Deployment。
# redis-service.yaml apiVersion: v1 kind: Service metadata: name: redis spec: selector: app: model-redis ports: - protocol: TCP port: 6379 targetPort: 6379 --- # redis-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: model-redis-deployment spec: replicas: 1 selector: matchLabels: app: model-redis template: metadata: labels: app: model-redis spec: containers: - name: redis image: mirrors-ssl.aliyuncs.com/redis:8.4.0 ports: - containerPort: 6379 command: ["redis-server"] args: - "--aclfile" - "/etc/redis/users.acl" - "--maxmemory" - "900mb" - "--maxmemory-policy" - "volatile-lru" - "--save" - "" - "--appendonly" - "no" - "--loglevel" - "notice" resources: requests: memory: "1Gi" cpu: "100m" limits: memory: "1Gi" cpu: "200m" volumeMounts: - name: acl-config mountPath: /etc/redis/users.acl subPath: users.acl volumes: - name: acl-config secret: secretName: redis-acl-secret执行以下命令部署Redis服务。
kubectl apply -f redis-service.yaml
启用模型广播功能
在OSS Connector配置文件/etc/oss-connector/config.json中添加模型广播相关配置。
{
...
"broadcast": {
"enableBroadcast": true,
"tenant": "${P2P_KEY_PREFIX}",
"db": {
"host": "${P2P_REDIS_HOST}",
"port": 6379,
"username": "${P2P_REDIS_USERNAME}",
"password": "${P2P_REDIS_PASSWD}"
}
},
"bindPort": 19898
...
}配置参数说明如下表所示。
参数名 | 说明 |
broadcast.enableBroadcast | 是否启用模型广播功能。设置为 |
broadcast.tenant | 租户名。相同租户名的节点间可以进行模型广播,建议每个服务配置一个租户。 |
broadcast.db.host | Redis或Tair服务的连接地址。 |
broadcast.db.port | Redis或Tair服务的端口号。默认为6379。 |
broadcast.db.username | Redis或Tair服务的账号。 |
broadcast.db.password | Redis或Tair服务的密码。 |
bindPort | 对外提供数据的端口。默认值为19898。 |
在Kubernetes集群中部署模型广播服务的完整示例,请参见部署多实例模型广播服务。
限制缓存大小
模型广播过程中,节点需要在内存中缓存模型数据以供其他节点获取。你可以通过以下方式限制缓存占用的内存大小。
方式一:通过环境变量设置
export CONNECTOR_MAX_CACHE_ADVISE_GB=100方式二:通过配置文件设置
在
/etc/oss-connector/config.json中设置prefetch.maxCacheAdviseGB:{ ... "prefetch": { "vcpus": 16, "workers": 24, "maxCacheAdviseGB": 100 }, ... }
内存限制为软限制。
环境变量优先级高于配置文件。
性能报告
以下为Qwen2.5-72B模型(135.437 GB)在不同Region使用模型广播功能的性能测试结果。
北京Region测试
测试环境
测试项 | 配置 |
OSS | 北京,内网下载带宽250 Gbps |
节点配置 | ecs.g9i.24xlarge,网络32/最高48 Gb/s,96 vCPU 384 GiB |
模型 | Qwen2.5-72B,135.437 GB |
测试指标 | CPU版vllm api server启动到服务就绪时间、OSS和P2P流量 |
不限制缓存大小
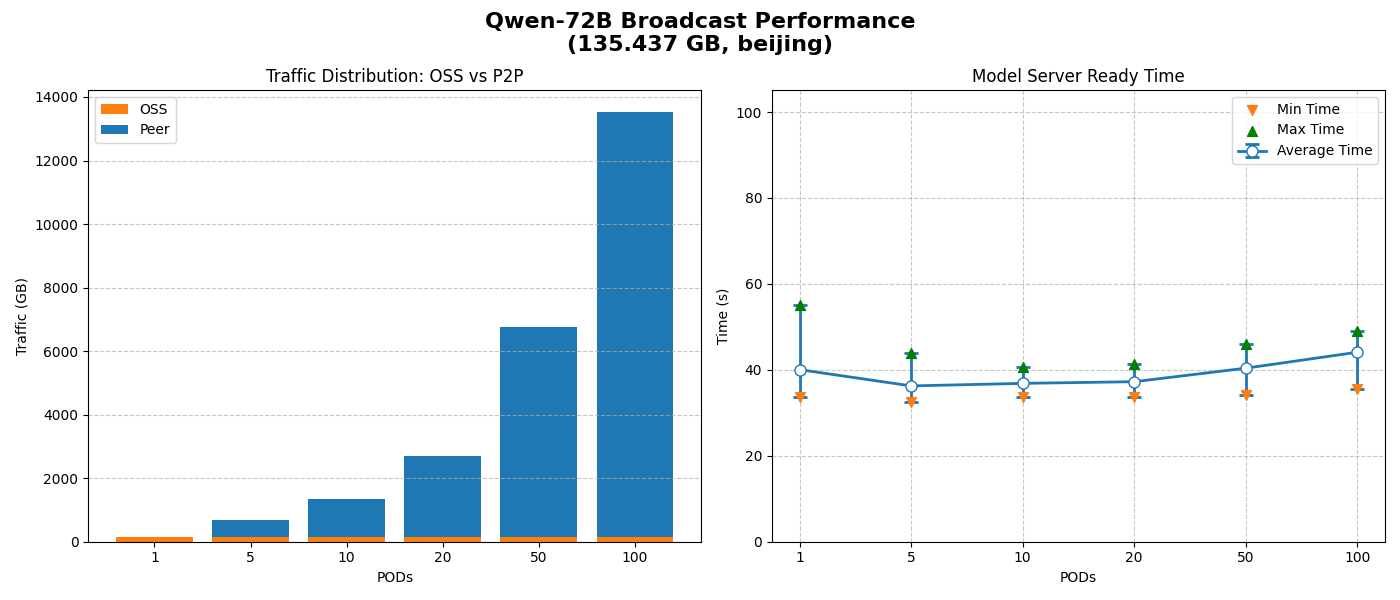
仅一份数据回源,其他均通过P2P传输,将OSS带宽压力降至最低。
平均模型就绪时间接近O(1)时间,不随节点数线性增加,具有良好的水平扩展能力。
限制缓存大小
分别测试不限制缓存大小、限制缓存大小到100/60/40/20/0 GB时,1/10/50/100节点同时启动的模型就绪时间。
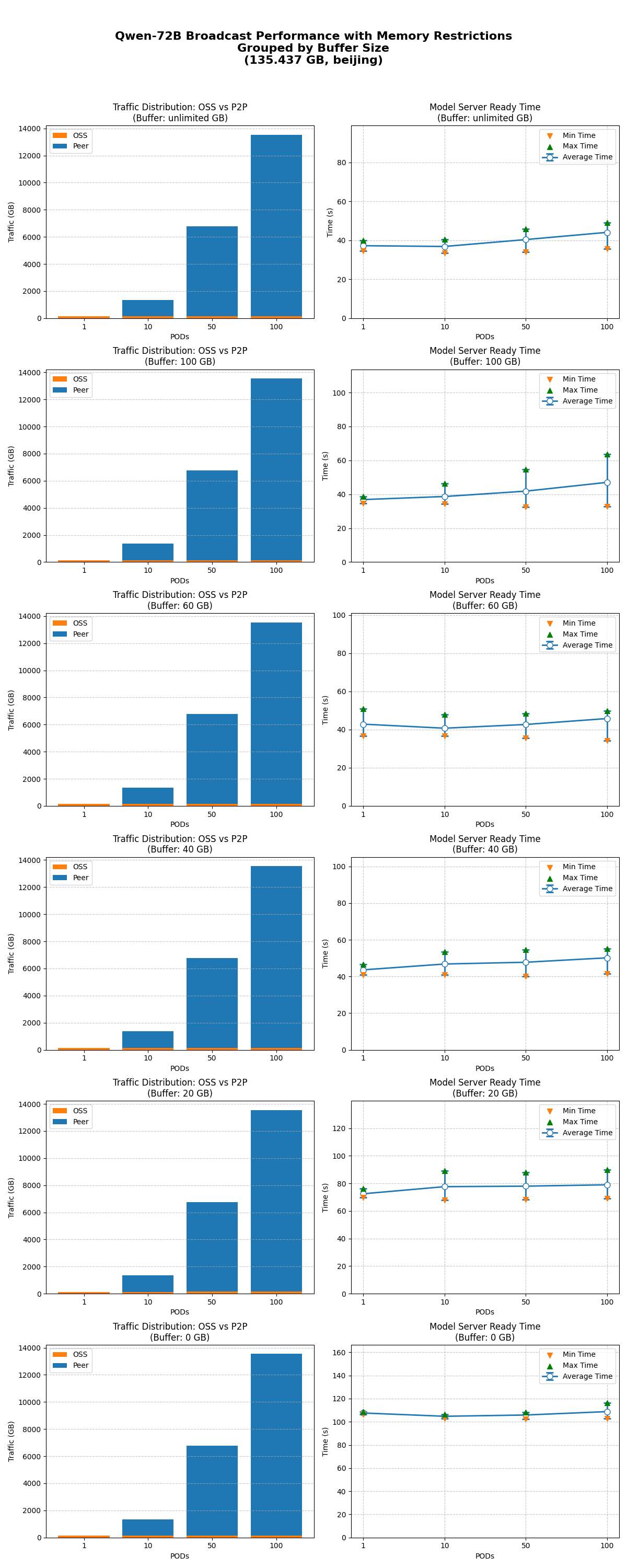
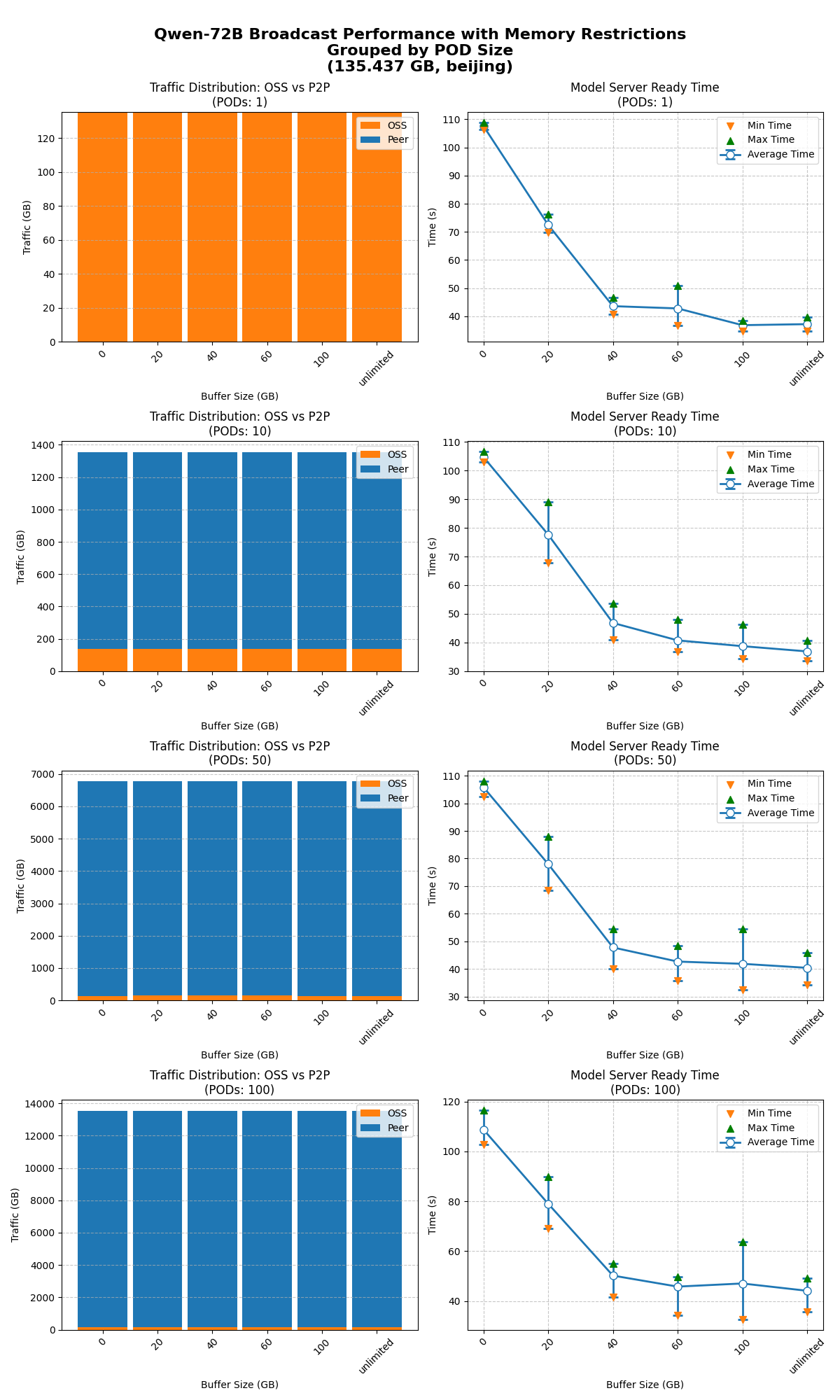
在不同缓存限制下,模型广播能正常工作,达到预期效果。
在不同并发下,限制缓存对性能的影响基本一致。当缓存 ≥ 40 GB时,限制缓存对模型就绪时间影响不显著;当缓存 ≤ 20 GB时,性能开始明显下降。
乌兰察布Region测试
测试环境
测试项 | 配置 |
OSS | 乌兰察布,内网下载带宽10 Gbps |
节点配置 | ecs.g9i.24xlarge,网络32/最高48 Gb/s,96 vCPU 384 GiB |
模型 | Qwen2.5-72B,135.437 GB |
分别测试不限制缓存大小、限制缓存大小到60/0 GB时,1/10/50/100节点同时启动的模型就绪时间。
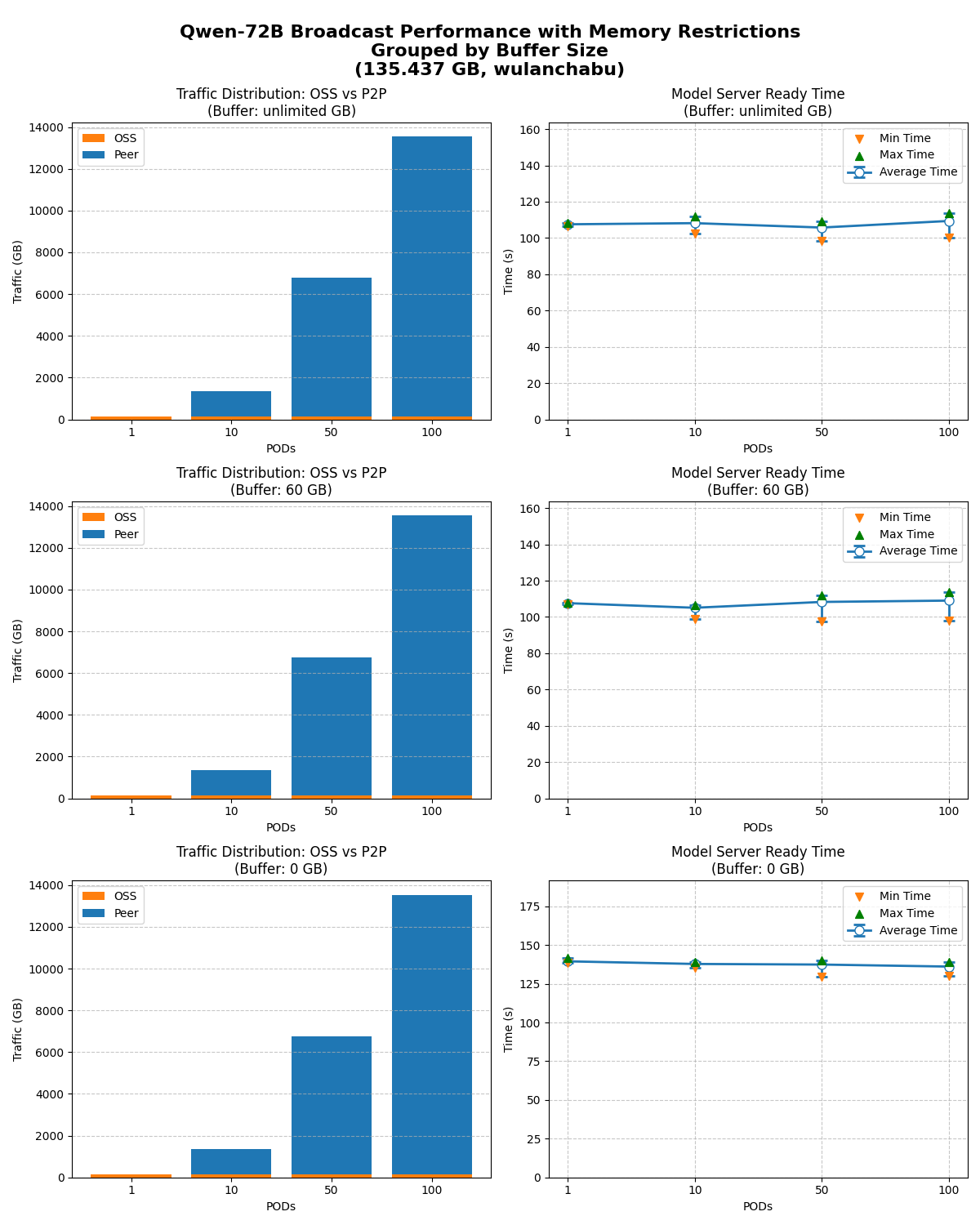
从测试结果看,当OSS下载带宽受限时,模型广播仍具备良好的水平扩展能力,将OSS带宽压力降至最低。