NimoShake(又名DynamoShake)是阿里云研发的数据同步工具,您可以借助该工具将Amazon DynamoDB数据库迁移至阿里云。
前提条件
背景信息
NimoShake主要用于从DynamoDB进行迁移,目的端目前仅支持MongoDB。更多详情请参见NimoShake介绍。
注意事项
在执行全量数据迁移时将占用源库和目标库一定的资源,可能会导致数据库服务器负载上升。如果数据库业务量较大或服务器规格较低,可能会加重数据库压力。建议您在执行数据迁移前谨慎评估,在业务低峰期执行数据迁移。
阿里云MongoDB实例的存储空间须大于Amazon DynamoDB数据库占用的存储空间。
名词解释
断点续传:断点续传是指将一个任务分成多个部分进行传输,当遇到网络故障或者其他原因造成的传输中断,可以延续之前传输的部分继续传输,而不用从头开始。
说明全量同步不支持断点续传功能,增量同步支持断点续传,如果增量同步过程中连接断开了,在一定时间内恢复连接是可以继续进行增量同步的。但在某些情况下,比如断开的时间过久,或者之前位点的丢失,都会导致重新触发全量同步。
位点:增量的断点续传是根据位点来实现的,默认的位点是写入到目的端MongoDB中,库名是nimo-shake-checkpoint。每个表都会记录一个checkpoint的表,同样还会有一个status_table表记录当前是全量同步还是增量同步。
NimoShake功能特性
NimoShake目前支持全量和增量分离的同步机制,即先同步全量数据,再同步增量数据。
全量同步:包含数据同步和索引同步两个部分,基本架构如下:

数据同步:NimoShake使用多个并发线程拉取源端数据,如下图所示。
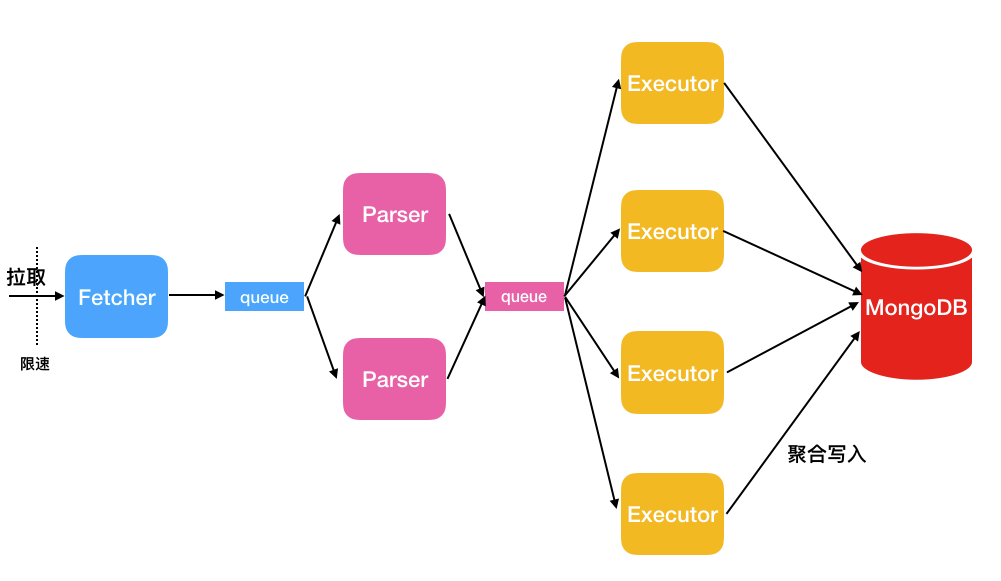
线程名称
说明
Fetcher
调用Amazon提供的协议转换驱动批量抓取源表的数据并放入队列中,直至抓取完源表的所有数据。
说明目前只提供一个Fetcher线程。
Parser
从队列中读取数据,并解析成BSON结构。Parser解析完成后,将数据按条写入Executor队列。Parser线程可以启动多个,默认为2个,您可以通过
FullDocumentParser参数调整Parser的个数。Executor
从队列中拉取数据,并将数据进行聚合后写入目的端MongoDB(聚合上限16MB,总条数1024)。Executor线程可以启动多个,默认为4个,您可以通过
FullDocumentConcurrency参数调整Executor的个数。索引同步:NimoShake会在完成数据同步之后写入索引。索引分为自带索引和用户索引两部分:
自带索引:如您有分区键(Partition key)和排序键(Sort key),NimoShake将会创建一个联合唯一索引写入MongoDB,除此之外,NimoShake还会针对分区键创建一个哈希(Hash)索引同时写入。如果您只有一个分区键,那么最终写入到MongoDB的将会是一个哈希索引和一个唯一索引。
用户索引:如果您有自建的索引,NimoShake将会根据主键(Primary key)创建一个哈希索引写入MongoDB。
增量同步:增量同步只同步数据,不同步增量同步过程中产生的索引。其基本架构如下:
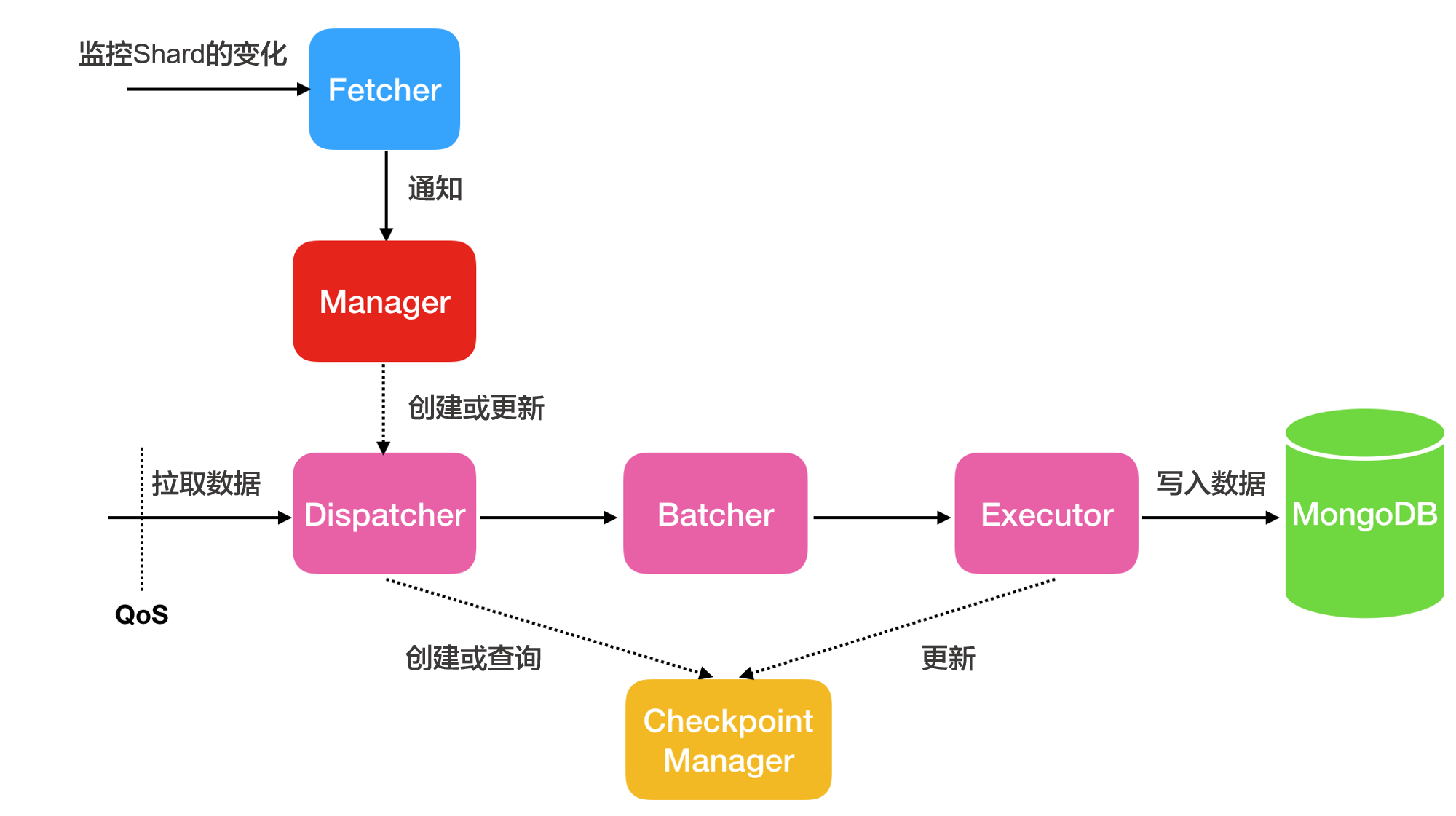
线程名称
说明
Fetcher
感知流(Stream)中分片(shard)的变化。
Manager
进行消息的通知,或者创建新的Dispatcher处理消息,一个shard对应一个Dispatcher。
Dispatcher
从源端拉取增量数据。如果是断点续传,则会从上一次的Checkpoint位点开始拉取,而不是从头拉取。
Batcher
对Dispatcher线程拉取的增量数据进行数据解析、打包与整合。
Executor
将整合后的数据写入到MongoDB,同时更新checkpoint位点。
将Amazon DynamoDB迁移至阿里云
本步骤以Ubuntu系统为例,介绍如何使用NimoShake将Amazon Dynamo数据库迁移到阿里云数据库。
在系统中执行如下命令下载NimoShake包,等待下载完成。
wget https://github.com/alibaba/NimoShake/releases/download/release-v1.0.14-20250704/nimo-shake-v1.0.14.tar.gz说明建议下载最新版本的NimoShake包,下载地址请参见NimoShake。
执行如下命令解压下载的NimoShake包。
tar zxvf nimo-shake-v1.0.14.tar.gz解压完成后,输入
cd nimo-shake-v1.0.14命令进入nimo文件夹。输入
vi nimo-shake.conf命令打开NimoShake的配置文件。配置NimoShake,各配置项说明如下:
参数
说明
示例值
id
迁移任务的ID,可自定义,用于输出pid文件等信息,如本次任务的日志名称、断点续传(checkpoint)位点信息存储的数据库名称、同步到目的端的数据库名称。
id = nimo-shakelog.file
日志文件路径,不配置将打印到stdout。
log.file = nimo-shake.loglog.level
日志的等级,取值:
none:不收集日志。error:包含错误级别信息的日志。warn:包含警告级别信息的日志。info:反馈当前系统状态的日志。debug:包含调试信息的日志。
默认值:
info。log.level = infolog.buffer
是否启用日志缓冲区。取值:
true:启用。启用后能保证性能,但退出时可能会丢失最后几条日志。false:不启用。不启用将会降低性能但保证退出时每条日志都被打印。
默认值:
true。log.buffer = truesystem_profile
PPROF端口,作调试用,打印堆栈协程信息。
system_profile = 9330full_sync.http_port
全量阶段的RESTful端口,可以通过
curl查看内部监控的统计情况,详见wiki。full_sync.http_port = 9341incr_sync.http_port
增量阶段的RESTful端口,可以通过
curl查看内部监控的统计情况,详见wiki。incr_sync.http_port = 9340sync_mode
同步的类型,取值如下:
all:执行全量数据同步和增量数据同步。full:仅执行全量同步。
默认值:
all。说明源端为云数据库MongoDB版DynamoDB协议兼容版实例时,仅支持full模式。
sync_mode = allincr_sync_parallel
是否执行并行增量同步。取值:
true:开启,开启后NimoShake会消耗更多内存。false:不开启。
默认值:
false。incr_sync_parallel = falsesource.access_key_id
DynamoDB端的AccessKey ID。
source.access_key_id = xxxxxxxxxxxsource.secret_access_key
DynamoDB端的AccessKey。
source.secret_access_key = xxxxxxxxxxsource.session_token
DynamoDB端的临时密钥,如没有可以不配置。
source.session_token = xxxxxxxxxxsource.region
DynamoDB所属的地域,如没有可以不配置。
source.region = us-east-2source.endpoint_url
源端如果是endpoint类型,可以配置该参数。
重要启用该参数后,上述source相关参数失效。
source.endpoint_url = "http://192.168.0.1:1010"source.session.max_retries
会话失败后的最大重试次数。
source.session.max_retries = 3source.session.timeout
会话超时时间,0为不启用。单位:毫秒。
source.session.timeout = 3000filter.collection.white
数据同步的白名单,设置允许通过的表名。如
filter.collection.white = c1;c2表示允许C1和C2表通过,剩下的表全部过滤。filter.collection.white = c1;c2filter.collection.black
数据同步的黑名单,设置需要过滤的表名。如
filter.collection.black = c1;c2表示过滤掉C1和C2表,剩下的表全部通过。重要不能同时指定filter.collection.white和filter.collection.black参数,否则表示全部表通过。
filter.collection.black = c1;c2qps.full
全量同步阶段,限制
Scan命令对表执行的频率,表示每秒钟最多调用多少次Scan。默认值:1000。
qps.full = 1000qps.full.batch_num
全量同步阶段,每秒拉取多少条数据。
默认值:128。
qps.full.batch_num = 128qps.incr
增量同步阶段,限制
GetRecords命令对表执行的频率,表示每秒钟最多调用多少次GetRecords。默认值:1000。
qps.incr = 1000qps.incr.batch_num
增量同步阶段,每秒拉取多少条数据。
默认值:128。
qps.incr.batch_num = 128target.type
目的端数据库类型,取值:
mongodb:目的端为MongoDB数据库。aliyun_dynamo_proxy:目的端为兼容DynamoDB协议的MongoDB数据库。
target.type = mongodbtarget.address
目的端数据库的连接地址,支持MongoDB的连接串地址和DynamoDB兼容连接地址。
获取MongoDB的地址信息,请参见副本集实例连接说明或分片集群实例连接说明。
target.address = mongodb://username:password@s-*****-pub.mongodb.rds.aliyuncs.com:3717target.mongodb.type
目的端MongoDB数据库的类型,取值:
replica:副本集。sharding:分片集群。
target.mongodb.type = shardingtarget.db.exist
目的端重名表的处理方式,取值:
rename:对目的端已存在的重名表进行重命名,添加时间戳后缀,比如c1变为c1.2019-07-01Z12:10:11。警告此操作会修改目的端的表名称,可能会对业务产生影响,请务必提前做好迁移的准备工作。
drop:删除目的端的重名表。
如不配置则不做处理,此时如果目的端中有重名表会报错退出,迁移终止。
target.db.exist = dropsync_schema_only
是否仅同步表的结构。取值:
true:是,仅同步表结构。false:否。
默认值:
false。sync_schema_only = falsefull.concurrency
全量同步阶段的表级别并发度,表示一次最多同步多少个表。
默认值:4。
full.concurrency = 4full.read.concurrency
全量阶段表内文档级别并发度,表示1个表最多有几个线程同时并发读取源端,对应Scan接口的TotalSegments。
full.read.concurrency = 1full.document.concurrency
全量同步阶段参数。表内document的并发度,表示使用多少个线程并发将一个表内的内容写入目的端。
默认值:4。
full.document.concurrency = 4full.document.write.batch
一次聚合写入多少条数据,如果目的端是DynamoDB协议最大配置25。
full.document.write.batch = 25full.document.parser
全量同步阶段参数。表内解析线程个数,表示使用多少个线程并发将Dynamo协议转换到目的端对应协议。
默认值:2。
full.document.parser = 2full.enable_index.user
全量同步阶段参数。是否同步用户自建的索引。取值:
true:是。false:否。
默认值:
true。full.enable_index.user = truefull.executor.insert_on_dup_update
全量同步阶段参数。在目的端碰到相同key的情况下,是否将
INSERT操作改为UPDATE。取值:true:是。false:否。
默认值:
true。full.executor.insert_on_dup_update = trueincrease.concurrency
增量同步阶段参数。一次最多并发抓取多少个分片(shard)。
默认值:16。
increase.concurrency = 16increase.executor.insert_on_dup_update
增量同步阶段参数。在目的端碰到相同key的情况下,是否将
INSERT操作改为UPDATE。取值:true:是。false:否。
默认值:
true。increase.executor.insert_on_dup_update = trueincrease.executor.upsert
增量同步阶段参数。如果目的端不存在key的情况下,是否将
UPDATE操作改为UPSERT。取值:true:是false:否
说明UPSERT操作会判断目标key是否存在,如果存在则执行UPDATE操作,如果不存在则执行INSERT操作。
increase.executor.upsert = truecheckpoint.type
用于断点续传的位点信息(Checkpoint)存储类型。取值:
mongodb:断点续传位点信息(Checkpoint)存储于MongoDB数据库中,仅在target.type参数为mongodb时可用。file:断点续传位点信息(Checkpoint)存储于本地计算机中。
checkpoint.type = mongodbcheckpoint.address
存储断点续传位点信息(Checkpoint)的地址。
checkpoint.type参数为mongodb:输入MongoDB数据库的连接地址。如不配置则默认存储到目的端的MongoDB库中。查看MongoDB的地址信息,请参见副本集实例连接说明或分片集群实例连接说明。checkpoint.type参数为file:输入以nimo-shake运行文件所在路径为基准的相对路径,如:checkpoint。如不配置则默认存储到checkpoint文件夹。
checkpoint.address = mongodb://username:password@s-*****-pub.mongodb.rds.aliyuncs.com:3717checkpoint.db
存储断点续传位点信息(Checkpoint)的MongoDB数据库名,如不配置则数据库名的格式默认为
<id>-checkpoint示例:
nimo-shake-checkpoint。checkpoint.db = nimo-shake-checkpointconvert._id
给DynamoDB中的
_id字段增加前缀,不和MongoDB的_id冲突。convert._id = prefull.read.filter_expression
全量阶段中用于过滤的DynamoDB表达式。
:begin和:end,这两个冒号开头的是变量,实际的值在filter_attributevalues中。full.read.filter_expression = create_time > :begin AND create_time < :endfull.read.filter_attributevalues
全量阶段中用于过滤的DynamoDB表达式值,对应
filter_expression中指定的变量具体值。N为 Number,S为 String。full.read.filter_attributevalues = begin```N```1646724207280~~~end```N```1646724207283执行如下命令使用配置好的nimo-shake.conf文件启动迁移。
./nimo-shake.linux -conf=nimo-shake.conf说明全量同步完成后,屏幕上会打印出
full sync done!。如果中途出错导致同步终止,程序会自动关闭并在屏幕上打印对应的错误信息,便于您定位错误原因。