调用大模型时,不同推理请求可能出现输入内容的重叠(例如多轮对话或对同一本书的多次提问)。上下文缓存(Context Cache)技术可以缓存这些请求的公共前缀,减少推理时的重复计算。这能提升响应速度,并在不影响回复效果的前提下降低您的使用成本。
为满足不同场景的需求,上下文缓存提供两种工作模式,可以根据对便捷性、确定性及成本的需求进行选择:
显式缓存:需要主动开启的缓存模式。需要主动为指定内容创建缓存,以在有效期(5分钟)内实现确定性命中。除了输入 Token 计费,用于创建缓存的 Token 按输入 Token 标准单价的 125% 计费,后续命中仅需支付 10%的费用。
隐式缓存:此为自动模式,无需额外配置,且无法关闭,适合追求便捷的通用场景。系统会自动识别请求内容的公共前缀并进行缓存,但缓存命中率不确定。对命中缓存的部分,按输入 Token 标准单价的 20% 计费。
项目 | 显式缓存 | 隐式缓存 |
是否影响回复效果 | 不影响 | 不影响 |
用于创建缓存Token计费 | 输入 Token 单价的125% | 输入 Token 单价的100% |
命中缓存的输入 Token 计费 | 输入 Token 单价的10% | 输入 Token 单价的20% |
缓存最少 Token 数 | 1024 | 256 |
缓存有效期 | 5分钟(命中后重置) | 不确定,系统会定期清理长期未使用的缓存数据 |
显式缓存、隐式缓存两者互斥,单个请求只能应用其中一种模式。
预置吞吐(PTU)部署同样支持上下文缓存。命中缓存时,PTU 额度消耗按缓存折扣系数折算。详见预置吞吐长输入与缓存。
本文内容适用 OpenAI Chat Completions 、 DashScope 与 Anthropic 兼容接口。使用 Responses API 可通过 Session 缓存降低推理延迟与成本,详情参考Session 缓存。
显式缓存
与隐式缓存相比,显式缓存需要显式创建并承担相应开销,但能实现更高的缓存命中率和更低的访问延迟。
使用方式
在 messages 中加入"cache_control": {"type": "ephemeral"}标记,系统将以每个cache_control标记位置为终点,向前回溯最多 20 个 content 块,尝试命中缓存。
单次请求最多支持加入4 个缓存标记。
未命中缓存
系统将从messages数组开头到
cache_control标记之间的内容创建为新的缓存块,有效期为 5 分钟。缓存创建发生在模型响应之后,建议在创建请求完成后再尝试命中该缓存。
缓存块的内容最少为 1024 Token。
命中缓存
选取最长的匹配前缀作为命中的缓存块,并将该缓存块的有效期重置为5分钟。
以下示例说明其使用方式:
发起第一个请求:发送包含超 1024 Token 文本 A 的系统消息,并加入缓存标记:
[{"role": "system", "content": [{"type": "text", "text": A, "cache_control": {"type": "ephemeral"}}]}]系统将创建首个缓存块,记为 A 缓存块。
发起第二个请求:发送以下结构的请求:
[ {"role": "system", "content": A}, <其他 message> {"role": "user","content": [{"type": "text", "text": B, "cache_control": {"type": "ephemeral"}}]} ]若“其他message”不超过 20 条,则命中 A 缓存块,并将其有效期重置为 5 分钟;同时,系统会基于 A、其他message和 B 创建一个新的缓存块。
若“其他message”超过 20 条,则无法命中 A 缓存块,系统仍会基于完整上下文(A + 其他message + B)创建新缓存块。
支持的模型
新加坡
以下模型均为国际部署范围。
千问 Max:qwen3.7-max、qwen3.7-max-2026-05-20、qwen3.7-max-2026-06-08、qwen3.6-max-preview、qwen3-max
千问 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26、qwen3.6-plus、qwen3.5-plus、qwen3.5-plus-2026-04-20、qwen-plus
千问 Flash:qwen3.6-flash、qwen3.5-flash、qwen-flash
千问 Coder:qwen3-coder-plus、qwen3-coder-flash
千问 VL:qwen3-vl-plus、qwen3-vl-flash
DeepSeek:deepseek-v3.2
华北2(北京)
以下模型均为中国内地部署范围。
千问 Max:qwen3.7-max、qwen3.7-max-2026-05-20、qwen3.7-max-2026-06-08、qwen3.6-max-preview、qwen3-max
千问 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26、qwen3.6-plus、qwen3.5-plus、qwen3.5-plus-2026-04-20、qwen-plus
千问 Flash:qwen3.6-flash、qwen3.5-flash、qwen-flash
千问 Coder:qwen3-coder-plus、qwen3-coder-flash
千问 VL:qwen3-vl-plus、qwen3-vl-flash
DeepSeek:deepseek-v3.2
Kimi:kimi-k2.6、kimi-k2.5
GLM:glm-5.1
德国(法兰克福)
不同服务部署范围支持的模型不同。
全球服务部署范围:
千问 Max:qwen3.7-max、qwen3.7-max-2026-05-20、qwen3.7-max-2026-06-08、qwen3-max
千问 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26、qwen3.6-plus、qwen3.5-plus、qwen-plus
千问 Flash:qwen3.6-flash、qwen3.5-flash、qwen-flash
千问 VL:qwen3-vl-plus
千问 Coder:qwen3-coder-plus、qwen3-coder-flash
Kimi:kimi-k2.5
欧盟服务部署范围:
千问 Max:qwen3-max
千问 Plus:qwen-plus
千问 Flash:qwen3.6-flash、qwen3.5-flash
千问 VL:qwen3-vl-plus
中国香港
不同服务部署范围支持的模型不同。
全球服务部署范围:
千问 Max:qwen3.7-max、qwen3.7-max-2026-05-20、qwen3.7-max-2026-06-08
千问 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26、qwen3.6-plus
千问 Flash:qwen3.6-flash
中国香港服务部署范围:
千问 Max:qwen3-max
千问 Plus:qwen-plus
千问 Flash:qwen3.6-flash、qwen3.5-flash
千问 VL:qwen3-vl-plus
日本(东京)
不同服务部署范围支持的模型不同。
日本服务部署范围:
千问 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26
全球服务部署范围:
千问 Max:qwen3.7-max、qwen3.7-max-2026-05-20
千问 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26、qwen3.6-plus
千问 Flash:qwen3.6-flash
快速开始
以下示例展示了在 OpenAI 兼容、DashScope 和 Anthropic 兼容协议中,缓存块的创建与命中机制。
OpenAI 兼容
from openai import OpenAI
import os
client = OpenAI(
# 若没有配置环境变量,请将下行替换为:api_key="sk-xxx"
api_key=os.getenv("DASHSCOPE_API_KEY"),
# 如果使用北京地域的模型,需要将base_url替换为:https://{WorkspaceId}.cn-beijing.maas.aliyuncs.com/compatible-mode/v1
base_url="https://{WorkspaceId}.ap-southeast-1.maas.aliyuncs.com/compatible-mode/v1",
)
# 模拟的代码仓库内容,最小可缓存提示词长度为 1024 Token
long_text_content = "<Your Code Here>" * 400
# 发起请求的函数
def get_completion(user_input):
messages = [
{
"role": "system",
"content": [
{
"type": "text",
"text": long_text_content,
# 在此处放置 cache_control 标记,将创建从 messages 数组的开头到当前 content 所在位置的所有内容作为缓存块。
"cache_control": {"type": "ephemeral"},
}
],
},
# 每次的提问内容不同
{
"role": "user",
"content": user_input,
},
]
completion = client.chat.completions.create(
# 选择支持显式缓存的模型
model="qwen3.7-max",
messages=messages,
)
return completion
# 第一次请求
first_completion = get_completion("这段代码的内容是什么")
print(f"第一次请求创建缓存 Token:{first_completion.usage.prompt_tokens_details.cache_creation_input_tokens}")
print(f"第一次请求命中缓存 Token:{first_completion.usage.prompt_tokens_details.cached_tokens}")
print("=" * 20)
# 第二次请求,代码内容一致,只修改了提问问题
second_completion = get_completion("这段代码可以怎么优化")
print(f"第二次请求创建缓存 Token:{second_completion.usage.prompt_tokens_details.cache_creation_input_tokens}")
print(f"第二次请求命中缓存 Token:{second_completion.usage.prompt_tokens_details.cached_tokens}")DashScope
import os
from dashscope import Generation
# 以下为新加坡地域URL,调用时请将WorkspaceId替换为真实的业务空间ID,各地域的URL不同。
dashscope.base_http_api_url = "https://{WorkspaceId}.ap-southeast-1.maas.aliyuncs.com/api/v1"
# 模拟的代码仓库内容,最小可缓存提示词长度为 1024 Token
long_text_content = "<Your Code Here>" * 400
# 发起请求的函数
def get_completion(user_input):
messages = [
{
"role": "system",
"content": [
{
"type": "text",
"text": long_text_content,
# 在此处放置 cache_control 标记,将创建从 messages 数组的开头到当前 content 所在位置的所有内容作为缓存块。
"cache_control": {"type": "ephemeral"},
}
],
},
# 每次的提问内容不同
{
"role": "user",
"content": user_input,
},
]
response = Generation.call(
# 若没有配置环境变量,请用阿里云百炼API Key将下行替换为:api_key = "sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"),
model="qwen3.7-max",
messages=messages,
result_format="message"
)
return response
# 第一次请求
first_completion = get_completion("这段代码的内容是什么")
print(f"第一次请求创建缓存 Token:{first_completion.usage.prompt_tokens_details['cache_creation_input_tokens']}")
print(f"第一次请求命中缓存 Token:{first_completion.usage.prompt_tokens_details['cached_tokens']}")
print("=" * 20)
# 第二次请求,代码内容一致,只修改了提问问题
second_completion = get_completion("这段代码可以怎么优化")
print(f"第二次请求创建缓存 Token:{second_completion.usage.prompt_tokens_details['cache_creation_input_tokens']}")
print(f"第二次请求命中缓存 Token:{second_completion.usage.prompt_tokens_details['cached_tokens']}")// Java SDK 最低版本为 2.21.6
import com.alibaba.dashscope.aigc.generation.Generation;
import com.alibaba.dashscope.aigc.generation.GenerationParam;
import com.alibaba.dashscope.aigc.generation.GenerationResult;
import com.alibaba.dashscope.common.Message;
import com.alibaba.dashscope.common.MessageContentText;
import com.alibaba.dashscope.common.Role;
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.InputRequiredException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import java.util.Arrays;
import java.util.Collections;
public class Main {
private static final String MODEL = "qwen3-coder-plus";
// 模拟代码仓库内容(400次重复确保超过1024 Token)
private static final String LONG_TEXT_CONTENT = generateLongText(400);
private static String generateLongText(int repeatCount) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < repeatCount; i++) {
sb.append("<Your Code Here>");
}
return sb.toString();
}
private static GenerationResult getCompletion(String userQuestion)
throws NoApiKeyException, ApiException, InputRequiredException {
// 以下为新加坡地域URL,调用时请将WorkspaceId替换为真实的业务空间ID,各地域的URL不同。
Generation gen = new Generation("http", "https://{WorkspaceId}.ap-southeast-1.maas.aliyuncs.com/api/v1");
// 构建带缓存控制的系统消息
MessageContentText systemContent = MessageContentText.builder()
.type("text")
.text(LONG_TEXT_CONTENT)
.cacheControl(MessageContentText.CacheControl.builder()
.type("ephemeral") // 设置缓存类型
.build())
.build();
Message systemMsg = Message.builder()
.role(Role.SYSTEM.getValue())
.contents(Collections.singletonList(systemContent))
.build();
Message userMsg = Message.builder()
.role(Role.USER.getValue())
.content(userQuestion)
.build();
// 构建请求参数
GenerationParam param = GenerationParam.builder()
.model(MODEL)
.messages(Arrays.asList(systemMsg, userMsg))
.resultFormat(GenerationParam.ResultFormat.MESSAGE)
.build();
return gen.call(param);
}
private static void printCacheInfo(GenerationResult result, String requestLabel) {
System.out.printf("%s创建缓存 Token: %d%n", requestLabel, result.getUsage().getPromptTokensDetails().getCacheCreationInputTokens());
System.out.printf("%s命中缓存 Token: %d%n", requestLabel, result.getUsage().getPromptTokensDetails().getCachedTokens());
}
public static void main(String[] args) {
try {
// 第一次请求
GenerationResult firstResult = getCompletion("这段代码的内容是什么");
printCacheInfo(firstResult, "第一次请求");
System.out.println(new String(new char[20]).replace('\0', '=')); // 第二次请求
GenerationResult secondResult = getCompletion("这段代码可以怎么优化");
printCacheInfo(secondResult, "第二次请求");
} catch (NoApiKeyException | ApiException | InputRequiredException e) {
System.err.println("API调用失败: " + e.getMessage());
e.printStackTrace();
}
}
}Anthropic 兼容
import anthropic
import os
client = anthropic.Anthropic(
# 若没有配置环境变量,请将下行替换为:api_key="sk-xxx"
api_key=os.getenv("DASHSCOPE_API_KEY"),
# 如果使用北京地域的模型,需要将base_url替换为:https://{WorkspaceId}.cn-beijing.maas.aliyuncs.com/apps/anthropic
base_url="https://{WorkspaceId}.ap-southeast-1.maas.aliyuncs.com/apps/anthropic",
)
# 模拟的代码仓库内容,最小可缓存提示词长度为 1024 Token
long_text_content = "<Your Code Here>" * 400
# 发起请求的函数
def get_completion(user_input):
response = client.messages.create(
# 选择支持显式缓存的模型
model="qwen3.7-max",
max_tokens=1024,
system=[
{
"type": "text",
"text": long_text_content,
# 在此处放置 cache_control 标记,将创建 system text内容作为缓存块,也可放置在messages消息中
"cache_control": {"type": "ephemeral"},
}
],
messages=[
# 每次的提问内容不同
{"role": "user", "content": user_input},
],
)
return response
# 第一次请求
first_completion = get_completion("这段代码的内容是什么")
print(f"第一次请求创建缓存 Token:{first_completion.usage.cache_creation_input_tokens}")
print(f"第一次请求命中缓存 Token:{first_completion.usage.cache_read_input_tokens}")
print("=" * 20)
# 第二次请求,代码内容一致,只修改了提问问题
second_completion = get_completion("这段代码可以怎么优化")
print(f"第二次请求创建缓存 Token:{second_completion.usage.cache_creation_input_tokens}")
print(f"第二次请求命中缓存 Token:{second_completion.usage.cache_read_input_tokens}")模拟的代码仓库内容通过添加 cache_control标记启用显式缓存。后续针对该代码仓库的提问请求,系统可复用该缓存块,无需重新计算,可获得比创建缓存前更快的响应与更低的成本。
第一次请求创建缓存 Token:1605
第一次请求命中缓存 Token:0
====================
第二次请求创建缓存 Token:0
第二次请求命中缓存 Token:1605使用多个缓存标记实现精细控制
在复杂场景中,提示词通常由多个重用频率不同的部分组成。使用多个缓存标记可实现精细控制。
例如,智能客服的提示词通常包括:
系统人设:高度稳定,几乎不变。
外部知识:半稳定,通过知识库检索或工具查询获得,可能在连续对话中保持不变。
对话历史:动态增长。
当前问题:每次不同。
如果将整个提示词作为一个整体缓存,任何微小变化(如外部知识改变)都可能导致无法命中缓存。
在请求中最多可设置四个缓存标记,为提示词的不同部分分别创建缓存块,从而提升命中率并实现精细控制。
如何计费
显式缓存仅影响输入 Token 的计费方式。规则如下:
创建缓存:新创建的缓存内容按标准输入单价的 125% 计费。若新请求的缓存内容包含已有缓存作为前缀,则仅对新增部分计费(即新缓存 Token 数减去已有缓存 Token 数)。
例如:若已有 1200 Token 的缓存 A,新请求需缓存 1500 Token 的内容 AB,则前 1200 Token 按缓存命中计费(标准单价的 10%),新增的 300 Token 按创建缓存计费(标准单价的 125%)。
创建缓存所用的 Token数通过
cache_creation_input_tokens参数查看。命中缓存:按标准输入单价的 10% 计费。
命中缓存的 Token数通过
cached_tokens参数查看。其他 Token:未命中且未创建缓存的 Token 按原价计费。
可缓存内容
仅 messages 数组中的以下消息类型支持添加缓存标记:
系统消息(System Message)
说明若请求包含
tools参数(Function Calling 场景),工具定义会作为系统消息的一部分参与缓存计算。工具定义不支持独立缓存,在工具定义中添加缓存标记会被忽略,缓存标记只能添加在 messages 的 content 中。用户消息(User Message)
使用
qwen3-vl-plus模型创建缓存时,cache_control标记可放置在多模态内容或文本之后,其位置不影响缓存整个用户消息的效果。助手消息(Assistant Message)
工具消息(Tool Message,即工具执行后的结果)
以系统消息为例,需将 content 字段改为数组形式,并添加 cache_control 字段:
{
"role": "system",
"content": [
{
"type": "text",
"text": "<指定的提示词>",
"cache_control": {
"type": "ephemeral"
}
}
]
}此结构同样适用于 messages 数组中的其他消息类型。
缓存限制
最小可缓存提示词长度为 1024 Token。
缓存采用从后向前的前缀匹配策略,系统会自动检查最近的 20 个 content 块。若待匹配内容与带有
cache_control标记的消息之间间隔超过 20 个 content 块,则无法命中缓存。仅支持将
type设置为ephemeral,有效期为 5 分钟。单次请求最多可添加 4 个缓存标记。
若缓存标记个数大于4,则最后四个缓存标记生效。
提高 Function Calling 缓存命中率
由于工具定义会被序列化为 JSON 字符串参与缓存计算,请确保每次请求的工具定义完全一致,以避免缓存失效。具体需注意:
工具列表顺序一致:tools 数组中各工具的排列顺序需保持一致;
字段顺序一致:同一个 tool 的 JSON 字段顺序需保持一致;
字段结构一致:不要遗漏或新增字段,即使该字段为空或可选。
使用示例
隐式缓存
支持的模型
华北2(北京)
以下模型均为中国内地部署范围。
文本生成模型
千问 Max:qwen3.7-max、qwen3.7-max-2026-05-20、qwen3.7-max-2026-06-08、qwen3-max、qwen3-max-preview、qwen-max
千问 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26、qwen-plus
千问 Flash:qwen-flash
千问 Turbo:qwen-turbo
千问 Coder:qwen3-coder-plus、qwen3-coder-flash
DeepSeek:deepseek-v4-pro、deepseek-v4-flash、deepseek-v3.2、deepseek-v3.1、deepseek-v3、deepseek-r1
Kimi:kimi-k2.6、kimi-k2.5、kimi-k2-thinking、Moonshot-Kimi-K2-Instruct
GLM:glm-5.2、glm-5.1、glm-5、glm-4.7、glm-4.6
MiniMax:MiniMax-M2.5
视觉理解模型
千问 VL:qwen3-vl-plus、qwen3-vl-flash、qwen-vl-max、qwen-vl-plus
新加坡
以下模型均为国际部署范围。
文本生成模型
千问 Max:qwen3.7-max、qwen3.7-max-2026-05-20、qwen3.7-max-2026-06-08、qwen3-max、qwen3-max-preview、qwen-max
千问 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26、qwen-plus
千问 Flash:qwen-flash
千问 Turbo:qwen-turbo
千问 Coder:qwen3-coder-plus、qwen3-coder-flash
DeepSeek:deepseek-v4-pro、deepseek-v4-flash、deepseek-v3.2
GLM(阿里云百炼部署):glm-5.1
视觉理解模型
千问 VL:qwen3-vl-plus、qwen3-vl-flash、qwen-vl-max、qwen-vl-plus
美国(弗吉尼亚)
不同服务部署范围支持的模型不同。
全球服务部署范围:
文本生成模型
千问 Max:qwen3.7-max、qwen3.7-max-2026-05-20、qwen3.7-max-2026-06-08、qwen3-max
千问 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26、qwen-plus
千问 Flash:qwen-flash
千问 Coder:qwen3-coder-plus、qwen3-coder-flash
DeepSeek:deepseek-v4-pro、deepseek-v4-flash
Kimi(阿里云百炼部署):kimi-k2.5
GLM(阿里云百炼部署):glm-5.2
视觉理解模型
千问 VL:qwen3-vl-plus、qwen3-vl-flash
美国服务部署范围:
文本生成模型
千问 Plus:qwen-plus-us
千问 Flash:qwen-flash-us
视觉理解模型
千问 VL:qwen3-vl-flash-us
德国(法兰克福)
不同服务部署范围支持的模型不同。
全球服务部署范围:
文本生成模型
千问 Max:qwen3.7-max、qwen3.7-max-2026-05-20、qwen3.7-max-2026-06-08、qwen3-max
千问 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26、qwen-plus
千问 Flash:qwen-flash
千问 Coder:qwen3-coder-plus、qwen3-coder-flash
DeepSeek:deepseek-v4-pro、deepseek-v4-flash
Kimi(阿里云百炼部署):kimi-k2.5
GLM(阿里云百炼部署):glm-5.2
视觉理解模型
千问 VL:qwen3-vl-plus、qwen3-vl-flash
欧盟服务部署范围:
文本生成模型
千问 Max:qwen3-max
千问 Plus:qwen-plus
视觉理解模型
千问 VL:qwen3-vl-plus、qwen3-vl-flash
中国香港
不同服务部署范围支持的模型不同。
全球服务部署范围:
千问 Max:qwen3.7-max、qwen3.7-max-2026-05-20、qwen3.7-max-2026-06-08
千问 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26
GLM(阿里云百炼部署):glm-5.2
中国香港服务部署范围:
本生成模型
千问 Max:qwen3-max
千问 Plus:qwen-plus
视觉理解模型
千问 VL:qwen3-vl-plus
日本(东京)
不同服务部署范围支持的模型不同。
日本服务部署范围:
文本生成模型
千问 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26
DeepSeek(阿里云百炼部署):deepseek-v4-pro、deepseek-v4-flash
全球服务部署范围:
文本生成模型
千问 Max:qwen3.7-max、qwen3.7-max-2026-05-20
千问 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26
DeepSeek(阿里云百炼部署):deepseek-v4-pro、deepseek-v4-flash
GLM(阿里云百炼部署):glm-5.1
Kimi(阿里云百炼部署):kimi-k2.5
工作方式
向支持隐式缓存的模型发送请求时,该功能会自动开启。系统的工作方式如下:
查找:收到请求后,系统基于前缀匹配原则,检查缓存中是否存在请求中
messages数组内容的公共前缀。判断:
若命中缓存,系统直接使用缓存结果进行后续部分的推理。
若未命中,系统按常规处理请求,并将本次提示词的前缀存入缓存,以备后续请求使用。
系统会定期清理长期未使用的缓存数据。上下文缓存命中概率并非100%,即使请求上下文完全一致,仍可能未命中,具体命中概率由系统判定。
qwen3.7-max系列触发隐式缓存的最少 Token 数约为1000,其他模型为256。
提升命中缓存的概率
隐式缓存的命中逻辑是判断不同请求的前缀是否存在重复内容。为提高命中概率,请将重复内容置于提示词开头,差异内容置于末尾。
文本模型:假设系统已缓存"ABCD",则请求"ABE"可能命中"AB"部分,而请求"BCD"则无法命中。
视觉理解模型:
对同一图像或视频进行多次提问:将图像或视频放在文本信息前会提高命中概率。
对不同图像或视频提问同一问题:将文本信息放在图像或视频前面会提高命中概率。
如何计费
开启隐式缓存模式无需额外付费。
当请求命中缓存时,命中的输入 Token 按 cached_token 计费,折扣比例因模型而有差异;未被命中的输入 Token 按标准 input_token 计费。输出 Token 仍按原价计费。
除 deepseek-v4-pro 外的模型:
cached_token单价为input_token单价的 20%deepseek-v4-pro:
cached_token单价不是input_token单价的 20%,具体价格请参见百炼控制台
示例:某请求包含 10,000 个输入 Token,其中 5,000 个命中缓存。费用计算如下:
未命中 Token (5,000):按 100% 单价计费
命中 Token (5,000):按 20% 单价计费
总输入费用相当于无缓存模式的 60%:(50% × 100%) + (50% × 20%) = 60%。
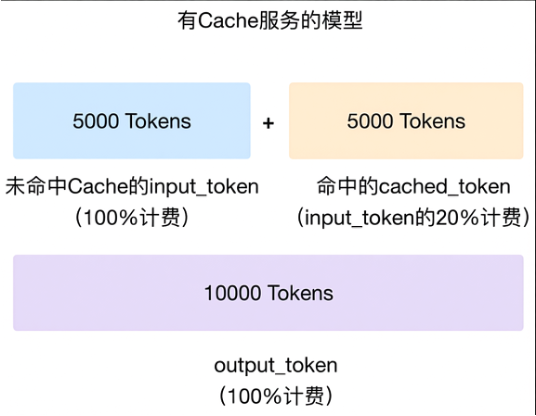
可从返回结果的cached_tokens属性获取命中缓存的 Token 数。
OpenAI兼容-Batch(文件输入)方式调用无法享受缓存折扣。
命中缓存的案例
文本生成模型
OpenAI兼容
当您使用 OpenAI 兼容的方式调用模型并触发了隐式缓存后,可以得到如下的返回结果,在usage.prompt_tokens_details.cached_tokens可以查看命中缓存的 Token 数(该数值为usage.prompt_tokens的一部分)。
{
"choices": [
{
"message": {
"role": "assistant",
"content": "我是阿里云开发的一款超大规模语言模型,我叫千问。"
},
"finish_reason": "stop",
"index": 0,
"logprobs": null
}
],
"object": "chat.completion",
"usage": {
"prompt_tokens": 3019,
"completion_tokens": 104,
"total_tokens": 3123,
"prompt_tokens_details": {
"cached_tokens": 2048
}
},
"created": 1735120033,
"system_fingerprint": null,
"model": "qwen-plus",
"id": "chatcmpl-6ada9ed2-7f33-9de2-8bb0-78bd4035025a"
}DashScope
当您使用DashScope Python SDK 或 HTTP 方式调用模型并触发了隐式缓存后,可以得到如下的返回结果,在usage.prompt_tokens_details.cached_tokens可以查看命中缓存的 Token 数(该数值是 usage.input_tokens 的一部分。)。
{
"status_code": 200,
"request_id": "f3acaa33-e248-97bb-96d5-cbeed34699e1",
"code": "",
"message": "",
"output": {
"text": null,
"finish_reason": null,
"choices": [
{
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "我是一个来自阿里云的大规模语言模型,我叫千问。我可以生成各种类型的文本,如文章、故事、诗歌、故事等,并能够根据不同的场景和需求进行变换和扩展。此外,我还能够回答各种问题,提供帮助和解决方案。如果您有任何问题或需要帮助,请随时告诉我,我会尽力提供支持。请注意,连续重复相同的内容可能无法获得更详细的答复,建议您提供更多具体信息或变化提问方式以便我更好地理解您的需求。"
}
}
]
},
"usage": {
"input_tokens": 3019,
"output_tokens": 101,
"prompt_tokens_details": {
"cached_tokens": 2048
},
"total_tokens": 3120
}
}Anthropic 兼容
当您使用 Anthropic 兼容的方式调用模型并触发了隐式缓存后,命中缓存的 Token 数通过 usage.cache_read_input_tokens 查看(该数值不计入 usage.input_tokens,而是单独报告)。
{
"id": "msg_01XFDUDYJgAACzvnptvVoYEL",
"type": "message",
"role": "assistant",
"content": [
{
"type": "text",
"text": "这段内容是重复的占位文本"
}
],
"model": "qwen3.7-max",
"stop_reason": "end_turn",
"usage": {
"input_tokens": 82,
"cache_creation_input_tokens": 0,
"cache_read_input_tokens": 1536,
"output_tokens": 14
}
}视觉理解模型
OpenAI兼容
当您使用 OpenAI 兼容的方式调用模型并触发了隐式缓存后,可以得到如下的返回结果,在usage.prompt_tokens_details.cached_tokens可以查看命中缓存的 Token 数(该 Token 数是usage.prompt_tokens的一部分)。
{
"id": "chatcmpl-3f3bf7d0-b168-9637-a245-dd0f946c700f",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "这张图像展示了一位女性和一只狗在海滩上互动的温馨场景。女性穿着格子衬衫,坐在沙滩上,面带微笑地与狗进行互动。狗是一只大型的浅色犬种,戴着彩色的项圈,前爪抬起,似乎在与女性握手或击掌。背景是广阔的海洋和天空,阳光从画面的右侧照射过来,给整个场景增添了一种温暖而宁静的氛围。",
"refusal": null,
"role": "assistant",
"audio": null,
"function_call": null,
"tool_calls": null
}
}
],
"created": 1744956927,
"model": "qwen-vl-max",
"object": "chat.completion",
"service_tier": null,
"system_fingerprint": null,
"usage": {
"completion_tokens": 93,
"prompt_tokens": 1316,
"total_tokens": 1409,
"completion_tokens_details": null,
"prompt_tokens_details": {
"audio_tokens": null,
"cached_tokens": 1152
}
}
}DashScope
当您使用DashScope Python SDK 或 HTTP 方式调用模型并触发了隐式缓存后,命中缓存的Token数包含在总输入Token(usage.input_tokens)中,具体查看位置因地域和模型而异:
北京地域:
qwen-vl-max、qwen-vl-plus:在usage.prompt_tokens_details.cached_tokens查看qwen3-vl-plus、qwen3-vl-flash:在usage.prompt_tokens_details.cached_tokens查看
新加坡地域:所有模型均查看
usage.cached_tokens
目前使用usage.cached_tokens的模型,后续将升级至usage.prompt_tokens_details.cached_tokens。
{
"status_code": 200,
"request_id": "06a8f3bb-d871-9db4-857d-2c6eeac819bc",
"code": "",
"message": "",
"output": {
"text": null,
"finish_reason": null,
"choices": [
{
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": [
{
"text": "这张图像展示了一位女性和一只狗在海滩上互动的温馨场景。女性穿着格子衬衫,坐在沙滩上,面带微笑地与狗进行互动。狗是一只大型犬,戴着彩色项圈,前爪抬起,似乎在与女性握手或击掌。背景是广阔的海洋和天空,阳光从画面右侧照射过来,给整个场景增添了一种温暖而宁静的氛围。"
}
]
}
}
]
},
"usage": {
"input_tokens": 1292,
"output_tokens": 87,
"input_tokens_details": {
"text_tokens": 43,
"image_tokens": 1249
},
"total_tokens": 1379,
"output_tokens_details": {
"text_tokens": 87
},
"image_tokens": 1249,
"cached_tokens": 1152
}
}Anthropic 兼容
当您使用 Anthropic兼容的方式调用视觉理解模型并触发了隐式缓存后,命中缓存的 Token 数会体现在 usage.cache_read_input_tokens 字段中(与文本生成模型一致)。
{
"id": "msg_01XFDUDYJgAACzvnptvVoYEL",
"type": "message",
"role": "assistant",
"content": [
{
"type": "text",
"text": "这张图片展示了一位女性和一只狗在海滩上互动的温馨场景。"
}
],
"model": "qwen-vl-max",
"stop_reason": "end_turn",
"usage": {
"input_tokens": 369,
"cache_creation_input_tokens": 0,
"cache_read_input_tokens": 896,
"output_tokens": 28
}
}典型场景
如果您的不同请求有着相同的前缀信息,上下文缓存可以有效提升这些请求的推理速度,降低推理成本与首包延迟。以下是几个典型的应用场景:
基于长文本的问答
适用于需要针对固定的长文本(如小说、教材、法律文件等)发送多次请求的业务场景。
第一次请求的消息数组
messages = [{"role": "system","content": "你是一个语文老师,你可以帮助学生进行阅读理解。"}, {"role": "user","content": "<文章内容> 这篇课文表达了作者怎样的思想感情?"}]之后请求的消息数组
messages = [{"role": "system","content": "你是一个语文老师,你可以帮助学生进行阅读理解。"}, {"role": "user","content": "<文章内容> 请赏析这篇课文的第三自然段。"}]虽然提问的问题不同,但都基于同一篇文章。相同的系统提示和文章内容构成了大量重复的前缀信息,有较大概率命中缓存。
代码自动补全
在代码自动补全场景,大模型会结合上下文中存在的代码进行代码自动补全。随着用户的持续编码,代码的前缀部分会保持不变。上下文缓存可以缓存之前的代码,提升补全速度。
多轮对话
实现多轮对话需要将每一轮的对话信息添加到 messages 数组中,因此每轮对话的请求都会存在与前轮对话前缀相同的情况,有较高概率命中缓存。
第一轮对话的消息数组
messages=[{"role": "system","content": "You are a helpful assistant."}, {"role": "user","content": "你是谁?"}]第二轮对话的消息数组
messages=[{"role": "system","content": "You are a helpful assistant."}, {"role": "user","content": "你是谁?"}, {"role": "assistant","content": "我是由阿里云开发的千问。"}, {"role": "user","content": "你能干什么?"}]随着对话轮数的增加,缓存带来的推理速度优势与成本优势会更明显。
角色扮演或 Few Shot
在角色扮演或 Few-shot 学习的场景中,您通常需要在提示词中加入大量信息来指引大模型的输出格式,这样不同的请求之间会有大量重复的前缀信息。
以让大模型扮演营销专家为例,System prompt包含有大量文本信息,以下是两次请求的消息示例:
system_prompt = """你是一位经验丰富的营销专家。请针对不同产品提供详细的营销建议,格式如下: 1. 目标受众:xxx 2. 主要卖点:xxx 3. 营销渠道:xxx ... 12. 长期发展策略:xxx 请确保你的建议具体、可操作,并与产品特性高度相关。""" # 第一次请求的user message 提问关于智能手表 messages_1=[ {"role": "system", "content": system_prompt}, {"role": "user", "content": "请为一款新上市的智能手表提供营销建议。"} ] # 第二次请求的user message 提问关于笔记本电脑,由于system_prompt相同,有较大概率命中 Cache messages_2=[ {"role": "system", "content": system_prompt}, {"role": "user", "content": "请为一款新上市的笔记本电脑提供营销建议。"} ]使用上下文缓存后,即使用户频繁更换询问的产品类型(如从智能手表到笔记本电脑),系统也可以在触发缓存后快速响应。
视频理解
在视频理解场景中,如果对同一个视频提问多次,将
video放在text前会提高命中缓存的概率;如果对不同的视频提问相同的问题,则将text放在video前面,会提高命中缓存的概率。以下是对同一个视频请求两次的消息示例:# 第一次请求的user message 提问这段视频的内容 messages1 = [ {"role":"system","content":[{"text": "You are a helpful assistant."}]}, {"role": "user", "content": [ {"video": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250328/eepdcq/phase_change_480p.mov"}, {"text": "这段视频的内容是什么?"} ] } ] # 第二次请求的user message 提问关于视频时间戳相关的问题,由于基于同一个视频进行提问,将video放在text前面,有较大概率命中 Cache messages2 = [ {"role":"system","content":[{"text": "You are a helpful assistant."}]}, {"role": "user", "content": [ {"video": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250328/eepdcq/phase_change_480p.mov"}, {"text": "请你描述下视频中的一系列活动事件,以JSON格式输出开始时间(start_time)、结束时间(end_time)、事件(event),不要输出```json```代码段"} ] } ]
常见问题
Q:如何关闭隐式缓存?
A:无法关闭。隐式缓存对所有适用模型请求开启的前提是对回复效果没有影响,且在命中缓存时降低使用成本,提升响应速度。
Q:为什么创建显式缓存后没有命中?
A:有以下可能原因:
创建后 5 分钟内未被命中,超过有效期系统将清理该缓存块;
最后一个
content与已存在的缓存块的间隔大于20个content块时,不会命中缓存,建议创建新的缓存块。
Q:显式缓存命中后,是否会重置有效期?
A:是的,每次命中都会将该缓存块的有效期重置为5分钟。
Q:不同账号之间的显式缓存是否会共享?
A:不会。无论是隐式缓存还是显式缓存,数据都在账号级别隔离,不会共享。
Q:相同账号使用不同模型显式缓存是否会共享?
A:不会。缓存数据存在模型间隔离,不会共享。
Q:为什么usage的input_tokens不等于cache_creation_input_tokens和cached_tokens的总和?
A:为了确保模型输出效果,后端服务会在用户提供的提示词之后追加少量 Token(通常在10以内),这些 Token 在 cache_control 标记之后,因此不会被计入缓存的创建或读取,但会计入总的 input_tokens。