在提交Spark on MaxCompute作业后,通过MaxCompute提供的Logview工具能够获取作业日志,以检查作业是否已正常提交并执行。
功能介绍
以logview.odps.aliyun.com开头的URL,称为LogView。Spark on MaxCompute通过Spark-submit方式(DataWorks执行Spark任务时也会产生相应日志)成功提交作业后,MaxCompute会创建一个Instance,并在日志中打印Instance的Logview,根据Logview能够追踪作业的运行情况。
主要包含以下功能:
获取作业类型和状态、各节点的启停调度信息。如图所示:
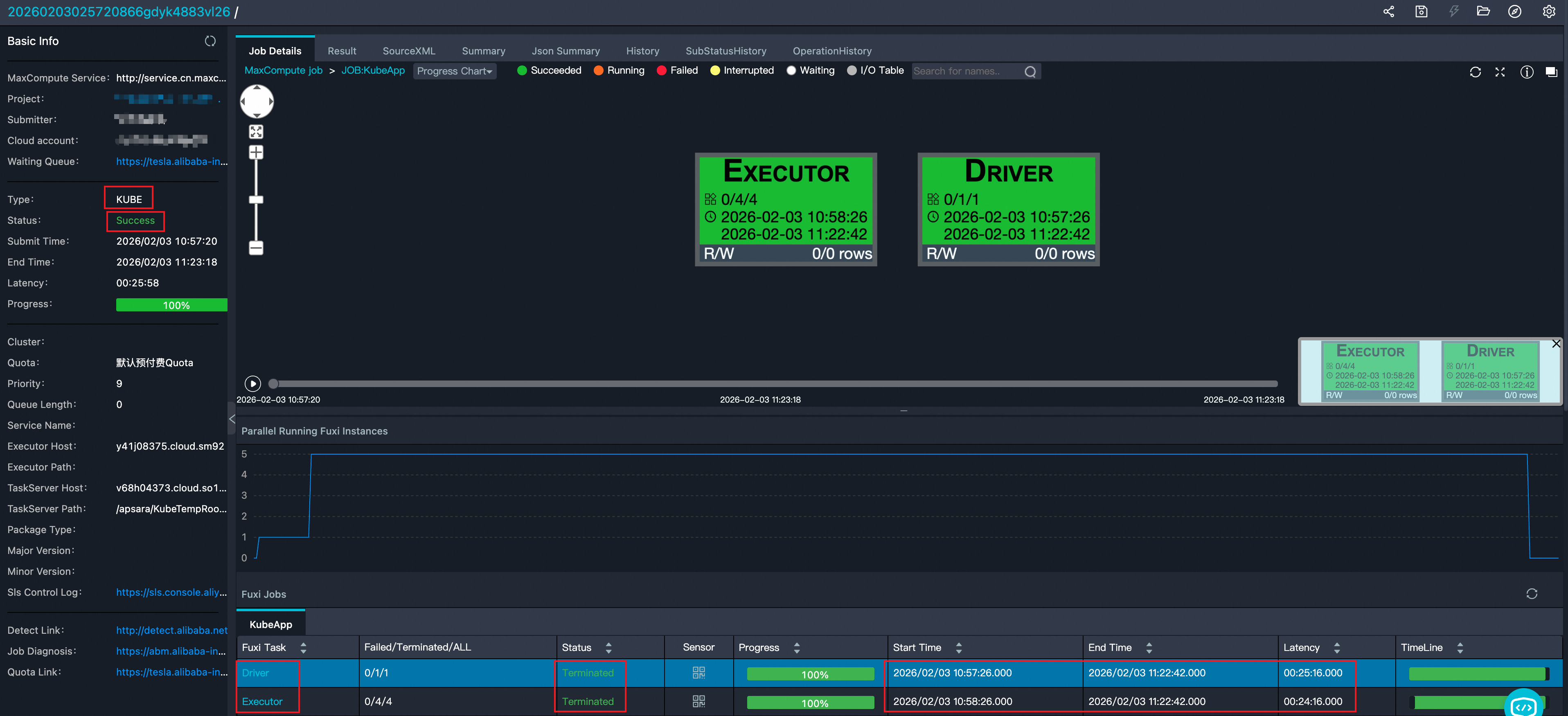
查看Driver以及每个Executor在运行时的内存和CPU使用情况。如上图点击Sensor查看。
获取作业各节点的标准输入输出日志。Spark结果输出建议打印到StdOut,Spark的log4j日志则默认输出到StdErr。如下图所示:
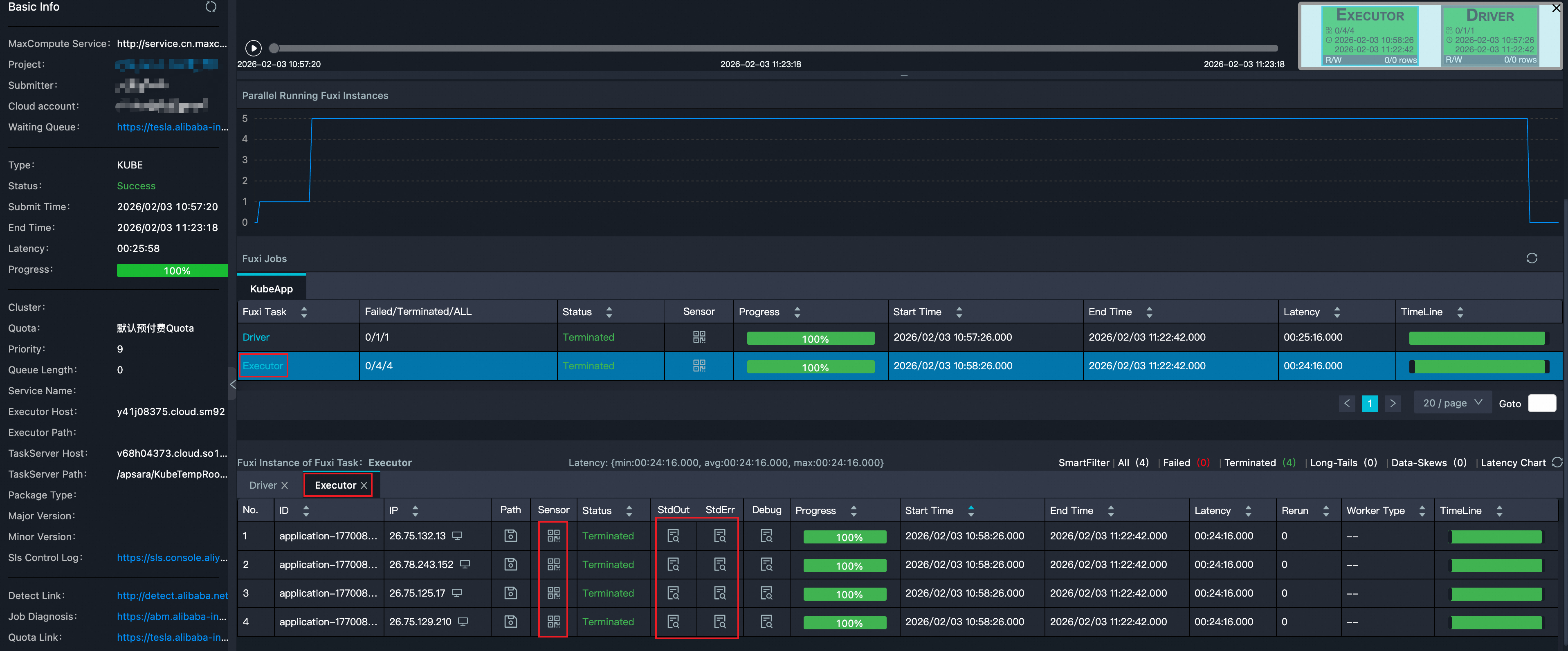
Spark Driver节点日志对应于LogView Master StdOut/StdErr。
Spark Executor节点日志对应于LogView Worker StdOut/StdErr。
通过
System.out.println()输出到控制台的日志会显示在StdOut中。通过log插件打印的日志会显示在StdErr中。
通过System.out.println()输出到控制台的日志会显示在StdOut中。
利用LogView排查问题
在浏览器中打开日志输出的Logview,查看CUPID类型作业的运行情况。
排查过程中首先查看Master Stderr/Stdout 报错,Master一般会包含关键性的错误。更多问题详情请参见Spark常见问题。

出现连接外部服务Time out,参考访问阿里云VPC检查任务配置。
出现类或者方法找不到,参考Java/Scala类冲突问题检查作业打包。
出现Executor连接失败或找不到Chunk等错误,需要进一步查看Executor的报错,是否有OOM问题,参考运行时OOM问题。
出现
System internal error相关的报错日志,可能是配置或平台导致的问题,可以通过工单联系我们进一步排查。
若Executor异常退出,在LogView中的状态为Failed,可以优先查看这些Worker的日志。
使用Sensor查看资源使用情况:
Sensor提供了一种可视化的方式监控运行中的Spark进程,每个worker(Executor)及master(Driver)都具有各自的状态监控图,LogView中入口,如下图所示:

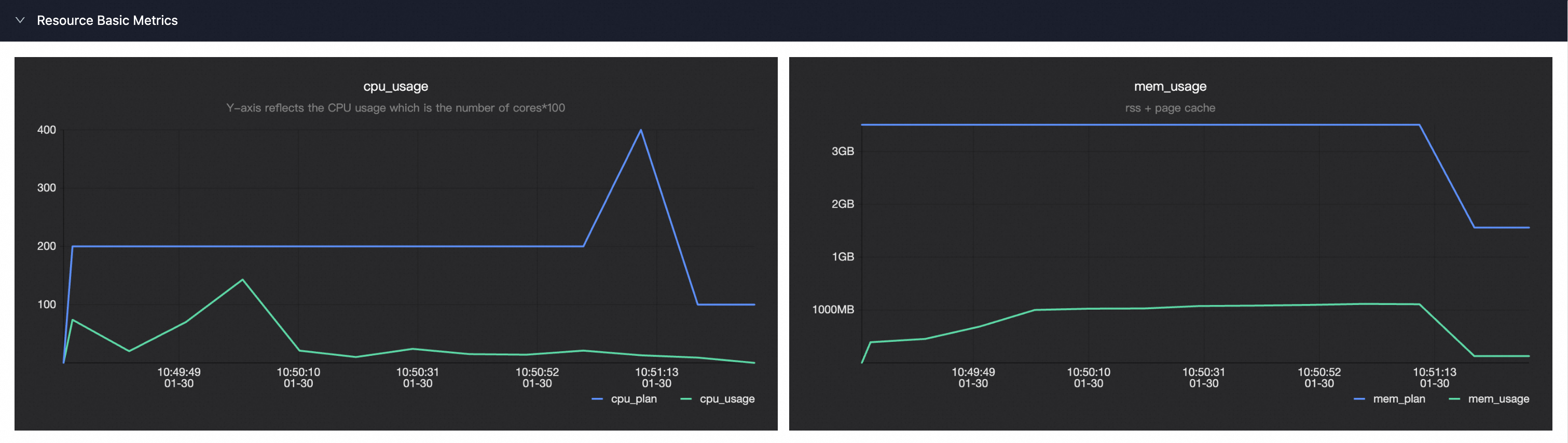
Basic Metrics
下图提供了Master和Worker在其生命周期内的CPU和内存的使用情况:
cpu_usage图展示任务运行中的CPU利用率
memory_usage图展示任务运行中的Memory利用率
cpu_plan/mem_plan(蓝线)代表了用户申请的CPU和内存计划量
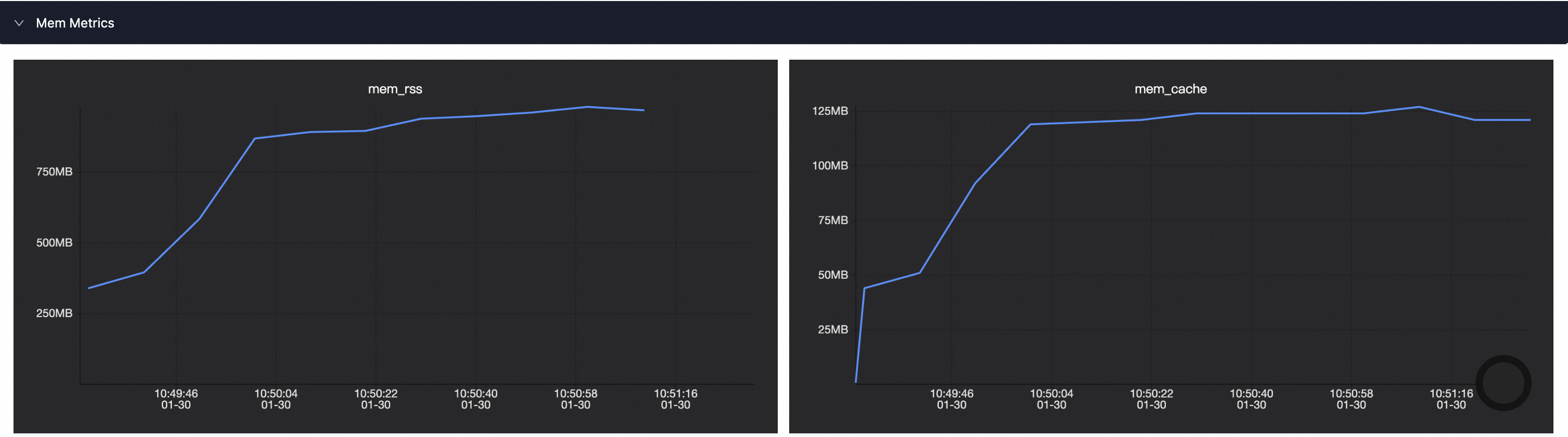
Memory Metrics
下图提供了Spark任务运行所需的实际内存和磁盘中数据缓存所占内存。
mem_rss代表了进程所占用的常驻内存,这部分内存是Spark任务运行所使用的实际内存,通常需要关注,如果该内存超过申请的内存量,就可能会发生OOM,导致Driver/Executor进程终止。
此外,该曲线也可以用于指导内存优化,如果实际使用量远远小于用户申请量,则可以减少内存申请,极大化利用资源,降低成本。
mem_cache(page_cache)用于将磁盘中的数据缓存到内存中,从而减少磁盘I/O操作,通常由系统进行管理,如果物理机内存充足,那么mem_cache可能会使用很多,用户可以不必关心该内存的分配和回收。