使用PyODPS DataFrame编写数据应用时,代码在不同位置执行可能导致问题。本文为您介绍如何确定代码的执行环境,并提供解决方案。
概述
PyODPS是一个Python包而非Python Implementation,其运行环境均为标准的Python,因而并不会出现与正常Python解释器不一致的行为。现通过以下代码示例分析其运行原理和运行环境。
代码示例
from odps import ODPS, options import numpy as np o = ODPS(...) df = o.get_table('pyodps_iris').to_df() coeffs = [0.1, 0.2, 0.4] def handle(v): import numpy as np return float(np.cosh(v)) * sum(coeffs) options.df.supersede_libraries = True val = df.sepal_length.map(handle).sum().execute(libraries=['numpy.zip', 'other.zip']) print(np.sinh(val))代码执行系统
下图展示了代码执行时涉及的系统。代码在MaxCompute外部执行。为了方便表述,下文统称为本地。
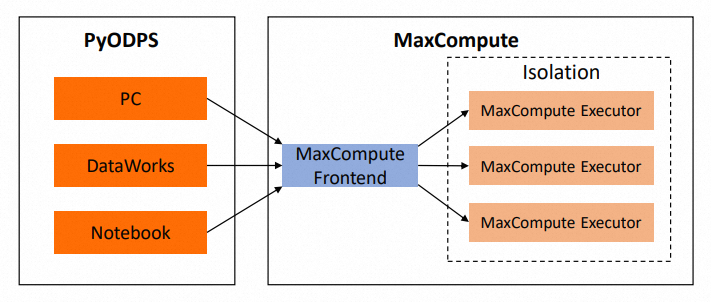
代码分析
引用第三方包
在本地执行的代码包括handle函数之外的部分(注意handle传入map时仅传入了函数本身而并未执行),行为与普通Python code的执行行为类似,导入第三方包时引用的是本地的包。上述代码中,
libraries=['numpy.zip', 'other.zip']中引用的other.zip并没有在本地安装,所以代码中有诸如import other的语句,会导致执行报错。即便other.zip已被上传至MaxCompute资源也是如此,因为本地不存在other.zip包。理论上,本地代码如果不涉及PyODPS包,则与PyODPS无关,执行报错时您需要自行排查。handle函数
handle函数传入map方法时,如果使用的后端是MaxCompute后端,会经历以下几个阶段:
会先被cloudpickle模块提取闭包和字节码。
PyODPS DataFrame使用闭包和字节码生成一个Python UDF,提交至MaxCompute。
作业以SQL的形式在MaxCompute执行时,会调用已生成的Python UDF,其中的字节码和闭包内容会被unpickle(反序列化),然后在MaxCompute Executor执行。
总结
handle函数体中的代码都不会在本地执行,而是在MaxCompute Executor中执行。
handle函数体中无法引用本地安装的包,只有在MaxCompute Executor中存在的包才有效。
上传的第三方包必须兼容MaxCompute Executor的Python版本(目前为Python 2.7,UCS2)。
handle函数体中修改引用的外部变量(例如上述代码中的
coeffs)不会导致本地的coeffs值被修改。在handle函数体中引用在handle外部import的包可能会导致报错。因为在不同环境中,包的结构可能不同,而cloudpickle会将本地包的引用代入MaxCompute Executor,导致报错,因此建议在handle函数体中进行import。
由于使用cloudpickle,如果在handle函数体中调用了其他文件的代码,该文件所在的包必须存在于MaxCompute Executor中。如果您不想使用第三方包的形式解决该问题,请将所有引用的个人代码放在同一个文件中。
上述handle函数的解释对于自定义聚合、apply和map_reduce中调用的自定义方法/Agg类均适用。如果使用的后端是Pandas后端,则所有代码都会在本地运行,因此本地也需要安装相关的包。但鉴于Pandas后端调试完毕后通常会转移到MaxCompute运行,建议在本地安装包的同时,参照MaxCompute后端的惯例进行开发。
使用第三方包
个人电脑/自有服务器:在本地使用第三方包时,在相应的Python版本上安装即可。
Notebook:在本地代码中使用第三方包,请咨询平台提供方。
DataWorks:不支持在本地安装第三方包,但可以在DataWorks环境中进行调用。对于其他文件中的代码,可以通过读取文件+
exec命令的方式在本地进行使用。详情请参见在PyODPS节点中调用第三方包。重要DataStudio中的目录结构并非文件系统中真实存在的目录结构,直接import或打开会导致执行失败。
在DataWorks中上传资源后,需要点击提交确保资源被正确上传到ODPS。
使用自定义的Numpy版本,上传正确的wheel包的,并配置
odps.df.supersede_libraries = True,确保您上传的Numpy包名作为libraries的第一个参数。
引用其他MaxCompute表中的数据
个人电脑/自有服务器/Notebook/DataWorks:在本地访问MaxCompute表,如果Endpoint可以连接,使用PyODPS/DataFrame访问。连接Endpoint时出现问题请咨询平台提供方。
map/apply/map_reduce/自定义聚合:访问其他MaxCompute表,MaxCompute Executor中通常不支持访问Endpoint/Tunnel Endpoint,也没有PyODPS包可用,因此不能直接使用ODPS入口对象或者PyODPS DataFrame,也不能从自定义函数外部传入这些对象。如果表的数据量不大,建议将DataFrame作为资源传入,详情请参见引用资源。如果数据量较大,建议改写为表JOIN。