本文介绍基于Flink创建Paimon Catalog并生成数据,MaxCompute根据Filesystem Catalog创建外部项目,从而直接读取Paimon表数据。
适用范围
只支持Paimon格式表。
不支持写入Dynamic Bucket表。
不支持写入Cross Partition表。
操作步骤
步骤一:源数据准备
如在OSS中已有Paimon表数据,可跳过此步骤。
登录OSS控制台,创建Bucket,本示例中Bucket名为
paimon-fs。详情请参见创建存储空间。在Bucket下新建目录paimon-test。登录Flink控制台,在左上角选择地域。
单击目标工作空间名称,然后在左侧导航栏,选择数据管理。
在右侧Catalog列表 界面,单击创建Catalog 。在弹出的创建 Catalog 对话框里,选择Apache Paimon,单击下一步 并配置如下参数:
参数
是否必填
说明
metastore
必填
元数据存储类型。本示例中选择
filesystem。catalog name
必填
自定义catalog名称,例如
paimon-fs-catalog。warehouse
必填
OSS服务中所指定的数仓目录。本示例中
oss://paimon-fs/paimon-test/。fs.oss.endpoint
必填
OSS服务的endpoint,例如杭州地域为
oss-cn-hangzhou-internal.aliyuncs.com。fs.oss.accessKeyId
必填
访问OSS服务所需的Access Key ID。
fs.oss.accessKeySecret
必填
访问OSS服务所需的Access Key Secret。
基于Paimon Catalog创建Paimon表并写入数据。
在左侧导航栏,选择。
在查询脚本页签,单击
 ,新建查询脚本。
,新建查询脚本。运行如下代码,注意根据实际命名修改代码中的相关命名:
说明由于Flink使用Paimon Catalog,所以会默认遵守Paimon Catalog在文件系统上的组织形式,即
paimon_catalog_name/database_name.db/xxxx。若使用其他引擎读写OSS此目录的Paimon数据,也需要遵守Paimon Catalog在文件系统上的组织形式,并且只存放Paimon格式数据,否则会被识别为异常数据报错。CREATE TABLE `paimon-fs-catalog`.`default`.test_tbl ( id BIGINT, data STRING, dt STRING, PRIMARY KEY (dt, id) NOT ENFORCED ) PARTITIONED BY (dt) WITH ( 'bucket' = '3' ); INSERT INTO `paimon-fs-catalog`.`default`.test_tbl VALUES (1,'CCC','2024-07-18'), (2,'DDD','2024-07-18'),(3,'EEE','2025-06-18');
查看生成的文件。登录OSS控制台,查看Paimon Catalog绑定的OSS目录下生成的Paimon表。
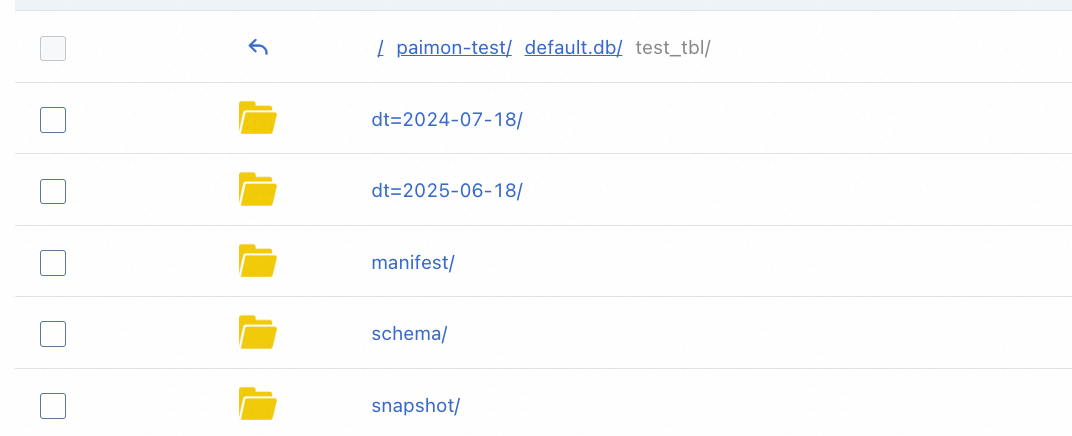
步骤二:MaxCompute创建外部数据源
登录MaxCompute控制台,在左上角选择地域。
在左侧导航栏,选择 。
在外部数据源页面,单击创建外部数据源。
在弹出的新增外部数据源对话框,根据界面提示配置相关参数。参数说明如下:
参数
是否必填
说明
外部数据源类型
必填
选择
Filesystem Catalog。外部数据源名称
必填
可自定义命名。命名规则如下:
以字母开头,且只能包含小写字母、下划线和数字。
不能超过128个字符。
例如
external_fs。外部数据源描述
选填
根据需要填写。
地域
必填
默认为当前地域。
认证和鉴权
必填
默认为阿里云RAM角色。
RoleARN
必填
RAM角色的ARN信息。此角色需要包含能够同时访问DLF和OSS服务的权限。
登录RAM控制台。
在左侧导航栏选择。
在基础信息区域,可以获取ARN信息。
示例:
acs:ram::124****:role/aliyunodpsdefaultrole。存储类型
OSS
OSS-HDFS
Endpoint
自动生成,杭州地域为:
oss-cn-hangzhou-internal.aliyuncs.com。外部数据源补充属性
选填
特殊声明的外部数据源补充属性。指定后,使用此外部数据源的任务可以按照参数定义的行为访问源系统。
说明支持的具体参数请关注后续官网文档更新说明,具体参数将随产品能力演进逐步放开。
单击确认,完成外部数据源的创建。
在外部数据源页面,单击目标数据源对应的操作的详情,可查看数据源详细信息。
步骤三:MaxCompute创建外部项目
登录MaxCompute控制台,在左上角选择地域。
在左侧导航栏,选择。
在外部项目页签,单击新建项目。
在弹出的新增项目对话框,根据界面提示文案配置项目信息,单击确认完成项目创建。
参数
是否必填
说明
项目类型
必填
默认为外部项目。
地域
必填
默认为当前地域,此处无法修改。
项目名称(全网唯一)
必填
字母开头,包含字母、数字及下划线(_),长度在3-28个字符。
MaxCompute外部数据源类型
选填
选择Filesystem Catalog。
MaxCompute外部数据源
选填
选择已有:会出现已经创建过的外部数据源。
新建外部数据源:即可新建并使用新的外部数据源。
MaxCompute外部数据源名称
必填
选择已有:在下拉列表中选择已经创建好的外部数据源名称。
新建外部数据源:则会使用新建的外部数据源名称。
认证和鉴权
必填
任务执行者身份,如未创建服务关联角色,需要先创建才可以使用此模式。
RoleARN
必填
RAM角色的ARN信息。此角色需要包含能够同时访问DLF和OSS服务的权限。
登录RAM控制台。
在左侧导航栏选择。
在基础信息区域,可以获取ARN信息。
示例:
acs:ram::124****:role/aliyunodpsdefaultrole。存储类型
OSS
OSS-HDFS
Endpoint
必填
默认生成。
Bucket 数据目录
必填
选择完整的OSS Bucket和至Catalog级别的文件系统目录。本示例中
oss://paimon-fs/paimon-test/。表格式
必填
默认为Paimon。
计算资源付费类型
必填
包年包月或按量付费。
默认Quota
必填
选择已有Quota.
描述
选填
自定义项目描述。
步骤四:读写Paimon表
选择连接工具登录外部项目。
进入新创建的外部项目,查看已有的Paimon schemas。
-- 打开session级别支持schema语法开关。 SET odps.namespace.schema=true; SHOW schemas; -- 返回结果如下。 ID = 20250922********wbh2u7 default OK读取default schema下的表。
SET odps.sql.allow.fullscan=true; SELECT * FROM <external_project_name>.default.test_tbl; -- 返回结果如下。 +------------+------------+------------+ | id | data | dt | +------------+------------+------------+ | 1 | CCC | 2024-07-18 | | 2 | DDD | 2024-07-18 | | 3 | EEE | 2025-06-18 | +------------+------------+------------+向已存在的Paimon表中写入数据。
INSERT INTO test_tbl PARTITION(dt='2025-08-26') VALUES(4,'FFF'); SELECT * FROM test_tbl; -- 返回结果如下。 +------------+------------+------------+ | id | data | dt | +------------+------------+------------+ | 1 | CCC | 2024-07-18 | | 2 | DDD | 2024-07-18 | | 3 | EEE | 2025-06-18 | | 4 | FFF | 2025-08-26 | +------------+------------+------------+在新建的schema中创建表,并写入数据。
新建一张表写入数据,MaxCompute也会按照Paimon Catalog在文件系统上的组织形式写入新数据。
-- 创建schema。 CREATE schema testschema; -- 在新建的schema中建表。 use schema testschema; CREATE TABLE table_test(id INT, name STRING); -- 在新建的表中插入数据,并读取。 INSERT INTO table_test VALUES (101,'张三'),(102,'李四'); SELECT * FROM table_test; -- 返回结果如下。 +------------+------------+ | id | name | +------------+------------+ | 101 | 张三 | | 102 | 李四 | +------------+------------+登录OSS控制台,在OSS中找到外部项目的Bucket目录,可以看到新建的schema和表。