本文为您介绍如何使用DataWorks数据集成,将Kafka集群上的数据迁移至MaxCompute。
前提条件
新增MaxCompute数据源。详情请参见绑定MaxCompute计算资源。
在DataWorks上完成创建业务流程,本例使用DataWorks简单模式。详情请参见创建业务流程。
搭建Kafka集群
进行数据迁移前,您需要保证自己的Kafka集群环境正常。本文使用阿里云EMR服务自动化搭建Kafka集群,详细过程请参见Kafka快速入门。
本文使用的EMR Kafka版本信息如下:
EMR版本:EMR-3.12.1
集群类型:Kafka
软件信息:Ganglia 3.7.2,ZooKeeper 3.4.12,Kafka 2.11-1.0.1,Kafka-Manager 1.3.X.XX
Kafka集群使用专有网络,区域为华东1(杭州),主实例组ECS计算资源配置公网及内网IP。
背景信息
Kafka是一款分布式发布与订阅的消息中间件,具有高性能、高吞量的特点被广泛使用,每秒能处理上百万的消息。Kafka适用于流式数据处理,主要应用于用户行为跟踪、日志收集等场景。
一个典型的Kafka集群包含若干个生产者(Producer)、Broker、消费者(Consumer)以及一个Zookeeper集群。Kafka集群通过Zookeeper管理自身集群的配置并进行服务协同。
Topic是Kafka集群上最常用的消息的集合,是一个消息存储逻辑概念。物理磁盘不存储Topic,而是将Topic中具体的消息按分区(Partition)存储在集群中各个节点的磁盘上。每个Topic可以有多个生产者向它发送消息,也可以有多个消费者向它拉取(消费)消息。
每个消息被添加到分区时,会分配一个Offset(偏移量,从0开始编号),是消息在一个分区中的唯一编号。
步骤一:准备Kafka数据
您需要在Kafka集群创建测试数据。为保证您可以顺利登录EMR集群Header主机,以及保证MaxCompute和DataWorks可以顺利和EMR集群Header主机通信,请您首先配置EMR集群Header主机安全组,放行TCP 22及TCP 9092端口。
登录EMR集群Header主机地址。
进入EMR Hadoop控制台。
在顶部导航栏,单击集群管理。
在显示的页面,找到您需要创建测试数据的集群,进入集群详情页。
在集群详情页面,单击主机列表,确认EMR集群Header主机地址,并通过SSH链接远程登录。
创建测试Topic。
执行如下命令创建测试所使用的Topic testkafka。
kafka-topics.sh --zookeeper emr-header-1:2181/kafka-1.0.1 --partitions 10 --replication-factor 3 --topic testkafka --create写入测试数据。
执行如下命令,可以模拟生产者向Topic testkafka中写入数据。由于Kafka用于处理流式数据,您可以持续不断地向其中写入数据。为保证测试结果,建议写入10条以上的数据。
kafka-console-producer.sh --broker-list emr-header-1:9092 --topic testkafka您可以同时再打开一个SSH窗口,执行如下命令,模拟消费者验证数据是否已成功写入Kafka。当数据写入成功时,您可以看到已写入的数据。
kafka-console-consumer.sh --bootstrap-server emr-header-1:9092 --topic testkafka --from-beginning
步骤二:在DataWorks上创建目标表
在DataWorks上创建目标表用以接收Kafka数据。
进入数据开发页面。
登录DataWorks控制台。
单击左侧导航栏。
在下拉框中选择对应工作空间后单击进入数据开发。
右键单击指定业务流程,选择。
在弹出的新建表对话框中,填写表名称,并单击新建。
说明表名必须以字母开头,不能包含中文或特殊字符。
如果在数据开发中绑定多个MaxCompute数据源,则按需选择MaxCompute引擎实例。
在表的编辑页面,单击DDL模式。
在DDL对话框中,输入如下建表语句,单击生成表结构。
CREATE TABLE testkafka ( key string, value string, partition1 string, timestamp1 string, offset string, t123 string, event_id string, tag string ) ;其中的每一列,对应于DataWorks数据集成Kafka Reader的默认列:
__key__表示消息的key。
__value__表示消息的完整内容 。
__partition__表示当前消息所在分区。
__headers__表示当前消息headers信息。
__offset__表示当前消息的偏移量。
__timestamp__表示当前消息的时间戳。
您还可以自主命名,详情参见Kafka Reader。
单击提交到生产环境并确认。
步骤三:同步数据
新建独享数据集成资源组。
由于当前DataWorks的公共资源组无法完美支持Kafka插件,您需要使用独享数据集成资源组完成数据同步。详情请参见新增和使用独享数据集成资源组。
新建数据集成节点。
进入数据开发页面,右键单击指定业务流程,选择。
在新建节点对话框中,输入节点名称,并单击确认。
在顶部菜单栏上,单击
 图标。
图标。在脚本模式下,单击顶部菜单栏上的
 图标。
图标。配置脚本,示例代码如下。
{ "type": "job", "steps": [ { "stepType": "kafka", "parameter": { "server": "47.xxx.xxx.xxx:9092", "kafkaConfig": { "group.id": "console-consumer-83505" }, "valueType": "ByteArray", "column": [ "__key__", "__value__", "__partition__", "__timestamp__", "__offset__", "'123'", "event_id", "tag.desc" ], "topic": "testkafka", "keyType": "ByteArray", "waitTime": "10", "beginOffset": "0", "endOffset": "3" }, "name": "Reader", "category": "reader" }, { "stepType": "odps", "parameter": { "partition": "", "truncate": true, "compress": false, "datasource": "odps_source",// MaxCompute数据源名称 "column": [ "key", "value", "partition1", "timestamp1", "offset", "t123", "event_id", "tag" ], "emptyAsNull": false, "table": "testkafka" }, "name": "Writer", "category": "writer" } ], "version": "2.0", "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] }, "setting": { "errorLimit": { "record": "" }, "speed": { "throttle": false, "concurrent": 1 } } }您可以通过在Header主机上使用kafka-consumer-groups.sh --bootstrap-server emr-header-1:9092 --list命令查看group.id参数,及消费者的Group名称。
命令示例
kafka-consumer-groups.sh --bootstrap-server emr-header-1:9092 --list返回结果
_emr-client-metrics-handler-group console-consumer-69493 console-consumer-83505 console-consumer-21030 console-consumer-45322 console-consumer-14773
以console-consumer-83505为例,您可以根据该参数在Header主机上使用kafka-consumer-groups.sh --bootstrap-server emr-header-1:9092 --describe --group console-consumer-83505命令确认beginOffset及endOffset参数。
命令示例。
kafka-consumer-groups.sh --bootstrap-server emr-header-1:9092 --describe --group console-consumer-83505返回结果
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID testkafka 6 0 0 0 - - - test 6 3 3 0 - - - testkafka 0 0 0 0 - - - testkafka 1 1 1 0 - - - testkafka 5 0 0 0 - - -
配置调度资源组。
在节点编辑页面的右侧导航栏,单击调度配置。
在资源属性区域,选择调度资源组为您创建的独享数据集成资源组。
说明如果您需要将Kafka的数据周期性(例如每小时)写入MaxCompute,您可以使用beginDateTime及endDateTime参数,设置数据读取的时间区间为1小时,然后每小时调度一次数据集成任务。详情请参见Kafka Reader。
单击
 图标运行代码。
图标运行代码。您可以在运行日志查看运行结果。
后续步骤
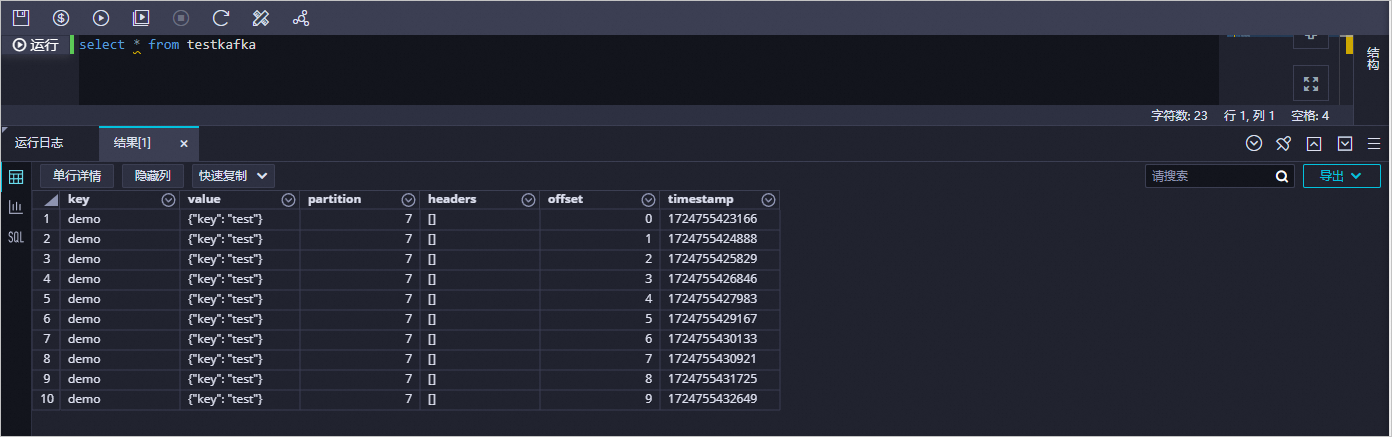
您可以新建一个数据开发任务运行SQL语句,查看当前表中是否已存在从云消息队列 Kafka 版同步过来的数据。本文以select * from testkafka为例,具体步骤如下:
进入数据开发页面。
登录DataWorks控制台。
在左侧导航栏,单击工作空间。进入工作空间列表详情界面。
在顶部切换至目标地域,找到已创建的工作空间,单击操作列的,进入数据开发页面。
单击左侧的
 图标,进入临时查询页面。单击上面的
图标,进入临时查询页面。单击上面的 图标。选择节点。
图标。选择节点。在新建节点对话框中,输入路径、名称信息。
单击确认。
在创建的节点页面,输入
select * from testkafka,单击 图标,运行完成后,查看运行日志。
图标,运行完成后,查看运行日志。