日志服务Logtail支持采集主机CPU、内存、负载、磁盘、网络等监控数据。本文介绍通过Logtail采集主机监控数据的操作步骤。
前提条件
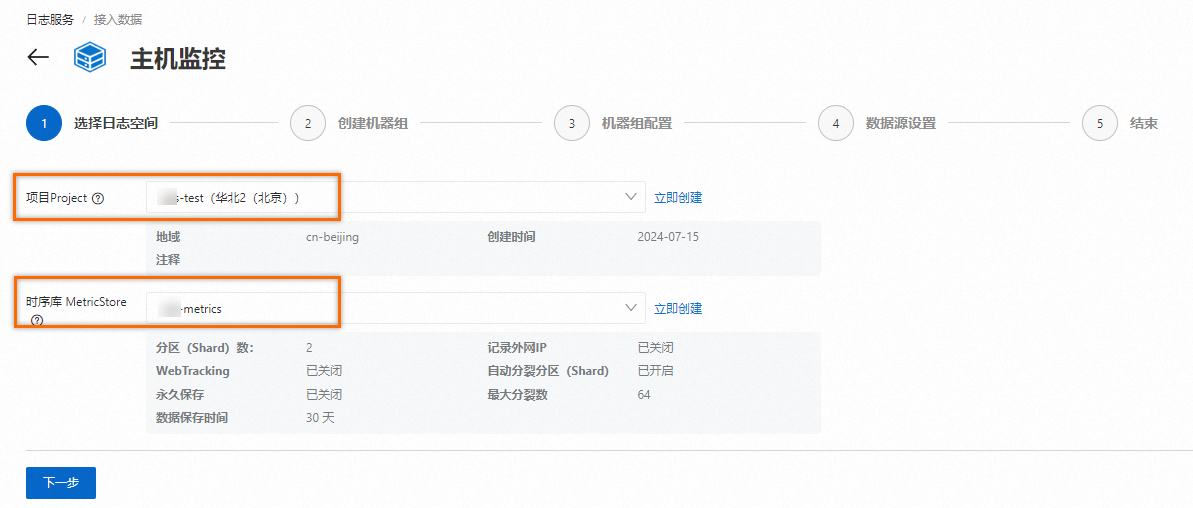
已创建Project和MetricStore。具体操作,请参见创建项目Project和创建MetricStore。
使用限制
不支持Windows版本。
不支持采集GPU、硬件状态等监控数据。
只有Linux Logtail 0.16.40及以上版本的Logtail支持采集主机监控数据。如果您已在服务器上安装旧版本的Logtail,需先升级。具体操作,请参见安装Logtail(Linux系统)。
数据采集配置
登录日志服务控制台。
单击控制台右侧的快速接入数据卡片。

在接入数据页面,查找主机监控并单击。
选择目标Project和时序库MetricStore,单击下一步。
在创建机器组页签中。
如果已有可用的机器组,请单击使用现有机器组。
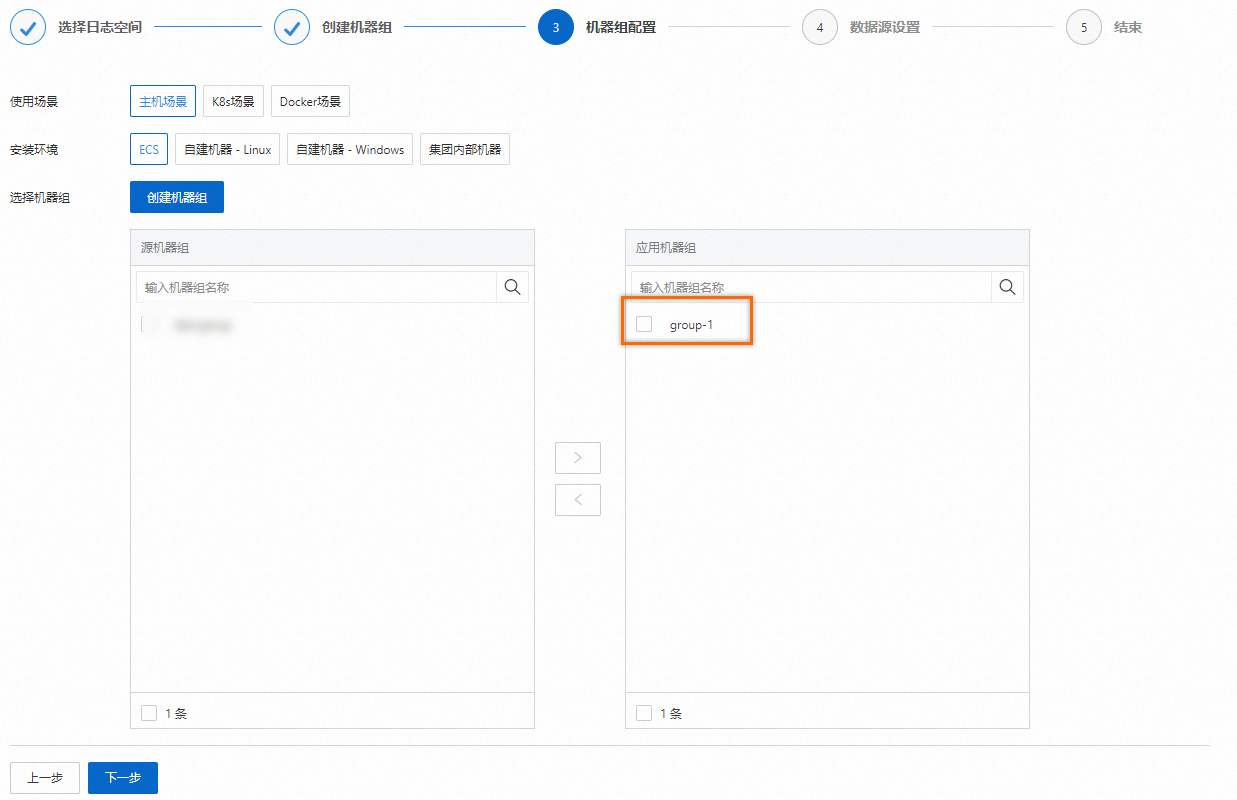
如果您还没有可用的机器组,请执行以下操作(以ECS为例)。
在ECS机器页签中,通过手动选择实例方式选择目标ECS实例,单击创建。
具体操作,请参见安装Logtail(ECS实例)。
重要如果您的服务器是与日志服务属于不同账号的ECS、其他云厂商的服务器和自建IDC时,您需要手动安装Logtail。具体操作,请参见安装Logtail(Linux系统)。手动安装Logtail后,您必须在该服务器上手动配置用户标识。具体操作,请参见配置用户标识。
安装完成后,单击确认安装完毕。
在创建机器组页面,输入名称,单击下一步。
日志服务支持创建IP地址机器组和用户自定义标识机器组,具体操作,请参见创建机器组。
在数据源设置页签中,设置配置名称和插件配置,然后单击下一步。
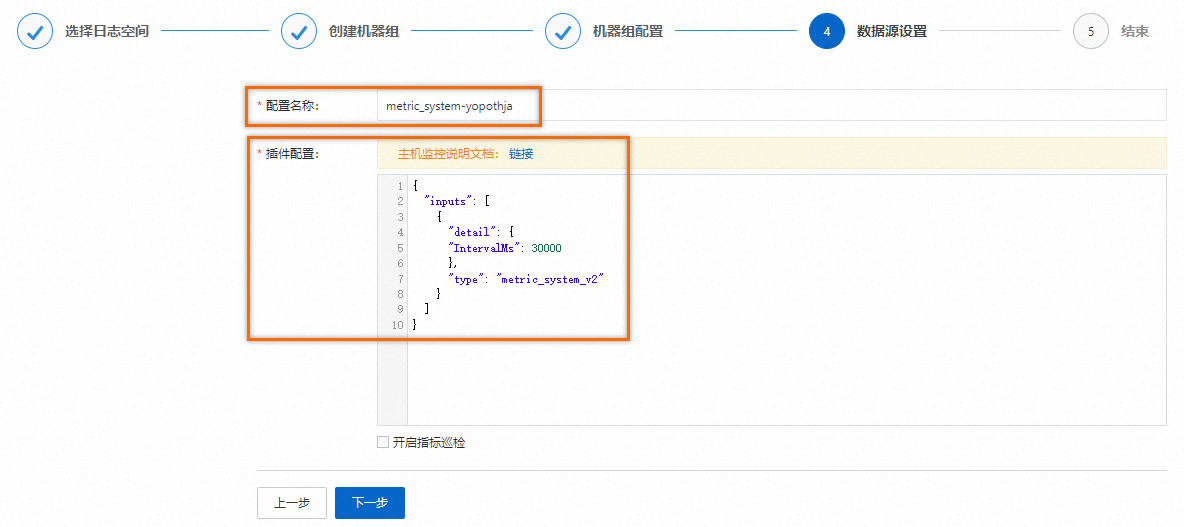 重要
重要inputs为数据源配置,必选项。一个inputs中只允许配置一个类型的数据源。
{ "inputs": [ { "detail": { "IntervalMs": 30000 }, "type": "metric_system_v2" } ] }参数
类型
是否必选
参数说明
type
string
是
数据源类型,固定为metric_system_v2。
IntervalMs
int
是
每次请求的间隔,单位:ms。不能低于5000,建议设置为30000。
单击查询日志,进入时序库。
数据监控
在目标时序库首页单击指标统计,打开指标统计大盘。
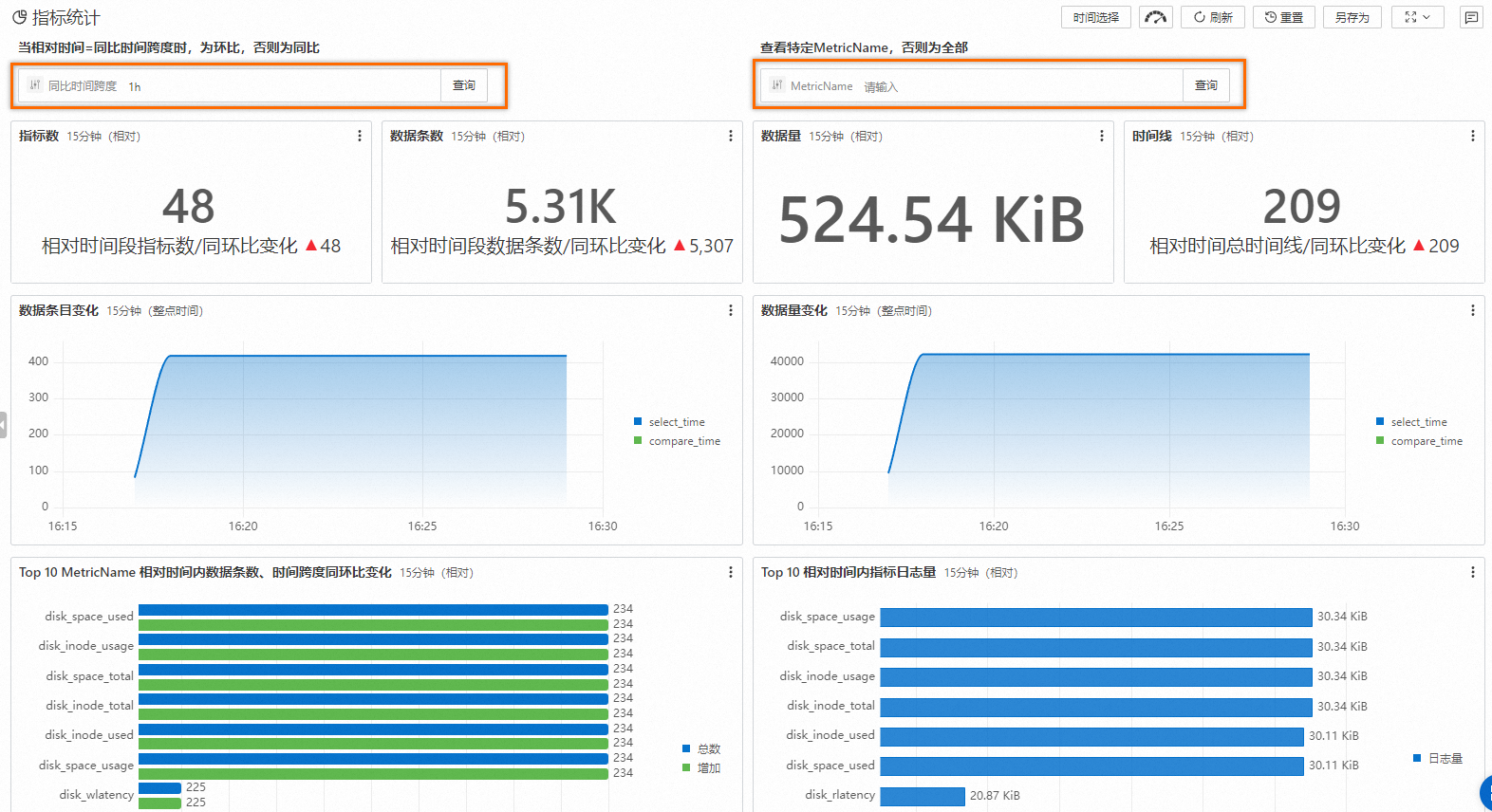
在指标统计查看所有已采集到的数据指标,也可以按时间周期或者指标参数进行数据过滤。
在时序库首页,单击Metrics 探索(指标数:48),可探索、查看和过滤所有可用的指标名称及其元数据。
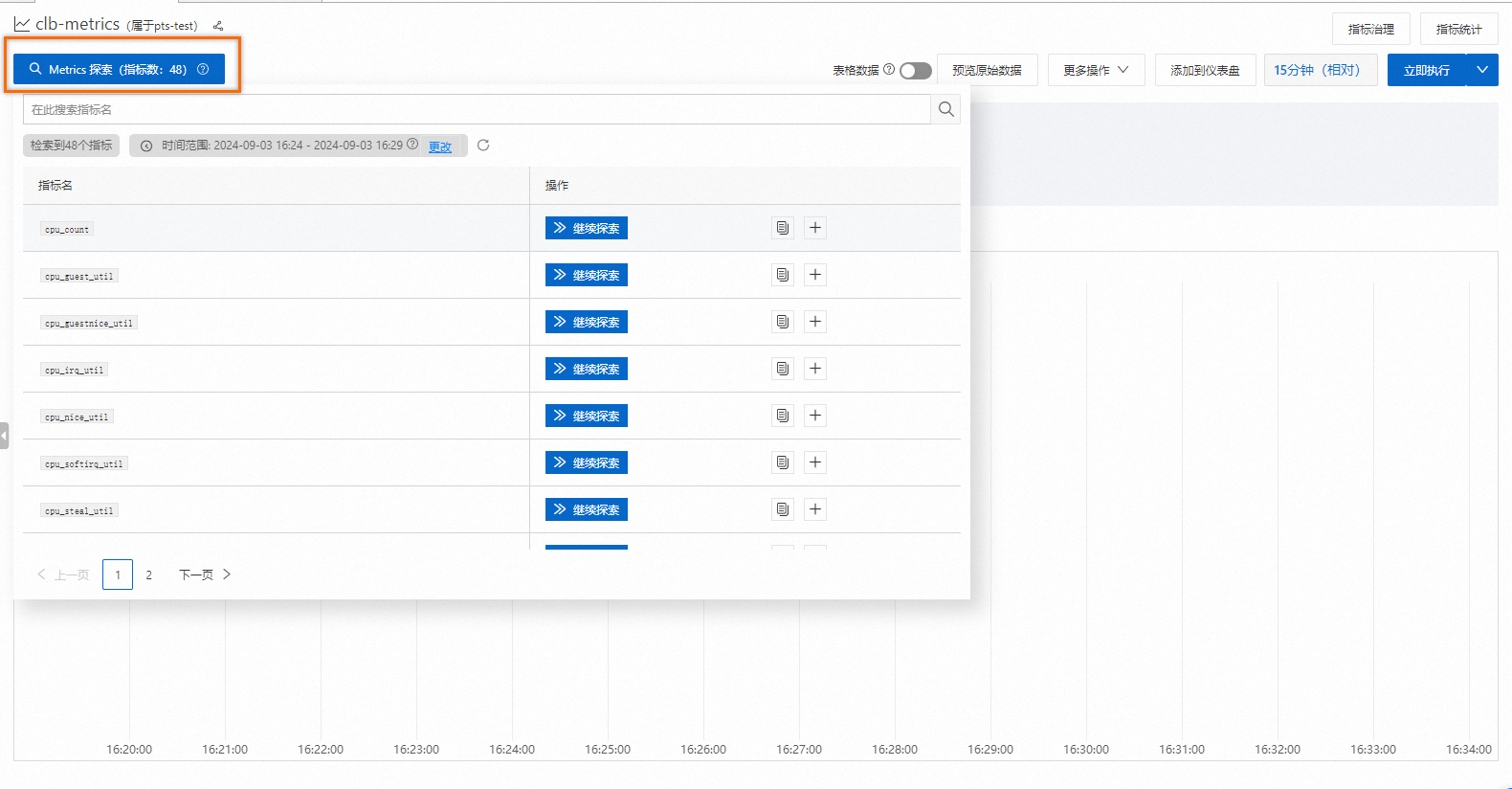 如需查看CPU 和内存数据,可以使用
如需查看CPU 和内存数据,可以使用cpu_count{}和mem_cache{}语句查询。更多查询与分析操作,请参见查询和分析时序数据。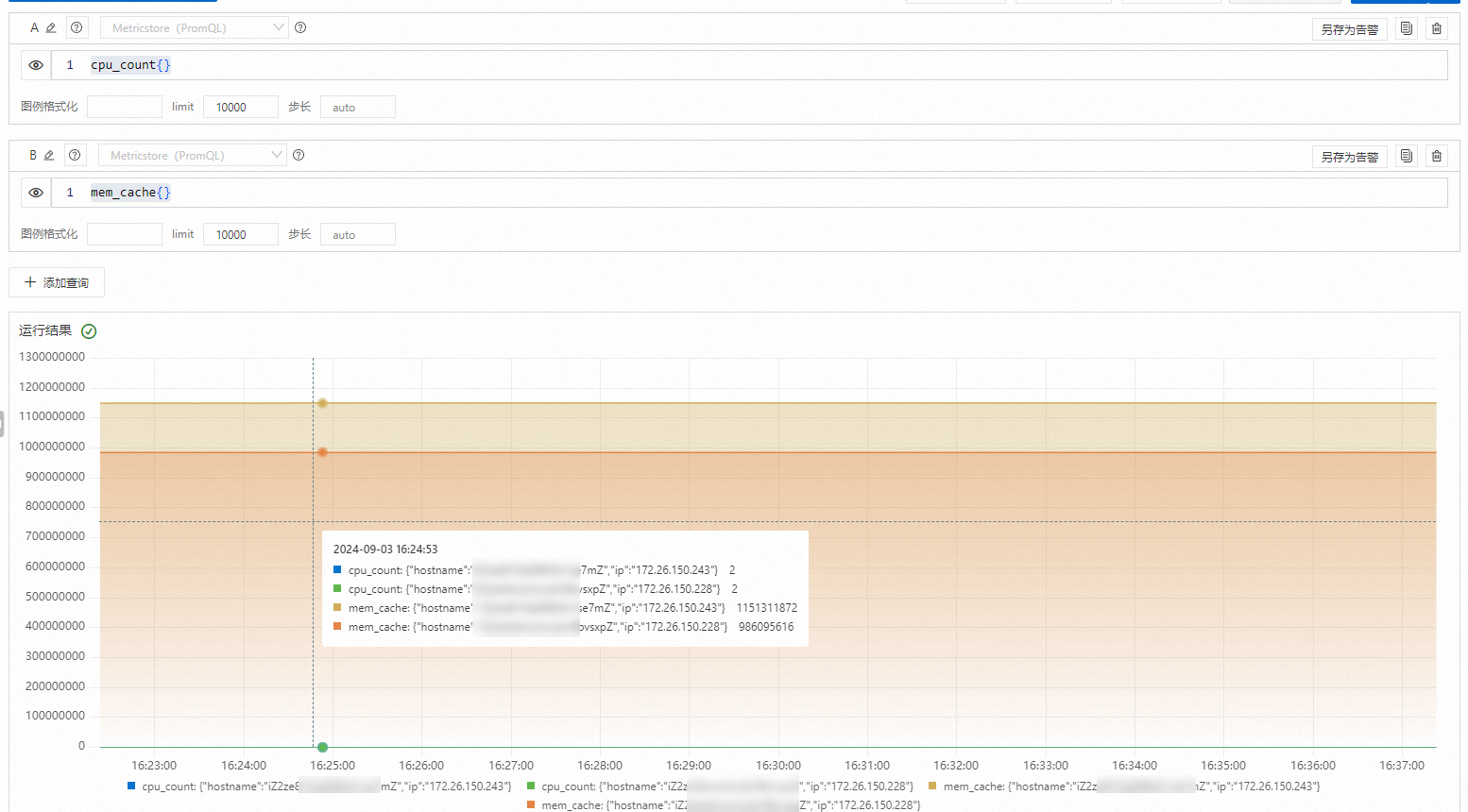
当您采集的数据中包含多台机器时,可使用
hostname或ip进行筛选。为保证筛选数据的准确性,进行筛选前,请先清除历史查询数据。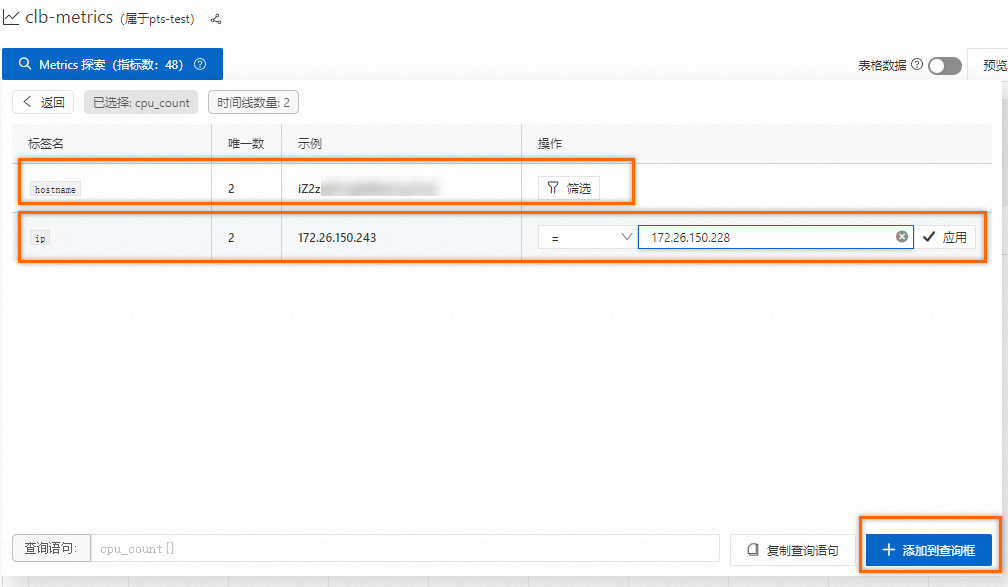
指标说明
主机CPU、内存、负载、磁盘、网络等指标说明如下:
CPU相关指标
指标名
说明
单位
示例
cpu_count
CPU核数
个
2.0
cpu_util
CPU使用率,计算方式为排除idle、wait、steal后的占比
百分号(%)
7.68
cpu_guest_util
客户时间(guest time)占比
百分号(%)
0.0
cpu_guestnice_util
Nice进程客户时间(nice guest time)占比
百分号(%)
0.0
cpu_irq_util
硬中断处理时间(Hard Irq time)占比
百分号(%)
0.0
cpu_nice_util
Nice时间(Nice time)占比
百分号(%)
0.0
cpu_softirq_util
软中断处理时间(Soft Irq time)占比
百分号(%)
0.06
cpu_steal_util
等待宿主机CPU时间(Steal time)占比
百分号(%)
0.0
cpu_sys_util
内核态(System time)占比
百分号(%)
2.77
cpu_user_util
用户态(User time)占比
百分号(%)
4.84
cpu_wait_util
等待IO(Waiting time)占比
百分号(%)
0.11
内存相关指标
指标名
说明
单位
示例
mem_util
内存使用率
百分号(%)
51.03
mem_cache
已申请但未使用的内存
byte
3566386668.0
mem_free
未使用的内存
byte
177350084.0
mem_available
可用内存
byte
3699885553.0
mem_used
已使用内存
byte
4041510463.0
mem_swap_util
swap内存使用率
百分号(%)
0.0
mem_total
内存总量
byte
7919128576.0
磁盘相关指标
指标名
说明
单位
示例
disk_rbps
硬盘每秒读取流量
byte/s
8376.81
disk_wbps
硬盘每秒写入流量
byte/s
247633.58
disk_riops
硬盘每秒读取次数
次/s
0.22
disk_wiops
硬盘每秒写入次数
次/s
43.39
disk_rlatency
平均读延迟
ms
2.83
disk_wlatency
平均写延迟
ms
2.15
disk_util
IO使用率
百分号(%)
0.27
disk_space_usage
磁盘使用百分比
百分号(%)
9.12
disk_inode_usage
inode使用率
百分号(%)
1.18
disk_space_used
磁盘已使用容量
byte
11068512238.59
disk_space_total
磁盘总量
byte
126692061184.0
disk_inode_total
inode总量
个
7864320.0
disk_inode_used
inode已使用容量
个
93054.78
NET相关指标
指标名
说明
单位
示例
net_drop_util
丢弃的数据包占总数据包的比值
百分号(%)
0.0
net_err_util
报错数据包占总数据包的比值
百分号(%)
0.0
net_in
网络接收速率
byte/s
8440.91
net_in_pkt
每秒接收的数据包
个/s
40.83
net_out
网络发送速率
byte/s
12446.53
net_out_pkt
每秒发送的数据包
个/s
39.95
TCP相关指标
指标名
说明
单位
示例
protocol_tcp_established
已建立连接数
个
205.0
protocol_tcp_insegs
接收的所有报文数
个
4654.0
protocol_tcp_outsegs
发送的报文数
个
4870.0
protocol_tcp_retran_segs
重传报文数
个
0.0
protocol_tcp_retran_util
重传报文占总发送报文数量的比值
百分号(%)
0.0
system相关指标
指标名
说明
单位
示例
system_boot_time
系统启动时间
s
1578461935.0
system_load1
系统平均负载,1分钟平均值
不涉及
0.58
system_load5
系统平均负载,5分钟平均值
不涉及
0.68
system_load15
系统平均负载,15分钟平均值
不涉及
0.60
后续步骤
关于日志服务可视化,请参见时序图,时序数据对接Grafana。