Paimon Blob格式是一种专门用于存储大型二进制对象(如图像、视频及其他多模态数据)的格式。与将数据内联存储的其他格式不同,BLOB 格式将大型二进制数据存储在独立的文件中,并采用针对随机访问优化的布局结构。
支持版本
仅esr-4.7.0及之后引擎版本支持本文操作。
Paimon Blob表说明
创建 Paimon Blob 表的关键在于正确定义表结构和表属性。以下是一个标准的 Paimon Blob 表创建模板,其中包含了关键参数的说明。
CREATE TABLE blob_tbl (
fileName STRING,
picture BINARY
)
USING paimon
TBLPROPERTIES (
'row-tracking.enabled' = 'true',
'data-evolution.enabled' = 'true',
'blob-field' = 'picture'
);关键参数说明:
'blob-field' = 'picture': 声明picture字段为 Blob 字段。该字段必须是BINARY类型。'row-tracking.enabled' = 'true': 开启行级别跟踪,是支持MERGE INTO更新和删除操作的前提。'data-evolution.enabled' = 'true': 允许 Schema 演进。
使用示例
本示例演示如何从 OSS 读取图片文件,并将其写入 Paimon Blob 表。
准备测试图片
本文为了带您快速熟悉Paimon Blob 表,为您提供了测试图片,您可以直接下载以供后续步骤使用。
{kind=link}
{kind=link}
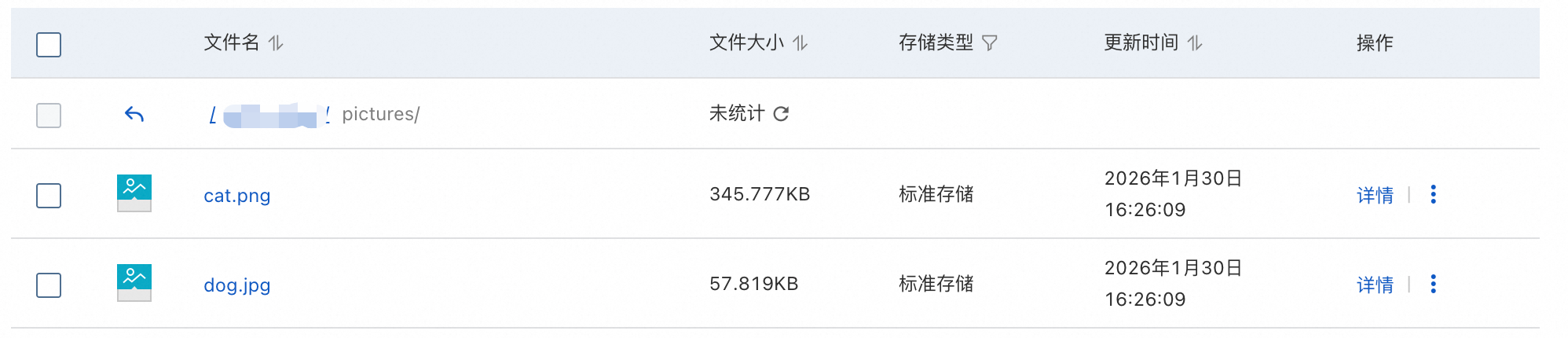
上传测试图片
上传图片到阿里云对象存储OSS控制台,详情请参见简单上传。
开发并运行
在EMR Serverless Spark页面,单击左侧的数据开发。
新建Notebook。
在开发目录页签下,单击
 图标。
图标。在弹出的对话框中,输入名称,类型使用,然后单击确定。
在右上角选择已创建并启动的Notebook会话实例。
您也可以在下拉列表中选择创建Notebook会话,新建一个Notebook会话实例。关于Notebook会话更多介绍,请参见管理Notebook会话。
拷贝如下代码到新增的Notebook的Python单元格中。
from PIL import Image import io from IPython.display import display from pyspark.sql.functions import input_file_name, col, monotonically_increasing_id, regexp_extract # 1. 递归读取OSS下的图片文件 df = ( spark.read.format("binaryFile") .option("recursiveFileLookup", "true") .load("oss://<yourBucketName>/<yourPicturePath>/") ) # 2. 提取文件名和图片二进制数据 df_with_id = ( df.select( col("content").alias("picture"), regexp_extract(input_file_name(), r".*/(.+)$", 1).alias("fileName") ) .select("fileName", "picture") ) # 3. 创建临时视图 df_with_id.createOrReplaceTempView("temp_images") # 4. 预览元数据 print("Preview of image metadata (first few rows):") spark.sql("SELECT fileName, length(picture) AS size_bytes FROM temp_images LIMIT 5").show(truncate=False) # 5. 创建 blob 表 spark.sql("DROP TABLE IF EXISTS blob_tbl") spark.sql(""" CREATE TABLE blob_tbl ( fileName STRING, picture BINARY ) USING paimon TBLPROPERTIES ( 'row-tracking.enabled' = 'true', 'data-evolution.enabled' = 'true', 'blob-field' = 'picture' ) """) # 6. 写入数据 print("Writing images to 'blob_tbl'...") spark.sql("INSERT INTO blob_tbl SELECT * FROM temp_images") # 7. 读取并展示前两张图片 print("\nFetching and displaying the first 2 images from the table...\n") result_df = spark.sql("SELECT fileName, picture FROM blob_tbl LIMIT 2") rows = result_df.collect() if not rows: print("No images found in the table.") else: for i, row in enumerate(rows, start=1): print(f"[{i}] Displaying: {row.fileName}") try: img = Image.open(io.BytesIO(row.picture)) display(img) except Exception as e: print(f" ⚠️ Failed to load image: {e}")单击运行所有单元格,在下方查看运行结果。


相关文档
Paimon Blob 表更多用法,请参考Blob Storage。