本文为您介绍如何使用DTS RAGFlow构建云原生数据仓库AnalyticDB PostgreSQL版GraphRAG。通过该方案,可以为知识库构建知识图谱,实现对复杂关联问题的深度理解和精准检索,超越传统向量检索的局限。
当前功能目前正处于邀测阶段。如您有相关需求,请提交工单与我们联系,以便为您开启该功能。
业务场景说明
在处理包含复杂实体关系和深层逻辑的知识库(例如,金融风控报告、多产品技术手册、企业组织架构文档)时,传统的基于向量相似度的RAG(检索增强生成)方案常常难以准确回答涉及多步推理或关系挖掘的查询。例如,“对比A产品和B产品在C场景下的优缺点”或“查询与项目X相关的所有团队成员及其负责模块”,这类问题需要理解实体间的内在联系,而非仅仅是文本表面的相似性。
GraphRAG通过在传统向量检索的基础上引入知识图谱,将非结构化文本中隐含的实体和关系显式化、结构化。这使得系统能够通过图检索定位到与问题相关的结构化子图,为大型语言模型(LLM)提供更丰富、更具上下文逻辑的背景信息,从而显著提升对复杂、多跳查询的回答质量。
方案架构
本方案整合了DTS RAGFlow的数据处理能力和云原生数据仓库AnalyticDB PostgreSQL版的图分析引擎,构建一个从文档到知识图谱再到智能问答的完整链路。
工作流程说明:
数据注入与处理:将非结构化文档上传至DTS RAGFlow知识库。
知识抽取与存储:
RAGFlow自动对文档进行解析、分片(Chunking)和向量化(Embedding)。
启用GraphRAG后,RAGFlow会调用知识抽取算子,从文本中提取实体-关系-实体(S-P-O)三元组。
向量化的文本Chunk和提取出的知识图谱数据(实体与边)被一同写入指定的云原生数据仓库AnalyticDB PostgreSQL版实例中进行统一存储。
混合检索:
在检索测试或通过API发起查询时,系统会执行混合检索。
查询首先进行向量检索,找到相关的文本Chunk。
同时,查询在云原生数据仓库AnalyticDB PostgreSQL版的图分析引擎中进行图检索,找到与问题相关的实体和关联子图。
上下文增强与生成:系统将向量检索到的文本Chunk和图检索到的关联子图一并作为上下文(Context)提交给LLM,由LLM基于这些丰富的信息生成最终回答。
实施步骤
步骤一:环境准备
创建云原生数据仓库AnalyticDB PostgreSQL版实例。
内核版本需为7.3及以上版本。
开通GraphRAG服务,完成安装对应插件即可。
在DTS中创建RAGFlow知识库并设置IP白名单。
步骤二:配置知识库并启用GraphRAG
此步骤将DTS RAGFlow知识库与AnalyticDB for PostgreSQL实例进行关联。
进入目标地域的RAGFlow知识库列表页面。
登录数据传输服务DTS控制台。
在左侧导航栏,单击数据准备。
在页面左上角,选择数据准备实例所属地域。
单击RAGFlow 知识库页签。
登录RAGFlow。
在目标RAGFlow知识库的操作列,单击管理。
说明您也可以单击操作列的登录知识库,选择内网或外网进行登录。
在连接地址区域,单击登录外网地址或登录内网地址。
说明若您需要通过外网地址访问RAGFlow知识库,需为该实例开通外网地址。
在登录页面,填入账户的邮箱和密码,并单击登录。
在RAGFlow页面,进行管理知识库等操作。
说明操作方法,请参见RAGFlow官方文档。
单击创建知识库,在知识库创建页面,输入知识库名称,然后找到并启用GraphRAG开关。
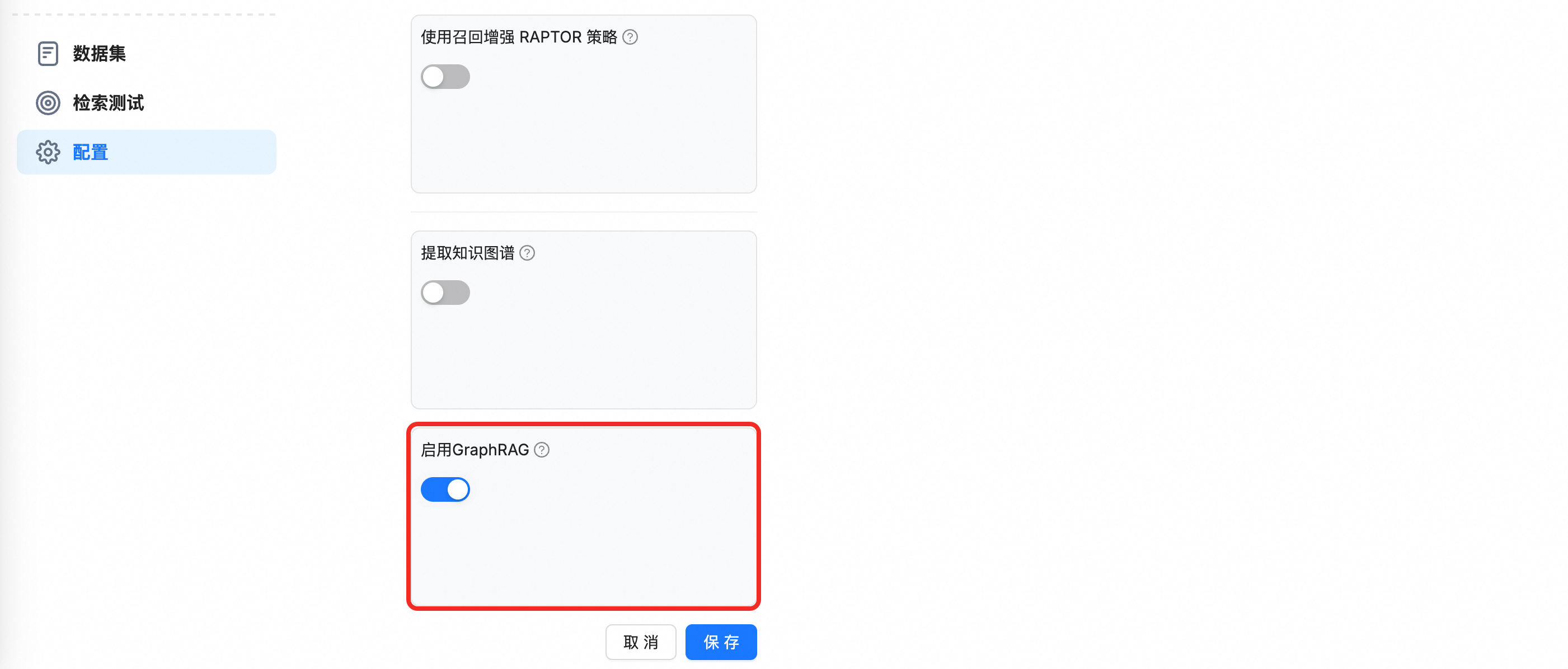 说明
说明创建知识库时,需先在模型提供商中添加嵌入模型和LLM,然后在中设置它们。
若您需要在DTS RAGFlow知识库中嵌入外部模型和LLM,则DTS RAGFlow知识库所在的专有网络VPC配置NAT网关,以便允许其访问外部网络。
创建公网NAT网关:请前往NAT 网关 - 公网 NAT 网关购买页进行创建。在创建过程中,请确保选择与DTS RAGFlow知识库相同的VPC和交换机。
配置SNAT条目:前往公网 NAT 网关页面。单击目标网关操作列的设置SNAT,单击创建SNAT条目。参数请按如下配置:
SNAT条目粒度:VPC粒度。
选择弹性公网IP地址:在下拉列表中选择提供公网访问的EIP。
步骤三:上传文档并构建知识图谱
在新创建的知识库中,单击数据集中新增文件,选择一个本地文件进行上传。
文件上传后,RAGFlow会自动执行解析、Chunk、Embedding等一系列处理流程。由于已启用GraphRAG,系统还会额外进行知识抽取,并将生成的实体和边数据写入已配置的云原生数据仓库AnalyticDB PostgreSQL版中,完成知识图谱的构建。
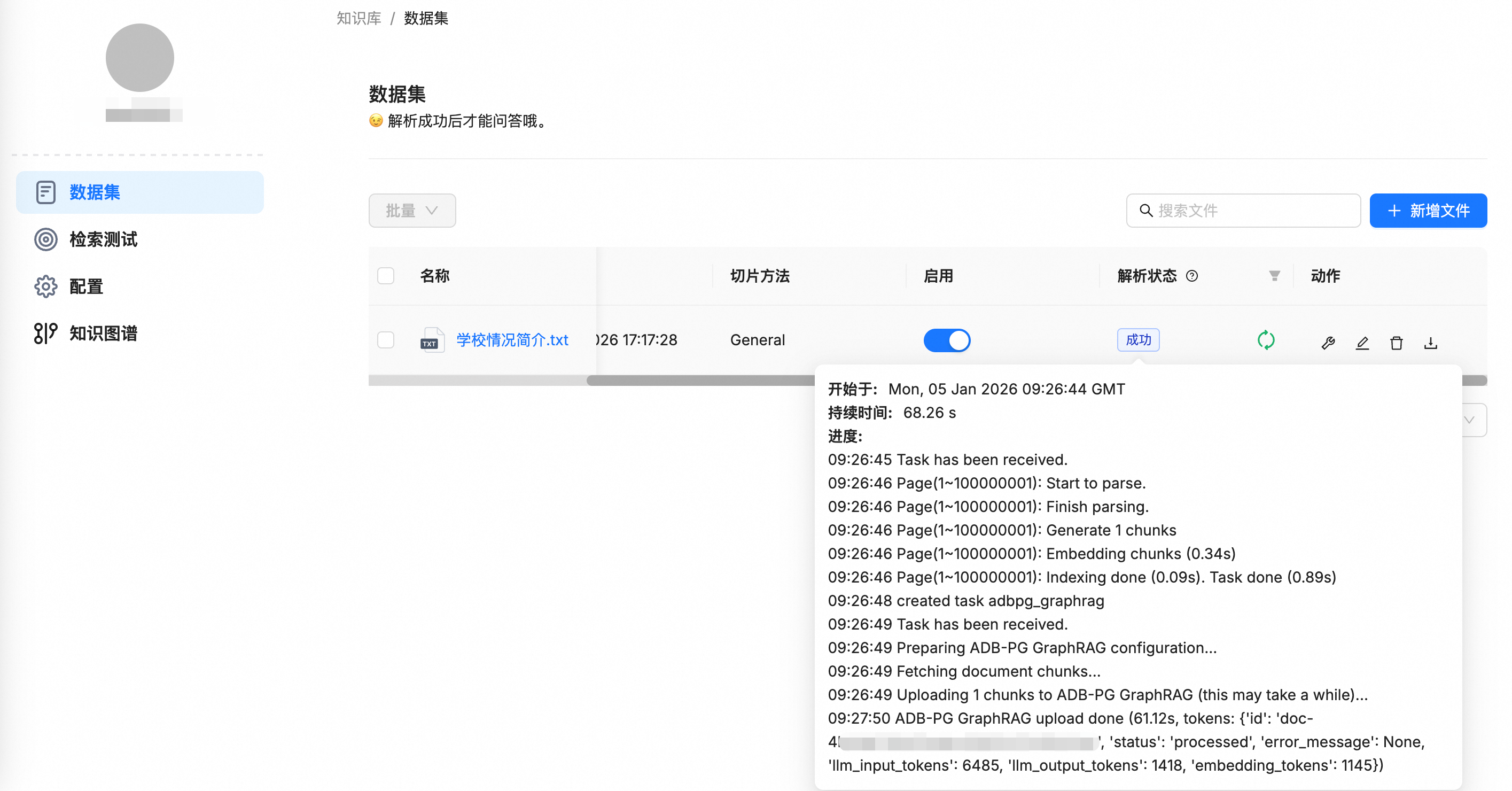
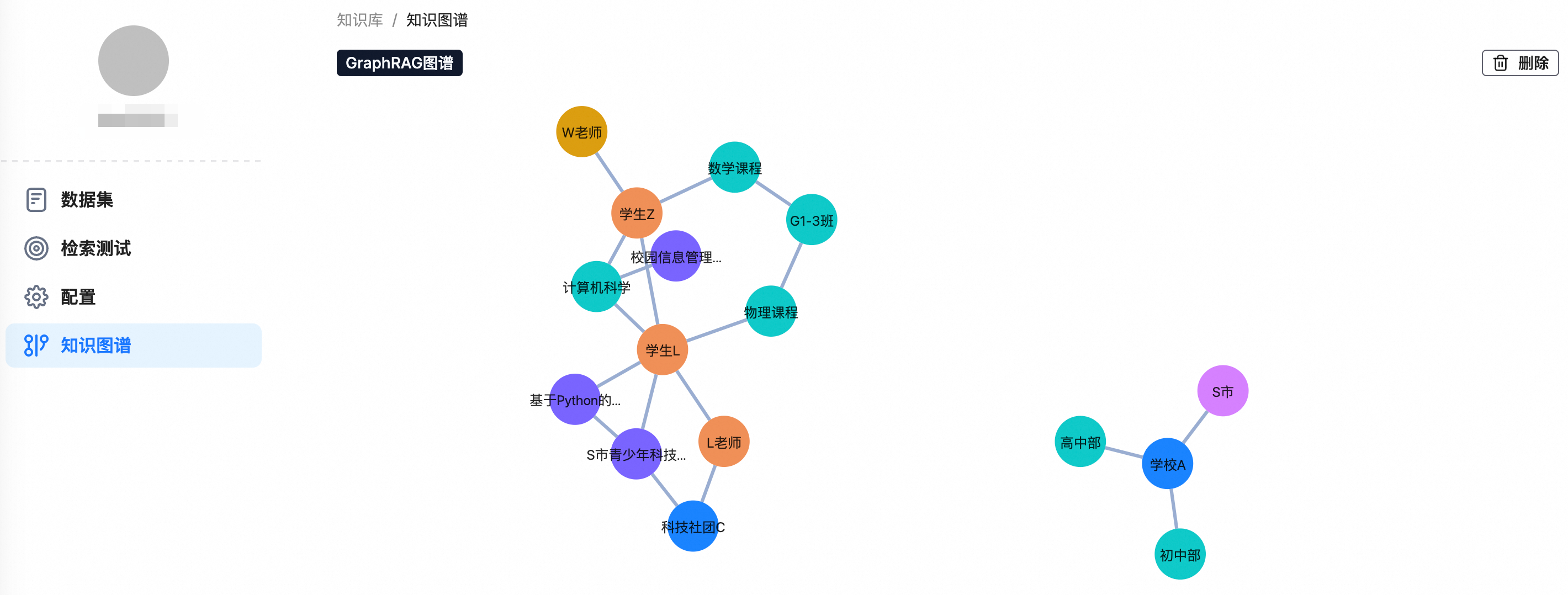
处理完成后,在知识库的左侧导航栏中会出现知识图谱组件,可用于可视化地浏览和验证已抽取的实体与关系。
步骤四:检索测试
通过对比测试,可以验证GraphRAG在处理不同类型查询时的效果。
进入知识库的检索测试页面。
场景一:常规查询
对于事实性的简单查询(例如“什么是RAG”),无论是否使用GraphRAG,系统主要依赖向量检索返回最相关的文本Chunk。
场景二:复杂查询
对于需要理解实体间关系的复杂查询(例如“对比RAG和GraphRAG的优缺点”),勾选使用GraphRAG。
此时,检索结果不仅会包含相关的文本Chunk,还会额外返回一个结构化的关联子图。该子图以Markdown表格形式呈现,清晰地列出查询涉及的核心实体及其关系,为LLM提供结构化的上下文,从而生成更具逻辑和深度的回答。
返回的关联子图格式如下:
---- Entities ---- ,Entity,Description 0,entity1,description1 1,entity2,description2 ---- Relations ---- ,From Entity,To Entity,Description 0,source_entity1,target_entity1,description1 1,source_entity2,target_entity2,description2示例:
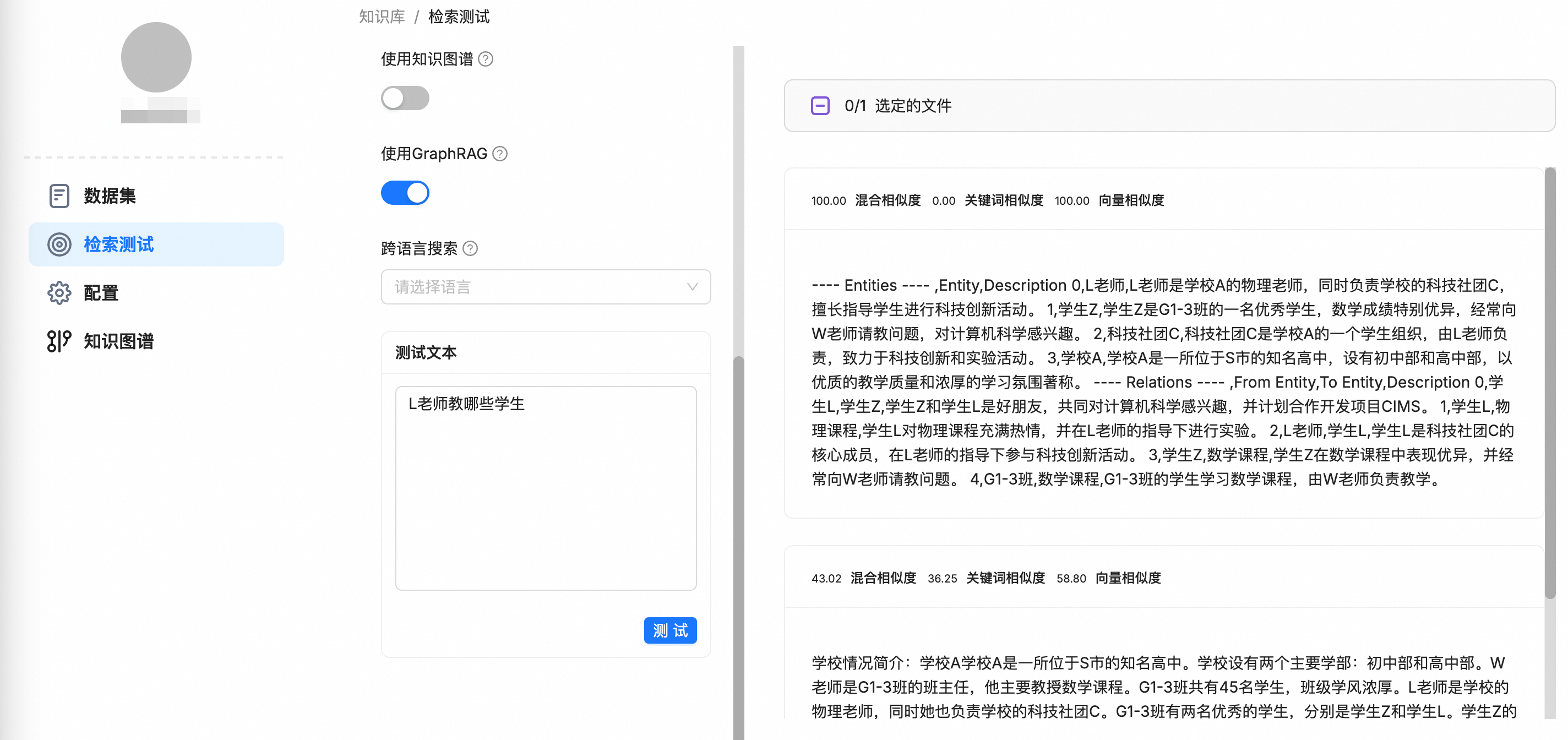
若不勾选使用GraphRAG,则检索结果仅包含文本Chunk,LLM可能因缺乏结构化关系信息而无法准确回答。