本文介绍了如何将AWS Glue Data Catalog中的元数据,包括但不限于库、表和分区等信息,无缝迁移到阿里云Data Lake Formation(DLF)。通过实施本次迁移,您能够充分利用DLF统一的元数据管理、权限与安全管理以及湖管理能力,快速在阿里云上构建并运维安全、统一的云原生数据湖环境。
背景信息
该迁移支持增量式的更新,确保可以反复执行而不会导致数据重复。每次作业运行时,系统会自动比较源端(AWS Glue)和目标端(DLF)的元数据。仅当源端的元数据在目标端缺失或存在差异时,系统才会触发新增或更新操作。如果目标端的元数据在源端不存在,系统将自动进行清理。这一机制确保了元数据的一致性。该迁移方案已被多个企业成功应用。迁移流程图如下所示。

迁移流程说明如下:
提取AWS Glue的元数据:使用Spark连接AWS Glue API,读取其元数据信息,包括库、表、分区和函数等。
转换和处理数据:根据迁移逻辑(包括增量更新或全量同步)对提取的元数据进行可能的转换和处理操作,以适配目标端阿里云DLF的格式或结构。
加载数据至DLF:使用DLF API,将处理后的元数据上传到阿里云DLF中。
注意事项
根据以往客户经验,对于包含约500万个分区的元数据规模的数据集,首次运行该Spark作业进行迁移时,处理时间可能需要大约2~3小时。在后续的常规运行中,预期在20分钟以内即可完成。
迁移流程
步骤一:下载工具包
方式一:单击glue-1.0-SNAPSHOT-jar-with-dependencies.jar,下载工具包。
方式二:在命令行终端执行以下命令,下载工具包。
wget http://dlf-lib.oss-cn-hangzhou.aliyuncs.com/jars/glue-1.0-SNAPSHOT-jar-with-dependencies.jar
步骤二:准备配置文件
在您的本地计算机上,创建或编辑一个名为
application.properties的配置文件。该文件包含了AWS和阿里云EMR所需的访问凭证,以及其他必要的相关配置信息。
配置文件准备好之后,需要将其上传至指定的位置。例如,上传至本地HDFS,阿里云OSS或Amazon S3上。
本文示例是上传至阿里云OSS。例如,oss://<bucket>/path/application.properties。
## AWS的AccessKey ID和AccessKey Secret。如果任务运行在AWS EMR集群上可以不填写这些凭据,否则必填。
aws.accessKeyId=xxxxx
aws.secretAccessKey=xxxxxx
## AWS地域。
aws.region=eu-central-1
## (必填)AWS Glue数据目录的ID,默认是AWS账号ID。
aws.catalogId=xxxx
## (可选)库过滤条件:迁移的数据库名称。如果未设置该参数,则默认会迁移所有数据库。
aws.databases=db1,db2
## (可选)表过滤条件:迁移表名前缀与指定值相匹配的表。可以通过逗号分隔的方式来指定多个表前缀,且各前缀之间不能有空格。
aws.table.filter.prefix=ods_,adm_
## (可选)分区过滤条件:迁移特定分区的数据。支持设置多条规则。如果未设置该参数,则默认会全量迁移该表的所有分区数据。
aws.partition.filter.<库名>.<表名>=dt>=20220101
## (必填)固定值。
mode=increment
comparePartition=true
## (必填)阿里云账号的AccessKey ID和AccessKey Secret,需要有DLF权限。
aliyun.accessKeyId=xxxx
aliyun.secretAccessKey=xxxxxxx
aliyun.region=eu-central-1
aliyun.endpoint=dlf.eu-central-1.aliyuncs.com
aliyun.catalogId=xxxx(默认DLF的Catalog为UID。)
## (必填)表location前缀替换规则,可以设置多个键值对,用于将源位置替换为目标位置。
location.convertMap={"s3://xxx-eu-central-1/glue-migrate/":"oss://xxx-eu-central-1/glue-migrate/"}
## (可选)输出结果的存储路径,记录本次迁移任务的详细操作日志。
result.output.path=oss://<bucket>/path1/步骤三:提交Spark作业
需要在已经配置好Spark环境的系统上提交Spark作业。您可以选择在AWS或阿里云EMR的Spark环境中执行,但必须确保运行环境能够访问公网。建议在Spark2版本的环境中提交Spark作业。
本文示例是在阿里云EMR集群的Master中提交Spark作业。创建和登录EMR集群的具体操作,请参见创建集群和登录集群。提交Spark作业示例如下所示。
spark-submit --name migrate --class com.aliyun.dlf.migrator.glue.GlueToDLFApplication --deploy-mode cluster --conf spark.executor.instances=10 glue-1.0-SNAPSHOT-jar-with-dependencies.jar oss://<bucket>/path/application.properties 其中,涉及参数如下:
name:指定作业的名称,您可以自定义。class:固定填com.aliyun.dlf.migrator.glue.GlueToDLFApplication。deploy-mode:cluster或者client均可。spark.executor.instances:按需设置,增加instance数量会提高任务运行速度。glue-1.0-SNAPSHOT-jar-with-dependencies.jar:为步骤一种下载的工具包。oss://<bucket>/path/application.properties:为步骤二中上传的配置文件的地址,请您根据实际情况替换。
步骤四:查看结果
在YARN UI中查看作业的driver的stdout日志。访问Web UI详情,请参见访问链接与端口。

日志包含以下内容。
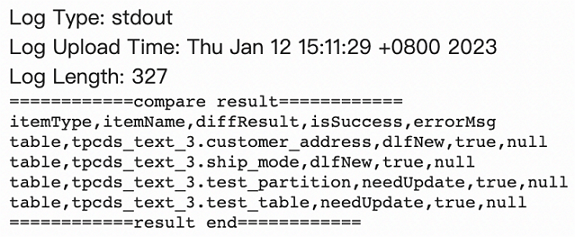
itemType: 指标项的类型,包括database、table、function、partition四种。itemName: 对应的库名、表名或分区名。diffResult: 差异类型。包括:dlfNew:表示在阿里云DLF中存在而在AWS Glue中不存在的元数据。该差异类型需要在DLF中执行删除(delete)操作。glueNew:表示在AWS Glue中存在而在阿里云DLF中不存在的元数据。该差异类型需要在DLF中执行创建(create)操作。needUpdate:表示在AWS Glue和阿里云DLF中都存在该元数据,但是内容有差异,因此需要更新(update)操作来同步两边的元数据。
isSuccess: 表示补偿操作是否成功执行。errorMsg: 如果操作未能成功执行,这里将提供错误信息的详情。