如果您在容器服务ACK控制台的组件管理页面CoreDNS组件上无法看到升级按钮,且当前组件版本较低,说明您的集群无法进行CoreDNS的自动升级。针对无法自动升级CoreDNS的情况,您可以手动升级CoreDNS。本文介绍CoreDNS手动升级的操作步骤。
前提条件
已通过kubectl工具连接集群。具体操作,请参见获取集群KubeConfig并通过kubectl工具连接集群。
升级前须知
如果您使用了IPVS作为kube-proxy负载均衡模式,在CoreDNS升级完成后,您可能会遇到五分钟内全集群范围内的解析超时或失败的情况,通过以下任意方式可以降低IPVS缺陷的影响:
修改kube-proxy中IPVS UDP会话保持的超时时间。具体操作,请参见下方的配置IPVS类型集群的UDP超时时间。
使用节点DNS缓存NodeLocal DNSCache。具体操作,请参见使用NodeLocal DNSCache。
升级过程约2分钟,实际耗时可能和集群中CoreDNS副本数相关。旧的副本不会被停止,不影响业务解析。
查看当前CoreDNS版本
使用控制台
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在无状态页面顶部设置命名空间为kube-system,然后查看CoreDNS的版本。

使用kubectl
您可执行以下命令查看当前CoreDNS版本:
kubectl get deployment coredns -n kube-system -o jsonpath="{.spec.template.spec.containers[0].image}"预期输出:
registry-vpc.cn-hangzhou.aliyuncs.com/acs/coredns:1.6.2 # 1.6.2为示例中的版本确认升级目标版本
在升级前,请您确认目标CoreDNS版本。CoreDNS与集群版本的兼容性如下,建议您使用兼容集群的最新CoreDNS版本。
Kubernetes版本 | CoreDNS版本 |
1.11至1.16 | v1.6.2(停止维护) |
1.14.8至1.22 | v1.6.7(停止维护)、v1.7.0 |
1.20.4及之后的版本 | v1.8.4、v1.9.3 重要 v1.8.4及v1.9.3有多个子版本,例如 |
1.21及之后的版本 | v1.11.3 |
手动升级
使用控制台
(可选)使用
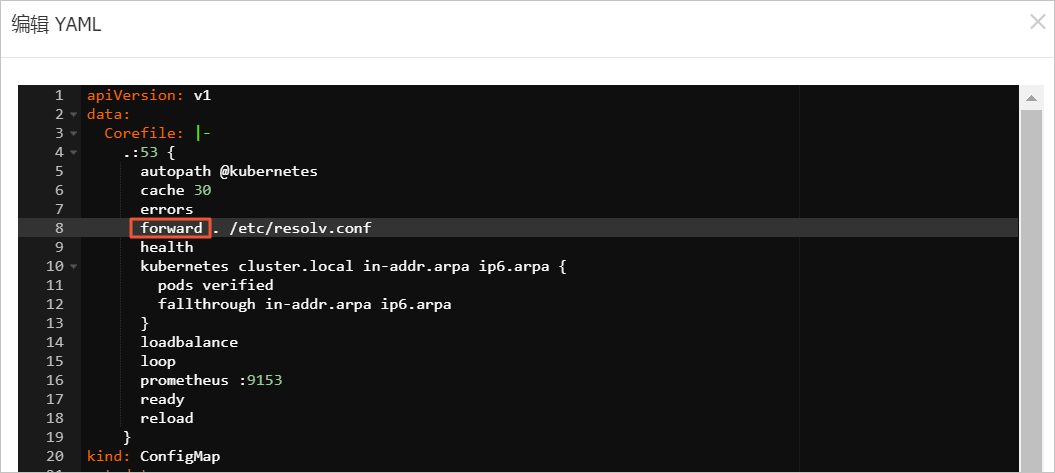
forward字段替换proxy字段。CoreDNS v1.6.2版本中废弃了Proxy插件。从v1.6.2之前的版本升级到v1.6.2及之后的版本时,您需要参照下方步骤,手动更改CoreDNS配置。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在配置项页面顶部设置命名空间为kube-system,然后单击coredns右侧操作列下的YAML 编辑。
在查看YAML面板,将proxy修改为forward,然后单击确定。
更新CoreDNS镜像版本。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在无状态页面顶部设置命名空间为kube-system,找到coredns,然后在其右侧操作列选择
 > YAML 编辑。
> YAML 编辑。在编辑 YAML页面,更新
image字段中的版本。然后单击更新。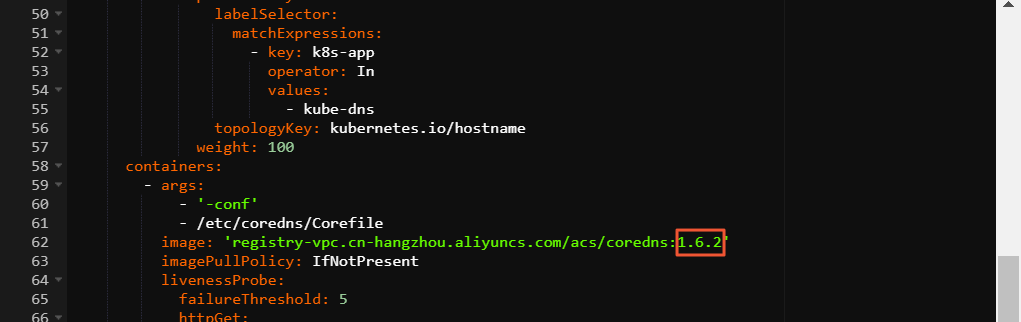
确认升级成功
执行以下命令,查看当前CoreDNS版本。
kubectl get deployment coredns -n kube-system -o jsonpath="{.spec.template.spec.containers[0].image}"预期输出:
registry-cn-shanghai-vpc.ack.aliyuncs.com/acs/coredns:v1.9.3.10-5e7ba42d-aliyun执行以下命令查看集群内所有CoreDNS Pod是否都处于Running状态。
kubectl get pods -n kube-system | grep coredns预期输出:
coredns-78d4b8****-6g62w 1/1 Running 0 9d coredns-78d4b8****-n6wjm 1/1 Running 0 9d
使用kubectl
(可选)使用
forward字段替换proxy字段。CoreDNS v1.6.2版本中废弃了Proxy插件。从v1.6.2之前的版本升级到v1.6.2及之后的版本时,您需要参照下方步骤,手动更改CoreDNS配置。
执行以下命令,编辑CoreDNS配置,更新
image字段中的版本,然后保存退出。kubectl edit deployment/coredns -n kube-system确认升级成功
执行以下命令,查看当前CoreDNS版本。
kubectl get deployment coredns -n kube-system -o jsonpath="{.spec.template.spec.containers[0].image}"预期输出:
registry-cn-shanghai-vpc.ack.aliyuncs.com/acs/coredns:v1.9.3.10-5e7ba42d-aliyun执行以下命令查看集群内所有CoreDNS Pod是否都处于Running状态。
kubectl get pods -n kube-system | grep coredns预期输出:
coredns-78d4b8****-6g62w 1/1 Running 0 9d coredns-78d4b8****-n6wjm 1/1 Running 0 9d
配置IPVS类型集群的UDP超时时间
如果集群使用了kube-proxy IPVS模式,IPVS的会话保持策略会导致整个集群在升级完成后五分钟内出现概率性解析失败的问题。请按以下方式降低IPVS UDP类型的会话保持超时时间至10秒,以减少解析失败的次数。如果集群中包含UDP类型的业务,请在操作前评估该操作是否有影响。
如果集群不是IPVS类型,请忽略配置IPVS类型集群的UDP超时时间的操作。关于如何查看kube-proxy代理模式,请参见查看集群信息。
K8s 1.18及以上版本集群
控制台操作方式
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在配置项页面选择kube-system命名空间,然后单击配置项kube-proxy-worker操作列的YAML 编辑。
在查看YAML面板中的ipvs字段下,添加
udpTimeout: 10s,然后单击确定。apiVersion: v1 data: config.conf: | apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration # 其它不相关字段已省略。 mode: ipvs # 如果ipvs键不存在,需要添加此键。 ipvs: udpTimeout: 10s重建所有名为kube-proxy-worker的容器。
在集群信息页左侧导航栏中,选择。
在守护进程集列表中,找到并单击kube-proxy-worker。
在kube-proxy-worker页面中的容器组页签下对应容器组右侧,选择,然后单击确定。
重复操作删除所有容器组。删除容器组后,系统会自动重建所有容器。
验证UDP超时时间的配置是否成功。
执行以下命令安装ipvsadm。
ipvsadm是IPVS模块的管理工具。更多信息,请参见ipvsadm。
sudo yum install -y ipvsadm在集群任意一台ECS节点中执行以下命令查看第三个数字。
sudo ipvsadm -L --timeout如果输出结果中第三个数字是10,则说明IPVS类型集群的UDP超时时间变更成功。
变更成功后,请观察至少五分钟后再进行下一步操作。
命令行操作方式
执行以下命令修改kube-proxy的配置文件kube-proxy-worker。
kubectl -n kube-system edit configmap kube-proxy-worker在kube-proxy配置文件中的ipvs字段下,添加
udpTimeout: 10s并保存退出。apiVersion: v1 data: config.conf: | apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration # 其它不相关字段已省略。 mode: ipvs # 如果ipvs键不存在,需要添加此键。 ipvs: udpTimeout: 10s执行以下命令重建所有名为kube-proxy-worker的容器。
执行以下命令查看存在的容器组信息。
kubectl -n kube-system get pod -o wide | grep kube-proxy-worker执行以下命令删除上步骤中查看所有容器,系统将会自动重建名为kube-proxy-worker容器。
kubectl -n kube-system delete pod <kube-proxy-worker-****>将<kube-proxy-worker-****>替换为上述所有容器组名称。
验证UDP超时时间的配置是否成功。
执行以下命令安装ipvsadm。
ipvsadm是IPVS模块的管理工具。更多信息,请参见ipvsadm。
sudo yum install -y ipvsadm在集群任意一台ECS节点中执行以下命令查看第三个数字。
sudo ipvsadm -L --timeout如果输出结果中第三个数字是10,则说明IPVS类型集群的UDP超时时间变更成功。
变更成功后,请观察至少五分钟后再进行下一步操作。
K8s 1.16及以下版本集群
此类版本集群的kube-proxy不支持udpTimeout参数,推荐使用OOS服务批量在所有集群机器上执行ipvsadm命令以调整UDP超时时间配置。命令如下:
sudo yum install -y ipvsadm
sudo ipvsadm -L --timeout > /tmp/ipvsadm_timeout_old
sudo ipvsadm --set 900 120 10
sudo ipvsadm -L --timeout > /tmp/ipvsadm_timeout_new
diff /tmp/ipvsadm_timeout_old /tmp/ipvsadm_timeout_new关于OOS的批量操作实例介绍,请参见批量操作实例。
后续步骤
升级完成后,您可以对CoreDNS进行优化,合理配置CoreDNS。具体操作,请参见优化CoreDNS配置。