AnalyticDB for MySQL 推出基于千问 Qwen-VL 大模型的 PDF 智能解析函数。这项创新功能允许用户通过标准 SQL,直接从 PDF 文件中提取结构化和非结构化数据,并将其高效转换为可查询、可分析的数据库表,彻底打破非结构化数据的壁垒。本指南将提供详尽的操作指引,内容涵盖环境准备、函数语法、实用示例及批量处理等高级用法,旨在帮助您快速掌握并应用这一强大功能,释放 PDF 文档中的数据价值。
本功能目前处于公开测试阶段,如需试用,请提交工单或联系您的阿里云客户经理。
产品概述
企业内部超过 80% 的数据以非结构化形式存在,而 PDF 是承载这些数据的主要格式,广泛应用于合同、发票、技术文档、研究报告等业务场景。传统数据库对 PDF 文件缺乏有效的解析能力,导致这些文件在系统中仅以文件名形式存储,其内部数据无法被检索、统计或分析,形成了巨大的“数据孤岛”。为解决这一痛点,AnalyticDB for MySQL 通过 AI 智能解析函数,突破了 PDF 数据提取的技术壁垒,使企业能够高效挖掘非结构化数据价值。
核心能力
一键提取:自动识别并提取 PDF 中的键值对、表格、元数据等多种数据类型。
结构化存储:将非结构化的 PDF 内容转换为结构化的数据库表,支持标准 SQL 查询与分析。
批量处理:支持多页文档的批量解析和入库,适用于大规模文档处理场景。
高精度识别:基于 Qwen-VL 视觉大模型,在复杂排版、无边框表格等挑战性场景下仍能保持高准确率。
典型应用场景
行业领域 | 场景 | 应用说明 |
金融与合规 | 信贷审批 | 自动解析贷款申请人提交的工资流水、税单 PDF,利用 SQL 直接提取关键指标(如月收入、纳税额)并进行信用评分计算。 |
财报分析 | 投资银行通过 SQL 函数批量解析数千份上市公司的 PDF 年报,提取利润表、资产负债表,直接进行跨年度、跨行业的横向对比。 | |
供应链与物流 | 采购对账 | 通过 SQL 触发解析 PDF 格式的供应商发票(Invoice),自动对比数据库中的采购订单(PO)和入库单,实现“三单合一”的自动核销。 |
物流运单跟踪 | 批量提取海运、空运提单中的集装箱号、重量和到港时间,实时更新 ERP 系统的物流状态。 |
PDF 文档提取的核心挑战
PDF 的设计初衷是为了“显示”而非“数据交换”,这导致了数据提取时面临多个核心挑战:
挑战类型 | 问题描述 | 影响 |
视觉与逻辑的脱节 | 在 PDF 底部看到的一个数字,其底层代码可能出现在文档的开头。 | 传统 OCR 只能识别字符,却无法理解其空间位置代表的业务含义。 |
表格的隐形结构 | 许多 PDF 表格没有边框线,人类通过视觉上的对齐和空白间隔来识别行列关系。 | 传统程序往往会将跨行文字拆散,导致数据关系错乱。 |
多模态语义缺失 | 关键信息可能隐藏在非文字元素中,如红色印章代表“已作废”,勾选框代表“同意”。 | 单纯的文字提取会丢失这些至关重要的上下文信息。 |
这些被“封印”在 PDF 中的信息,形成了一座座数据孤岛,阻碍了核心业务数据向数据仓库(Data Warehouse)或湖仓(Lakehouse)的自由流通,从而限制了其潜在价值的深度挖掘。
基于 Qwen-VL 的解决方案
AnalyticDB for MySQL 基于 Qwen-VL 系列模型强大的视觉信息理解能力,通过 AI 函数打通了文档智能处理流程中的两大核心壁垒:
从视觉文本布局到可解析、可读取的文本信息的转化。
从非规范化的数据结构到二维表、键值对等易于被数据系统持久化和高效交换的数据结构的转化。
Qwen-VL 模型技术优势
优势项 | 说明 |
原生多模态架构 | 传统方案常采用“OCR+LLM”的缝合模式,在“图像转文本”的过程中会丢失大量空间坐标、字体大小等关键视觉信息。Qwen-VL 采用原生多模态架构,直接将图像像素编码为模型能够理解的序列,信息保真度更高。 |
高分辨率支持 | 视觉模型处理文本最大的痛点之一是看不清小字。Qwen-VL 支持高分辨率输入,并引入了更精细的图像切片技术,确保细节信息不丢失。 |
精确的位置感知 | Qwen-VL 在预训练阶段加入了大量的位置坐标关联训练,使其不仅知道图像中“有什么”,还精确知道“在哪里”。这种空间感知能力使其在处理非结构化文档时表现卓越。 |
函数参考
函数语法:
SELECT ai_pdf_extract( <model_name>, <file_url>, '{"page_index": <page_index> ,"timeout": <timeout>}' );参数说明:
参数名
类型
必填
说明
model_nameSTRING
否
指定使用的模型名称。若留空,则默认使用内置的
qwen-vl-plus模型。file_urlSTRING
是
待解析 PDF 文件的完整 OSS 路径。示例:
oss://<bucket>/path/sample.pdf。page_indexINTEGER
是
指定待解析的页面索引,从 1 开始计数。
timeoutINTEGER
否
函数执行的超时时间,单位为秒。默认值为 300 秒。若解析超过此时长,任务将中断并返回超时错误。
返回结果:
函数返回一个包含 JSON 数据的字符串,其中包含以下三类信息。
type值说明
示例字段
"type": "metadata"元数据:文件元数据,如文件名、大小、页数等。
filename,size,page_count,url"type": "form"键值对:从文档中提取的键值对(Key-Value)信息。
company_name,invoice_number,amount_due"type": "table"表格:从文档中提取的表格数据。
以 JSON 数组形式返回的列名和行数据。
快速入门
环境准备
在开始使用 PDF 解析函数之前,请确保完成以下准备工作:
创建一个 AnalyticDB for MySQL 实例。
为AnalyticDB for MySQL实例所在的 VPC 配置 NAT 网关,确保其具备公网访问能力。详情请参见Spark应用访问公网配置说明。
将待解析的 PDF 文件上传至与AnalyticDB for MySQL实例位于同一地域的 OSS Bucket 中,并获取其完整的
oss://路径。
示例数据
以下是一个典型的 PDF 发票样例文件,包含键值对和表格两种核心数据结构。
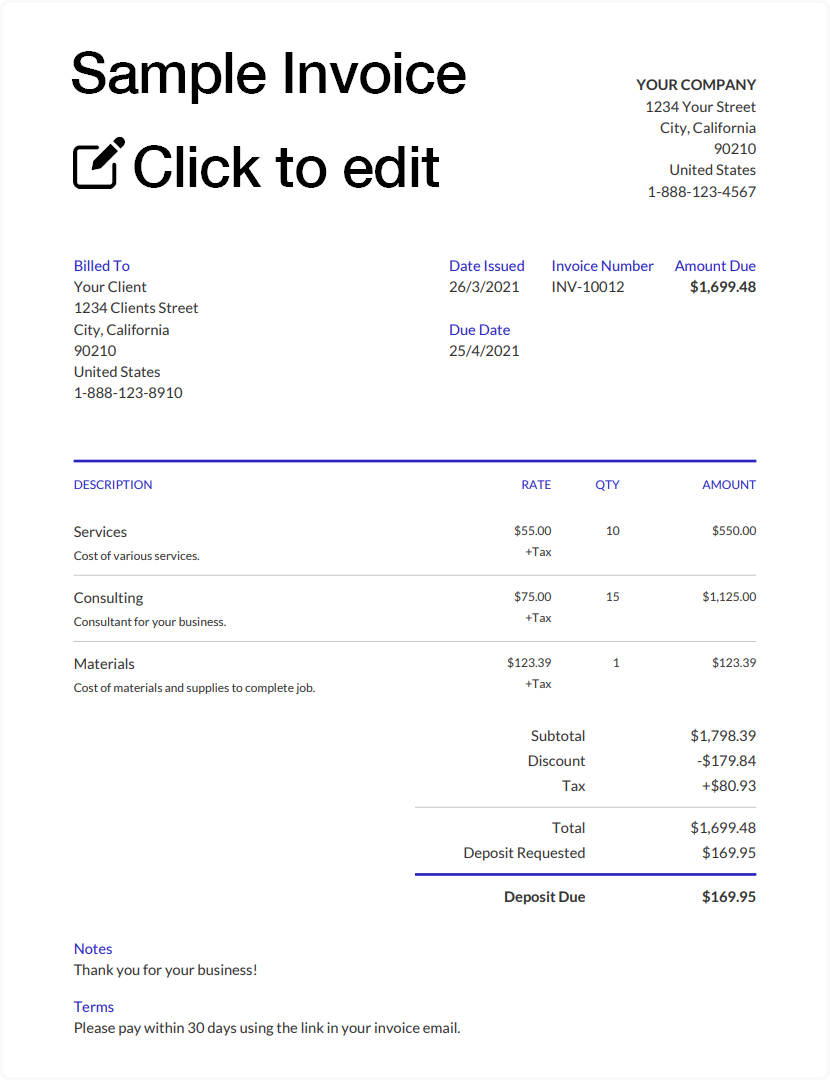
分类提取数据
通过 JSON_EXTRACT 函数,可以从返回结果中分别提取元数据、键值对和表格数据。
SELECT
JSON_EXTRACT(result, '$.data[0].content') AS metadata,
JSON_EXTRACT(result, '$.data[1].content') AS form_data,
JSON_EXTRACT(result, '$.data[2].content[0]') AS table_data
FROM (
SELECT ai_pdf_extract(
"qwen3_vl_plus",
"oss://<bucket>/path/sample.pdf",
'{"page_index": 1,"timeout": 300}'
)
AS result
) pdf_data;返回结果示例
函数返回一个结构化的 JSON 字符串,便于后续处理。
{
"data": [
{
"content": {
"filename": "sample.pdf",
"size": 68760,
"creation_date": "2026-02-28 02:26:08",
"modification_date": "2026-02-28 02:26:08",
"page_count": 1,
"url": "oss://oss-***-cn-beijing/pdf/sample.pdf",
"page_index": 1
},
"name": "metadata",
"type": "metadata"
},
{
"content": {
"company_name": "YOUR COMPANY",
"company_address": "1234 Your Street\nCity, California\n90210\nUnited States",
"company_phone": "1-888-123-4567",
"billed_to": "Your Client\n1234 Clients Street\nCity, California\n90210\nUnited States\n1-888-123-8910",
"date_issued": "26/3/2021",
"invoice_number": "INV-10012",
"amount_due": "$1,699.48",
"due_date": "25/4/2021",
"subtotal": "$1,798.39",
"discount": "-$179.84",
"tax": "+$80.93",
"total": "$1,699.48",
"deposit_requested": "$169.95",
"deposit_due": "$169.95",
"notes": "Thank you for your business!",
"terms": "Please pay within 30 days using the link in your invoice email."
},
"name": "form",
"type": "form"
},
{
"content": [
[
{
"DESCRIPTION": "Services",
"RATE": "$55.00",
"QTY": "10",
"AMOUNT": "$550.00"
},
{
"DESCRIPTION": "Consulting",
"RATE": "$75.00",
"QTY": "15",
"AMOUNT": "$1,125.00"
},
{
"DESCRIPTION": "Materials",
"RATE": "$123.39",
"QTY": "1",
"AMOUNT": "$123.39"
}
]
],
"name": "table",
"type": "table"
}
]
}数据解析与入库
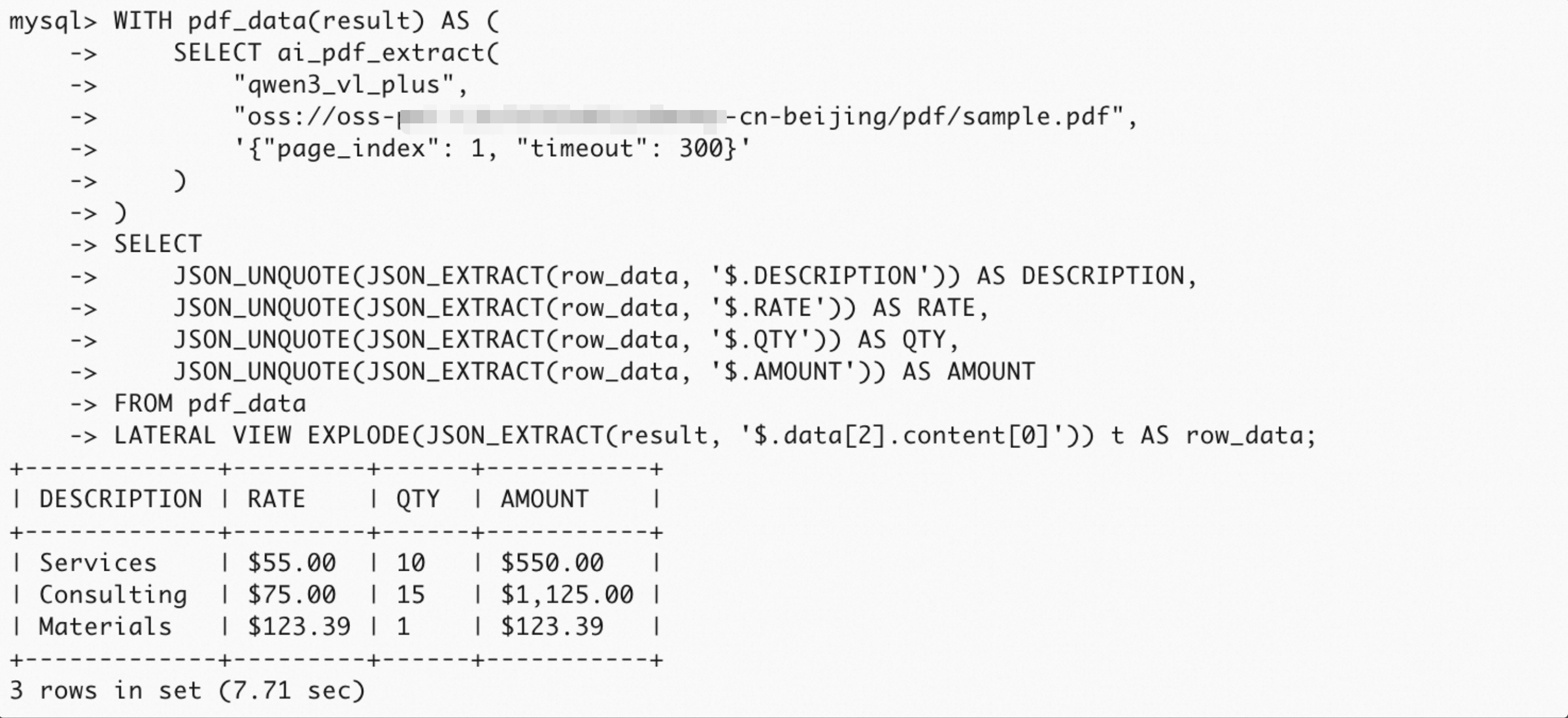
解析表格内容
使用 LATERAL VIEW EXPLODE 将表格的 JSON 数组展开为多行,再用 JSON_EXTRACT 和 JSON_UNQUOTE 提取每列的值。
子查询写法
SELECT JSON_UNQUOTE(JSON_EXTRACT(row_data, '$.DESCRIPTION')) AS DESCRIPTION, JSON_UNQUOTE(JSON_EXTRACT(row_data, '$.RATE')) AS RATE, JSON_UNQUOTE(JSON_EXTRACT(row_data, '$.QTY')) AS QTY, JSON_UNQUOTE(JSON_EXTRACT(row_data, '$.AMOUNT')) AS AMOUNT FROM ( SELECT ai_pdf_extract( "qwen3_vl_plus", "oss://oss-***-cn-beijing/pdf/sample.pdf", '{"page_index": 1, "timeout": 300}' ) AS result ) pdf_data LATERAL VIEW EXPLODE(JSON_EXTRACT(result, '$.data[2].content[0]')) t AS row_data;CTE写法
WITH pdf_data(result) AS ( SELECT ai_pdf_extract( "qwen3_vl_plus", "oss://oss-***-cn-beijing/pdf/sample.pdf", '{"page_index": 1, "timeout": 300}' ) ) SELECT JSON_UNQUOTE(JSON_EXTRACT(row_data, '$.DESCRIPTION')) AS DESCRIPTION, JSON_UNQUOTE(JSON_EXTRACT(row_data, '$.RATE')) AS RATE, JSON_UNQUOTE(JSON_EXTRACT(row_data, '$.QTY')) AS QTY, JSON_UNQUOTE(JSON_EXTRACT(row_data, '$.AMOUNT')) AS AMOUNT FROM pdf_data LATERAL VIEW EXPLODE(JSON_EXTRACT(result, '$.data[2].content[0]')) t AS row_data;
提取元数据信息
直接通过 JSON_EXTRACT 和 JSON_UNQUOTE 提取所需的键值对字段。
WITH pdf_data AS (
SELECT ai_pdf_extract(
"qwen3_vl_plus",
"oss://oss-***-cn-beijing/pdf/sample.pdf",
'{"page_index": 1, "timeout": 300}'
) AS result
)
SELECT
JSON_UNQUOTE(JSON_EXTRACT(result, '$.data[0].content.filename')) AS 'file_name',
JSON_UNQUOTE(JSON_EXTRACT(result, '$.data[0].content.size')) AS 'file_size',
JSON_UNQUOTE(JSON_EXTRACT(result, '$.data[0].content.creation_date')) AS 'create_date',
JSON_UNQUOTE(JSON_EXTRACT(result, '$.data[0].content.modification_date')) AS 'modify_date',
JSON_UNQUOTE(JSON_EXTRACT(result, '$.data[0].content.page_count')) AS 'page_count',
JSON_UNQUOTE(JSON_EXTRACT(result, '$.data[0].content.url')) AS 'OSS_path',
JSON_UNQUOTE(JSON_EXTRACT(result, '$.data[0].content.page_index')) AS 'current_page'
FROM pdf_data;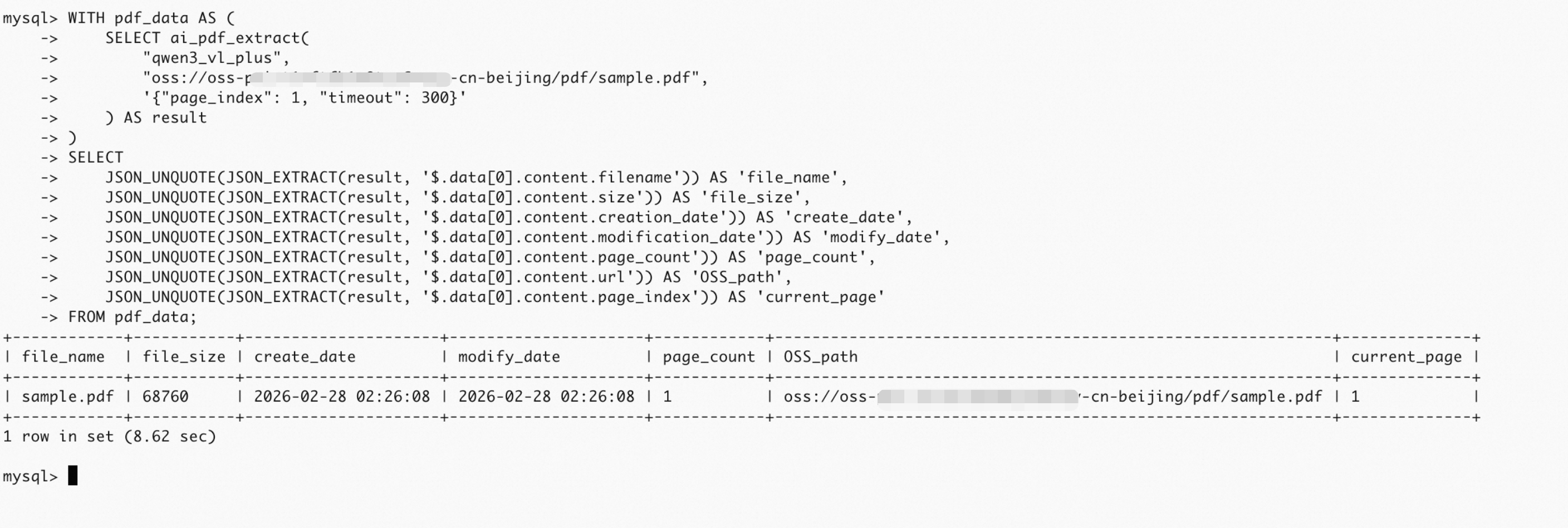
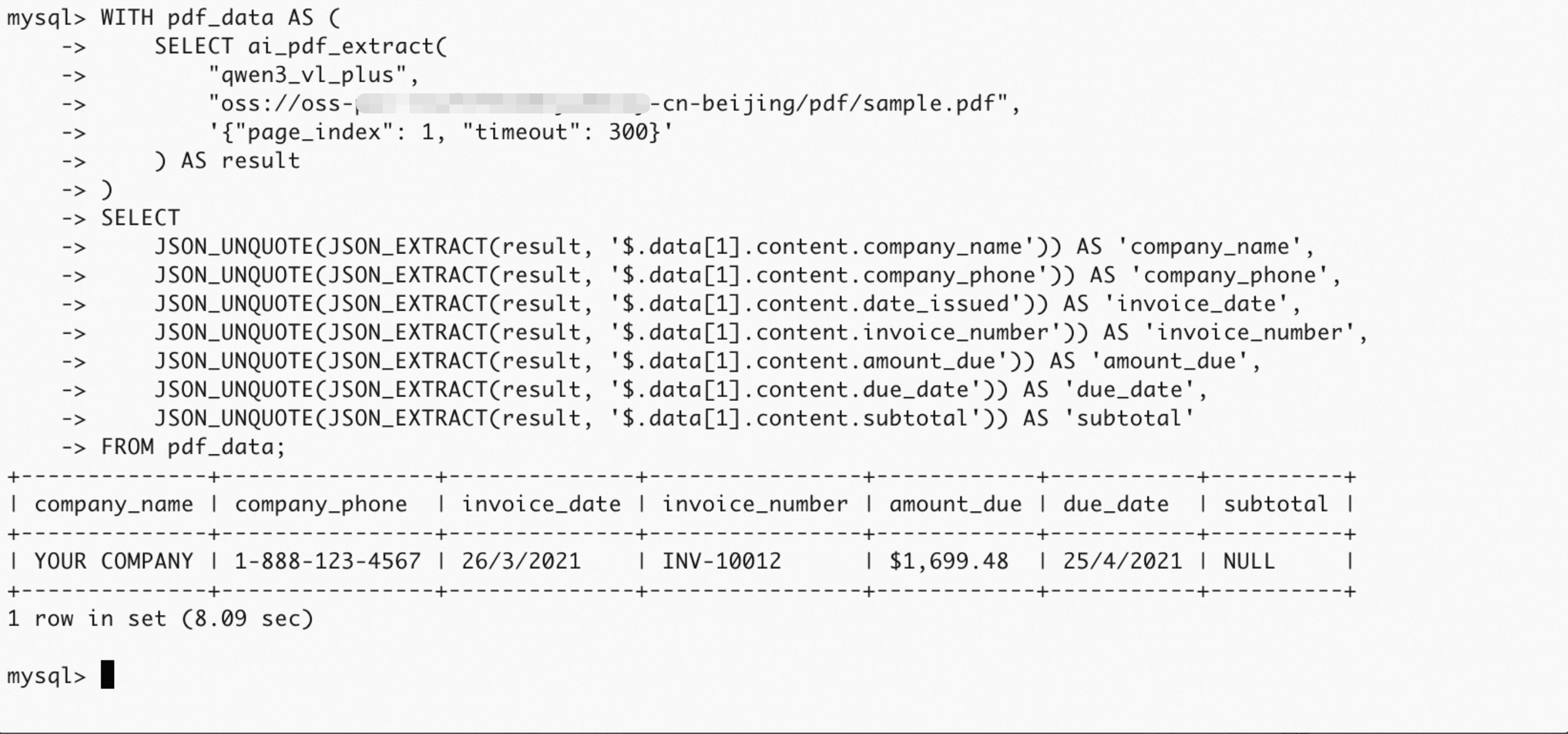
提取键值对信息
子查询写法
SELECT JSON_EXTRACT(result, '$.data[1].content') AS form_data FROM ( SELECT ai_pdf_extract( "qwen3_vl_plus", "oss://oss-***-cn-beijing/pdf/sample.pdf", '{"page_index": 1, "timeout": 300}' ) AS result ) pdf_data;CTE写法
WITH pdf_data AS ( SELECT ai_pdf_extract( "qwen3_vl_plus", "oss://oss-***-cn-beijing/pdf/sample.pdf", '{"page_index": 1, "timeout": 300}' ) AS result ) SELECT JSON_UNQUOTE(JSON_EXTRACT(result, '$.data[1].content.company_name')) AS 'company_name', JSON_UNQUOTE(JSON_EXTRACT(result, '$.data[1].content.company_phone')) AS 'company_phone', JSON_UNQUOTE(JSON_EXTRACT(result, '$.data[1].content.date_issued')) AS 'invoice_date', JSON_UNQUOTE(JSON_EXTRACT(result, '$.data[1].content.invoice_number')) AS 'invoice_number', JSON_UNQUOTE(JSON_EXTRACT(result, '$.data[1].content.amount_due')) AS 'amount_due', JSON_UNQUOTE(JSON_EXTRACT(result, '$.data[1].content.due_date')) AS 'due_date', JSON_UNQUOTE(JSON_EXTRACT(result, '$.data[1].content.subtotal')) AS 'subtotal' FROM pdf_data;
将表格数据写入新表
结合 CREATE TABLE AS SELECT 语句,可以完成 PDF 表格的解析和入库。
CREATE DATABASE IF NOT EXISTS DOC_DB;
CREATE TABLE IF NOT EXISTS DOC_DB.SAMPLE_PDF_TABLE
AS
SELECT
JSON_UNQUOTE(JSON_EXTRACT(row_data, '$.DESCRIPTION')) AS DESCRIPTION,
JSON_UNQUOTE(JSON_EXTRACT(row_data, '$.RATE')) AS RATE,
JSON_UNQUOTE(JSON_EXTRACT(row_data, '$.QTY')) AS QTY,
JSON_UNQUOTE(JSON_EXTRACT(row_data, '$.AMOUNT')) AS AMOUNT
FROM (
SELECT ai_pdf_extract(
"qwen3_vl_plus",
"oss://oss-***-cn-beijing/pdf/sample.pdf",
'{"page_index": 1, "timeout": 300}'
) AS result
) pdf_data
LATERAL VIEW EXPLODE(JSON_EXTRACT(result, '$.data[2].content[0]')) t AS row_data;
SELECT * FROM DOC_DB.SAMPLE_PDF_TABLE;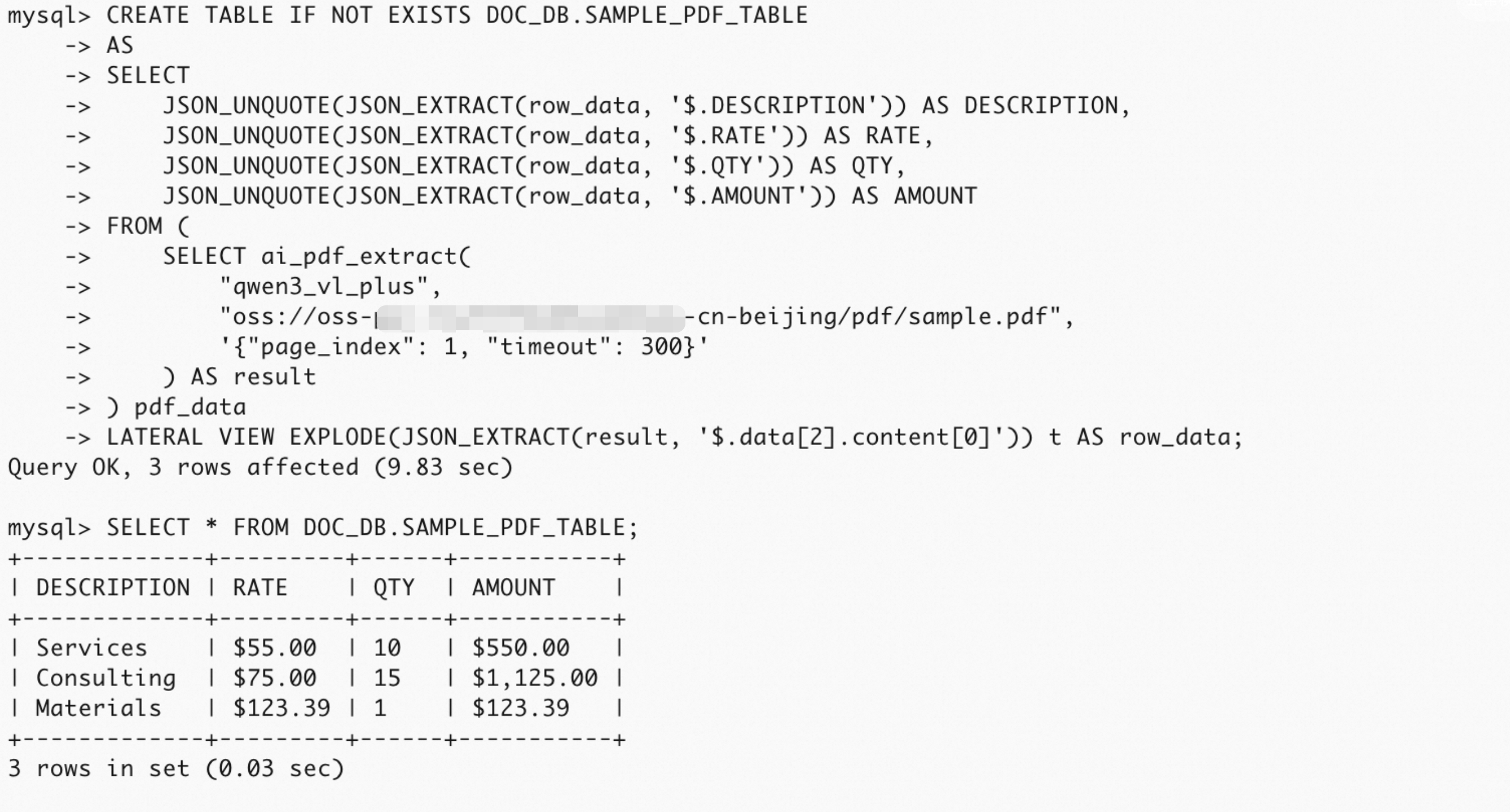
多页文档批量处理
默认情况下,单次调用 PDF 解析函数仅能处理 PDF 文件的一个页面。若需处理多页 PDF 并将全部内容入库,可借助 Python 脚本实现自动化流程:
获取总页数:首先通过函数返回的
metadata信息解析 PDF 的总页数;处理第一页:对第一页执行 PDF 解析,并使用
CREATE TABLE AS SELECT(CTAS)语句将结果写入目标表;遍历后续页面:从第二页开始,循环调用 PDF 解析函数,依次将每页的解析结果通过
INSERT INTO语句追加到同一张表中。
解析后的表内部同时包含了 metadata/键值对/表格。可以再次使用JSON函数做后续内容的解析。
Python 脚本示例
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import pymysql
import time
def extract_multi_page_pdf(host, username, password, file_path, database, table_name):
"""
多页PDF提取到ADB MySQL表
参数:
host: ADB MySQL主机地址
username: 用户名
password: 密码
file_path: PDF文件OSS路径(如:oss://bucket/path/file.pdf)
database: 数据库名
table_name: 目标表名
返回:
成功返回True,失败返回False
"""
conn = None
try:
# 连接数据库
print(f"连接数据库 {host}/{database}...")
conn = pymysql.connect(
host=host,
user=username,
password=password,
database=database,
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
cursor = conn.cursor()
print("✓ 连接成功")
# 步骤1:获取总页数
print(f"\n获取PDF总页数...")
sql_page_count = f"""
SELECT JSON_EXTRACT(result, '$.data[0].content.page_count') AS page_count
FROM (
SELECT ai_pdf_extract(
"qwen3_vl_plus",
"{file_path}",
'{{"page_index": 1, "timeout": 300}}'
) AS result
) t
"""
cursor.execute(sql_page_count)
page_count = int(cursor.fetchone()['page_count'])
print(f"✓ 总页数: {page_count}")
# 步骤2:删除旧表
print(f"\n删除旧表 {table_name}...")
cursor.execute(f"DROP TABLE IF EXISTS {table_name}")
print("✓ 完成")
# 步骤3:CTAS创建表(第1页)
print(f"\n创建表并导入第1页...")
sql_ctas = f"""
CREATE TABLE {table_name} AS
SELECT
JSON_EXTRACT(result, '$.data[0].content') AS metadata,
JSON_EXTRACT(result, '$.data[1].content') AS form_data,
row_data AS table_row_data,
'1' AS page_number
FROM (
SELECT ai_pdf_extract(
"qwen3_vl_plus",
"{file_path}",
'{{"page_index": 1, "timeout": 300}}'
) AS result
) t
LATERAL VIEW EXPLODE(JSON_EXTRACT(result, '$.data[2].content[0]')) tv AS row_data
"""
cursor.execute(sql_ctas)
print("✓ 第1页完成")
# 步骤4:INSERT追加第2-N页
if page_count > 1:
print(f"\n追加第2-{page_count}页...")
for page in range(2, page_count + 1):
start_time = time.time()
sql_insert = f"""
INSERT INTO {table_name}
SELECT
JSON_EXTRACT(result, '$.data[0].content') AS metadata,
JSON_EXTRACT(result, '$.data[1].content') AS form_data,
row_data AS table_row_data,
'{page}' AS page_number
FROM (
SELECT ai_pdf_extract(
"qwen3_vl_plus",
"{file_path}",
'{{"page_index": {page}, "timeout": 300}}'
) AS result
) t
LATERAL VIEW EXPLODE(JSON_EXTRACT(result, '$.data[2].content[0]')) tv AS row_data
"""
cursor.execute(sql_insert)
elapsed = time.time() - start_time
print(f" ✓ 第{page}页 ({elapsed:.1f}秒)")
# 步骤5:验证
cursor.execute(f"SELECT COUNT(*) as cnt FROM {table_name}")
total_rows = cursor.fetchone()['cnt']
print(f"\n验证结果:")
print(f" 表名: {table_name}")
print(f" 总行数: {total_rows}")
return True
except Exception as e:
print(f"\n❌ 错误:{e}")
import traceback
traceback.print_exc()
return False
finally:
if conn:
conn.close()
print("\n连接已关闭")
# 使用示例
if __name__ == "__main__":
extract_multi_page_pdf(
host='HOST',
username='USERNAME',
password='PASSWORD',
file_path='oss://<BUCKET>/pdf/sample.pdf',
database='DB_NAME',
table_name='TABLE_NAME'
)