大语言模型(LLM)在线服务因流量波动而普遍采用的多集群架构部署,ACK One提供的多集群解决方案可以适配这种场景。本文将演示如何基于ACK One舰队,在云上环境中部署vLLM推理服务,并利用多集群HPA(FederatedHPA)进行跨集群的弹性伸缩。
工作原理
在大规模推理场景中,大语言模型(LLM)在线服务面临流量波动剧烈且难以预测的挑战。多集群架构是应对流量高峰时普遍采用的方案:
-
自建数据中心用户:通常采用混合云架构,在业务高峰期通过云端集群进行弹性扩容。
-
云上用户:倾向于在不同地域部署多个集群,以此规避单地域资源供给不足的风险。
ACK One舰队支持同时管理多个集群的资源,并执行跨集群的调度、弹性伸缩等能力,适配以上两种部署模式的需求:
-
多集群优先级调度:支持配置集群的调度优先级,可以将副本优先调度到高优集群,在资源不足时扩容副本至低优集群,缩容时优先缩容低优集群的副本。
-
基于库存的智能调度:舰队集群会与子集群的GoatScaler联动结合ECS库存进行副本的智能调度。
-
统一中心弹性扩缩容:通过创建FederatedHPA进行多集群的统一中心弹性扩缩容,舰队集群的Metrics Adapter会采集子集群的指标并进行聚合(子集群也支持Prometheus-adapter),根据聚合指标对工作负载进行扩缩容。
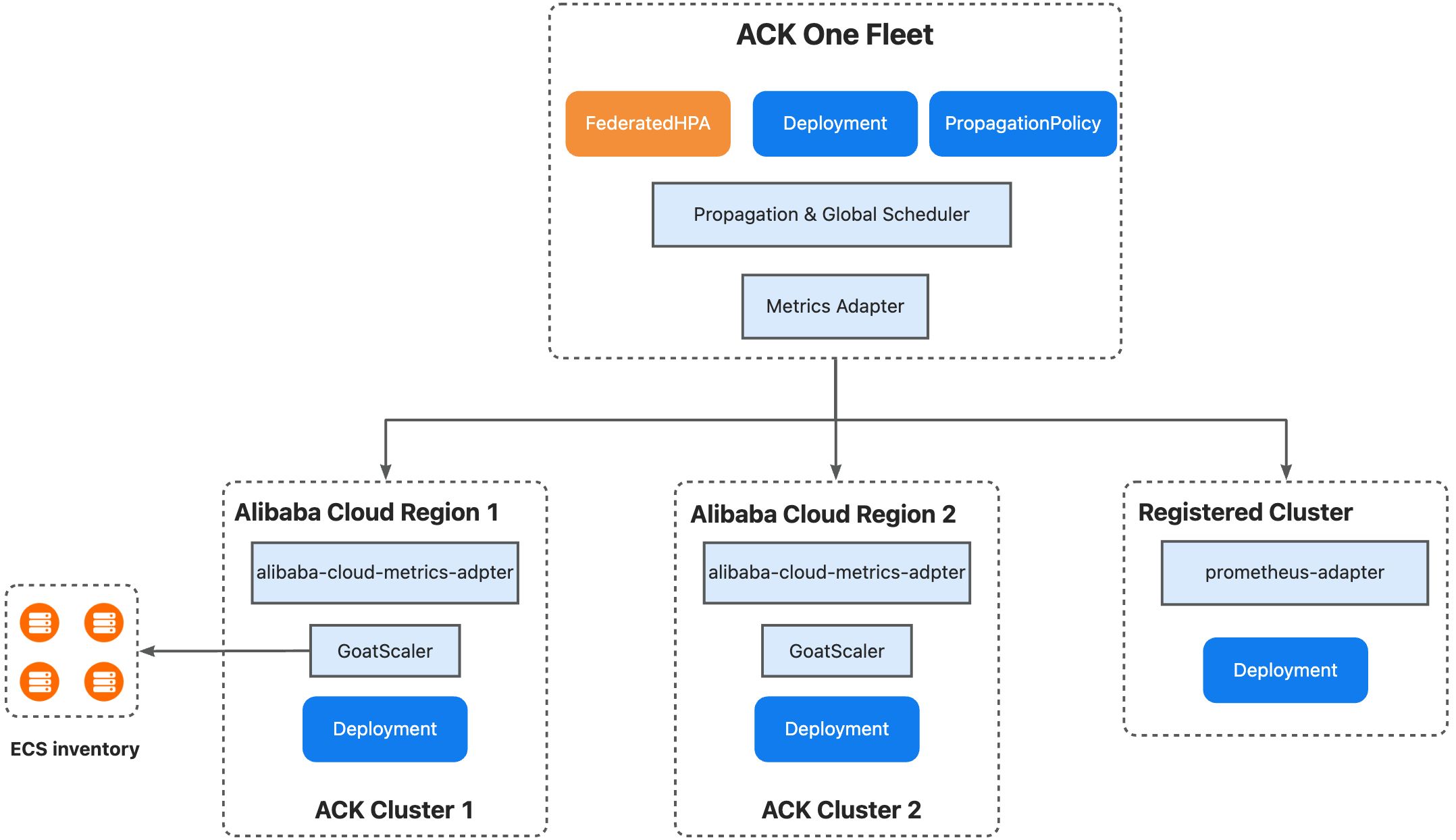
适用范围
-
已创建两个ACK集群,每个集群都有GPU节点池,且初始化一个GPU实例。
-
两个ACK集群已关联到ACK One舰队,且已接入alibaba-cloud-metrics-adapter组件,注册集群需要安装 开源版prometheus-adapter 。
多集群HPA功能处于邀测阶段,请联系我们提交申请开通白名单后使用。
操作步骤
步骤一:在子集群中配置指标采集
在两个ACK集群中配置ack-alibaba-cloud-metrics-adapter的组件参数。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
-
找到ack-alibaba-cloud-metrics-adapter组件,在操作列单击更新。在
prometheus.adapter.rules,可以修改指标采集配置,例如:-
vllm:num_requests_waiting:等待被处理的请求数。 -
vllm:num_requests_running:正在处理的请求数。
rules: - seriesQuery: 'vllm:num_requests_waiting' resources: overrides: kubernetes_namespace: {resource: "namespace"} kubernetes_pod_name: {resource: "pod"} name: matches: 'vllm:num_requests_waiting' as: 'num_requests_waiting' metricsQuery: 'sum(<<.Series>>{<<.LabelMatchers>>}) by (<<.GroupBy>>)' - seriesQuery: 'vllm:num_requests_running' resources: overrides: kubernetes_namespace: {resource: "namespace"} kubernetes_pod_name: {resource: "pod"} name: matches: 'vllm:num_requests_running' as: 'num_requests_running' metricsQuery: 'sum(<<.Series>>{<<.LabelMatchers>>}) by (<<.GroupBy>>)' -
-
修改完成后,单击
确定。 -
检查自定义指标是否配置成功。
# 查看自定义指标 kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/test/pods/qwen3-xxxxx/num_requests_waiting" kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/test/pods/qwen3-xxxxx/num_requests_running"预期输出vLLM指标,表示指标采集配置成功。
步骤二:在舰队中创建vLLM推理服务
将下方YAML示例模板保存到deployment.yaml,然后执行kubectl apply -f deployment.yaml在舰队中部署推理服务。
apiVersion: apps/v1
kind: Deployment
metadata:
name: qwen3
namespace: test
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: qwen3
template:
metadata:
annotations:
# 用来捕获pod的metrics,效果如同PodMonitor
prometheus.io/path: /metrics
prometheus.io/port: "8000"
prometheus.io/scrape: "true"
labels:
app: qwen3
spec:
containers:
# 使用qwen3-0.6b模型,模型从modelscope下载
- command:
- sh
- -c
- export VLLM_USE_MODELSCOPE=True; vllm serve Qwen/Qwen3-0.6B --served-model-name
qwen3-0.6b --port 8000 --trust-remote-code --tensor_parallel_size=1 --max-model-len
2048 --gpu-memory-utilization 0.8
image: kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm-openai:v0.9.1
imagePullPolicy: IfNotPresent
name: vllm
ports:
- containerPort: 8000
name: restful
protocol: TCP
readinessProbe:
failureThreshold: 3
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
tcpSocket:
port: 8000
timeoutSeconds: 1
resources:
limits:
nvidia.com/gpu: "1"
requests:
nvidia.com/gpu: "1"
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30步骤三:在舰队中配置多集群分发策略
将下方示例模板保存到propagationpolicy.yaml,然后执行kubectl apply -f propagationpolicy.yaml。
-
autoScaling.ecsProvision:开启基于库存的智能调度,会根据需要自动扩缩ECS实例。 -
clusterAffinities:优先级分组,在调度时按优先级依次填充affinity。
apiVersion: policy.one.alibabacloud.com/v1alpha1
kind: PropagationPolicy
metadata:
name: vllm-deploy-pp
namespace: test
spec:
autoScaling:
ecsProvision: true
placement:
clusterAffinities:
- affinityName: high-priority
clusterNames:
- ${cluster1_id}
- affinityName: low-priority
clusterNames:
- ${cluster2_id}
replicaScheduling:
replicaSchedulingType: Divided
replicaDivisionPreference: Weighted
weightPreference:
dynamicWeight: AvailableReplicas
preserveResourcesOnDeletion: false
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
namespace: test
- apiVersion: v1
kind: Service
namespace: test
schedulerName: default-scheduler步骤四:在舰队中创建FederatedHPA
FederatedHPA可以监控Pod的CPU、Memory、自定义指标和外部指标,下方示例使用num_requests_waiting和num_requests_running这两个自定义指标进行弹性伸缩。
将下方示例模板保存到federatedhpa.yaml,然后执行kubectl apply -f federatedhpa.yaml。
apiVersion: autoscaling.one.alibabacloud.com/v1alpha1
kind: FederatedHPA
metadata:
name: vllm-fhpa
namespace: test
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: qwen3
minReplicas: 1
maxReplicas: 10
behavior:
scaleDown:
stabilizationWindowSeconds: 30
scaleUp:
stabilizationWindowSeconds: 10
metrics:
- type: Pods
pods:
metric:
name: num_requests_waiting
target:
type: AverageValue
averageValue: ${waiting_size} # 根据显卡、模型最佳值有所不同
- type: Pods
pods:
metric:
name: num_requests_running
target:
type: AverageValue
averageValue: ${running_size} # 根据显卡、模型最佳值有所不同效果验证
-
验证优先级调度
执行
kubectl scale deployment -ntest qwen3 --replicas=2扩容工作负载。由于cluster1只有一个GPU实例,预计第二个副本被调度到low-priority组的cluster2集群。 -
验证FederatedHPA
-
参见管理南北流量使用多集群ALB进行服务暴露,然后获取Ingress地址。
-
替换下方命令中的ALB地址,然后执行命令,对服务进行压力测试。
hey -n 600 -c 60 -m POST -H "Content-Type: application/json" -d '{"messages": [{"role": "user", "content": "测试一下"}]}' http://alb-xxxxxx.cn-hangzhou.alb.aliyuncsslb.com:8000/v1/chat/completions预期观察到
num_requests_running大幅上升,副本数进行扩容:Current Metrics: Pods: Current: Average Value: 0 Metric: Name: num_requests_waiting Type: Pods Pods: Current: Average Value: 58 Metric: Name: num_requests_running Type: Pods Current Replicas: 2 Desired Replicas: 3
-
-
验证基于 库存感知 的智能调度
当推理应用扩容至三个副本后,由于当前cluster1和cluster2一共只有两个GPU实例,但新扩容的副本依然可以成功调度并拉起,说明舰队基于库存的智能调度成功生效。
常见问题
kubectl get fhpa后的REPLICAS一列为什么为空?
因为fhpa没有和对应的workload进行匹配,请检查工作负载名称、命名空间的配置。
kubectl get fhpa -o yaml后为什么报错?
condition报错the HPA was unable to compute the replica count: unable to get metric xxx。原因是FHPA无法成功获取到子集群对应workload的指标。
-
确认子集群都已安装ack-alibaba-cloud-metrics-adapter组件。
-
确认子集群ack-alibaba-cloud-metrics-adapter组件的参数配置正确,可以通过在子集群的看板查询指标,观察是否可以成功查询。
子集群查询指标为什么不可见?
执行如下命令观察指标是否成功注册,如果没有相关指标请检查Helm应用的组件参数配置是否正确。
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .