本文介紹時序資料相關名詞說明。
背景資訊
時間序列資料庫 TSDB :英文全稱為 Time Series Database,提供高效存取時序資料和統計分析功能的資料管理系統。
時序資料(Time Series Data):基於穩定頻率持續產生的一系列指標監測資料。例如,監測某城市的空氣品質時,每秒採集一個二氧化硫濃度的值而產生的一系列資料。
度量(Metric):監測資料的指標,例如風力和溫度。
標籤(Tag):度量(Metric)雖然指明了要監測的指標項,但沒有指明要針對什麼對象的該指標項進行監測。標籤(Tag)就是用於表明指標項監測針對的具體對象,屬於指定度量下的資料子類別。
一個標籤(Tag)由一個標籤鍵(TagKey)和一個對應的標籤值(TagValue)組成,例如“城市(TagKey)= 杭州(TagValue)”就是一個標籤(Tag)。更多標籤樣本:機房 = A 、IP = 172.220.XX.XX。
注意:當標籤鍵和標籤值都相同才算同一個標籤;標籤鍵相同,標籤值不同,則不是同一個標籤。
在監測資料的時候,指定度量是“氣溫”,標籤是“城市 = 杭州”,則監測的就是杭州市的氣溫。
標籤鍵(TagKey,Tagk):為指標項(Metric)監測指定的物件類型(會有對應的標籤值來定位該物件類型下的具體對象),例如國家、省份、城市、機房、IP 等。
標籤值(TagValue,Tagv):標籤鍵(TagKey)對應的值。例如,當標籤鍵(TagKey)是“國家”時,可指定標籤值(TagValue)為“中國”。
值(Value):度量對應的值,例如 15 級(風力)和 20 ℃(溫度)。
時間戳記(Timestamp):資料(度量值)產生的時間點。
資料點 (Data Point):針對監測對象的某項指標(由度量和標籤定義)按特定時間間隔(連續的時間戳記)採集的每個度量值就是一個資料點。“一個度量 + N 個標籤(N >= 1)+ 一個時間戳記 + 一個值”定義一個資料點。
時間序列(Time Series):針對某個監測對象的某項指標(由度量和標籤定義)的描述。“一個度量 + N 個標籤KV組合(N >= 1)”定義為一個時間序列,某個時間序列上產生的資料值的增加,不會導致時間序列的增加。 時間序列的示意圖如下:
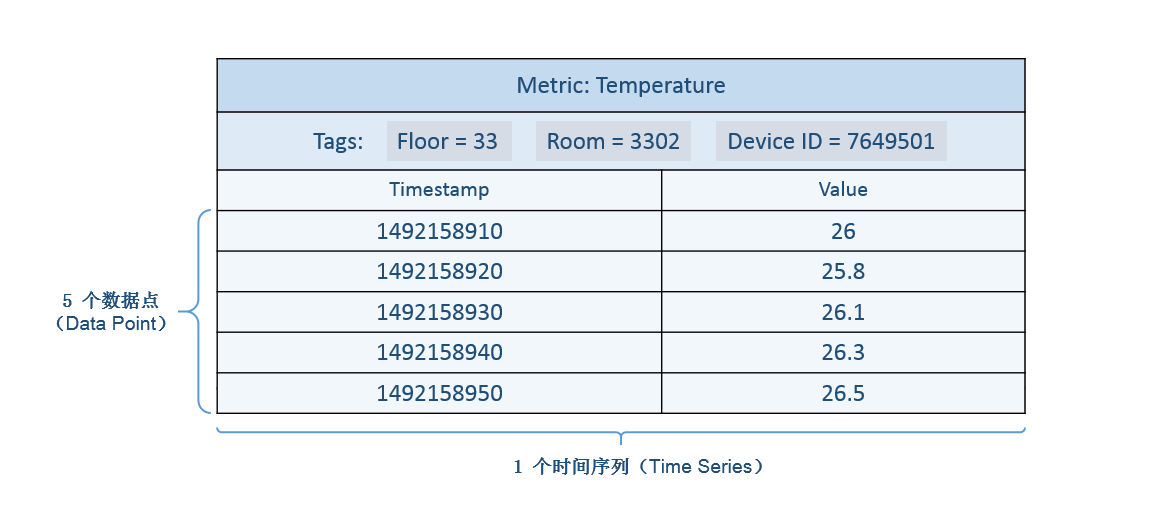
時間軸(Timeline):等同於時間序列的概念。
時間精度:時間軸資料的寫入時間精度——毫秒、秒、分鐘、小時或者其他穩定時間頻度。例如,每秒一個溫度資料的採集頻度,每 5 分鐘一個CPU使用率的採集頻度。
資料群組(Data Group):如果需要對比不同監測對象(由標籤定義)的同一指標(由度量定義)的資料,可以按標籤這些資料分成不同的資料群組。例如,將溫度指標資料按照不同城市進行分組查詢,操作類似於該 SQL 陳述式:
select avg(temperature),city from xx where xx group by city。彙總( Aggregation):當同一個度量(Metric)的查詢有多條時間軸產生(多個指標採集裝置),那麼為了將空間的多維資料展現為成同一條時間軸,需要進行合并計算,例如,當選定了某個城市某個城區的汙染指數時,通常將各個環境監測點的指標資料平均值作為最終地區的指標資料,這個計算過程就是空間彙總。
降採樣(Downsampling):當查詢的時間區間跨度較長而未經處理資料時間精度較細時,為了滿足業務需求的情境、提升查詢效率,就會降低資料的查詢展現精度,這就叫做降採樣,比如按秒採集一年的資料,按照天層級查詢展現。
資料時效(Data’s Validity Period):資料時效是設定的資料的實際有效期間,超過有效期間的資料會被自動釋放。