知識儲存(RAG)服務的系統架構、資料模型、Embedding 和檢索策略、Subspace 多租戶設計,以及配額限制和適用性評估,協助技術決策者判斷產品是否適合自身業務情境。
系統架構
知識儲存服務採用全託管的 Serverless 架構,使用者通過 API 與服務互動,底層資源由平台自動管理。資料流轉過程:
調用
AddDocuments介面,指定 OSS 檔案路徑(或通過 SDK 上傳本地檔案)。系統從 OSS 讀取檔案,自動完成文檔解析和智能切片。
對每個切片調用 Embedding 模型產生向量,寫入 Tablestore 的 Chunk 表。
自動構建向量索引和全文索引。
調用 Retrieve 介面時,系統執行混合檢索並返回相關Chunk結果。
所有資料(原始文檔、解析結果、向量資料)均儲存在使用者帳號的 OSS 和 Tablestore 內。服務本身不持有任何客戶資料。儲存與計算分離,獨立計費。
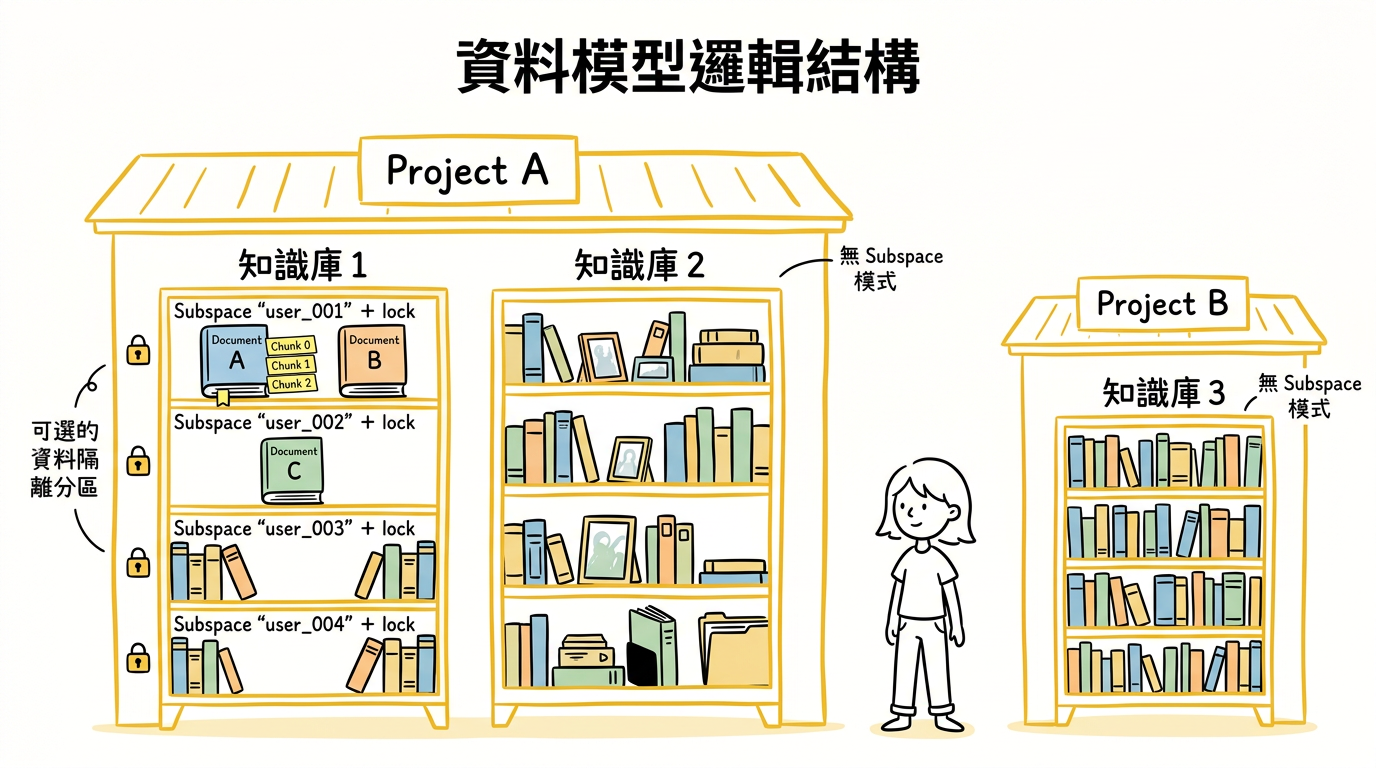
資料模型
知識庫的資料按四層實體組織:
實體 | 說明 |
KnowledgeBase | 知識庫,每個知識庫對應一張 Document 表、一張 Chunk 表和一張索引表。單個知識庫最大支援 1 億級文檔。 |
Document | 文檔記錄,關聯 OSS 檔案,記錄文檔狀態和中繼資料。 |
Chunk | 文檔切片,儲存向量資料和原文內容,是檢索的最小單元。 |
Index | 索引表,儲存向量資料,檢索增強內容,是檢索的最小單元。 |
系統自動在 Tablestore 中建立對應的資料表:
Document 表:使用
{知識庫名}_{知識庫 id}Chunk 表:使用
{知識庫名}_{知識庫 id}_chunkIndex 表:使用
{知識庫名}_{知識庫 id}_index
資料來源
知識庫的資料來源為阿里雲Object Storage Service。不論通過哪種方式上傳,文檔的未經處理資料都儲存在自己的 OSS Bucket 內。
知識庫需要對 OSS Bucket 進行讀寫操作:讀取原始文檔進行解析和切片,將解析過程的中間結果寫回 OSS。
支援以下三種方式將文檔匯入知識庫:
上傳本地檔案:指定本地檔案或目錄,SDK 自動上傳到 OSS 後添加到知識庫。如果是目錄,會遞迴遍曆所有檔案。
添加 OSS 檔案:檔案已在 OSS 上時,直接指定 OSS 路徑添加到知識庫,省去上傳步驟。
OSS 目錄大量匯入:指定 OSS 目錄路徑,系統自動遞迴掃描目錄下所有檔案。支援通過
inclusionFilters和exclusionFilters按檔案名稱模式過濾。
每種方式的詳細用法參見文件管理。
Embedding 配置
Embedding 配置決定了文檔切片如何被向量化,在建立知識庫時指定。
配置項 | 說明 |
| 模型提供方。 |
| 模型名稱。百鍊支援 |
| 向量維度。例如 |
| 僅 |
| 僅 |
不傳 embeddingConfiguration 時,系統預設使用百鍊 text-embedding-v4 模型(1024 維),適用於大多數情境。
Embedding 配置建立後不可修改。如需更換模型或維度,必須刪除並重建知識庫。建立前應充分評估模型選型。
選型建議:
通用中英文情境:推薦
text-embedding-v4(1024 維),在語義理解和效能之間取得較好平衡。已有自研或第三方 Embedding 服務:使用
custom模式接入,保持技術棧統一。維度越高語義表達越豐富,但儲存和計算成本也越高。1024 維是大多數情境的推薦選擇。
檢索策略概述
調用 Retrieve 介面時,檢索配置(retrievalConfiguration)按以下優先順序確定:
優先順序 | 來源 | 說明 |
1(最高) | Retrieve 介面參數 | 本次請求中傳入的配置,僅對當次生效 |
2 | 知識庫層級配置 | 建立知識庫時設定,可通過 UpdateKnowledgeBase 修改 |
3(最低) | 系統預設值 | 向量 + 全文混合檢索,WEIGHT 加權融合(向量 0.7 : 全文 0.3) |
檢索類型
類型 | 說明 | 適用情境 |
| 向量檢索,基於語義相似性 | 用自然語言描述需求,需要理解語義 |
| 全文檢索索引,基於關鍵詞匹配 | 輸入精確關鍵詞、專有名詞、編號 |
建議同時開啟兩種檢索類型,通過 Rerank 機制融合結果。
Rerank 排序策略
類型 | 說明 | 適用情境 |
RRF | 按排名倒數加權融合,無需額外模型調用 | 通用情境,延遲低 |
WEIGHT | 按比例加權向量與全文檢索索引得分 | 需要精細控制兩路檢索的貢獻比例 |
MODEL | 調用 Rerank 模型對候選結果重排序 | 對排序品質要求高,可接受額外延遲 |
檢索策略的詳細配置和調優方法參見檢索和排序。
Subspace 多租戶
Subspace 是知識庫內的資料隔離分區,適用於在同一知識庫內按使用者、部門或租戶隔離資料的情境。建立知識庫時設定 "subspace": true 開啟。
核心規則:
開啟 Subspace 後,所有文檔操作(添加/查詢/刪除/列出)和檢索都必須指定
subspace欄位,否則報錯。Retrieve 支援同時查詢多個 Subspace(傳入列表),最多 32 個。
Subspace 名稱最大長度 128 字元。
Subspace 開關建立後不可修改。
在企業環境中,同一部門的每位員工有各自的文檔。部門管理員建立一個知識庫並開啟 Subspace,為每位員工分配一個獨立的 Subspace(如 employee_zhangsan、employee_lisi)。每位員工的文檔互不可見,管理員統一管控知識庫配置。當需要跨員工檢索時,在 Retrieve 時傳入多個 Subspace 即可聯合檢索。
Subspace 與多知識庫的選擇
維度 | Subspace | 多知識庫 |
隔離粒度 | 同一知識庫內的邏輯分區 | 完全獨立的知識庫 |
Embedding 配置 | 共用同一配置 | 每個知識庫獨立配置 |
檢索範圍 | 可跨 Subspace 聯合檢索 | 只能在單個知識庫內檢索 |
管理成本 | 低(一個知識庫管理員所有租戶) | 高(需管理多個知識庫) |
適用情境 | 同質化資料的多租戶隔離 | 不同業務域、不同 Embedding 需求 |
適用性評估
推薦使用的情境:
為 LLM 應用構建 RAG 檢索能力
需要向量檢索 + 全文檢索索引的混合檢索
需要多租戶資料隔離
文檔規模從幾百到百億級
對資料安全有嚴格要求(資料不出自己的賬戶)
希望隨用隨付、零營運
需要評估的情境:
對文檔索引即時性要求極高(文檔上傳到可檢索是非同步過程,存在處理延遲)
需要自訂切片策略(當前為系統自動切片)
不推薦的情境:
純結構化資料查詢(建議使用Table Store寬表模型或關係型資料庫)
需要即時資料流式資料索引(建議直接使用Tablestore多元索引)